HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目。
Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统.。
HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.
关注博主不迷路,获取更多干货资源
1 架构
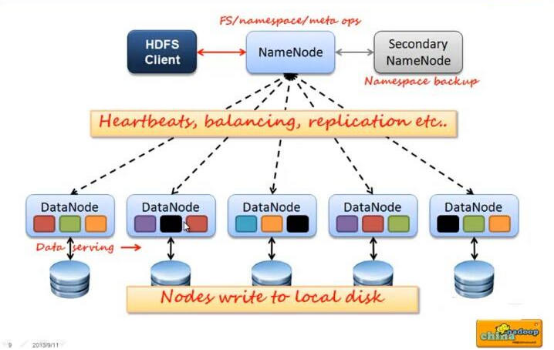
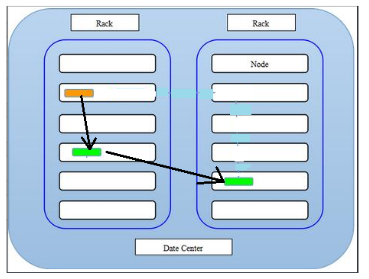
HDFS的四个基本组件:HDFS Client 、NameNode 、DataNode 和 Secondary NameNode 。
1、Client:就是客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
2、NameNode:就是 master,它是一个主管、管理者。
管理 HDFS 的名称空间Block )映射信息
3、DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
4、Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
辅助 NameNode,分担其工作量。
2 副本机制 2.1 文件副本机制
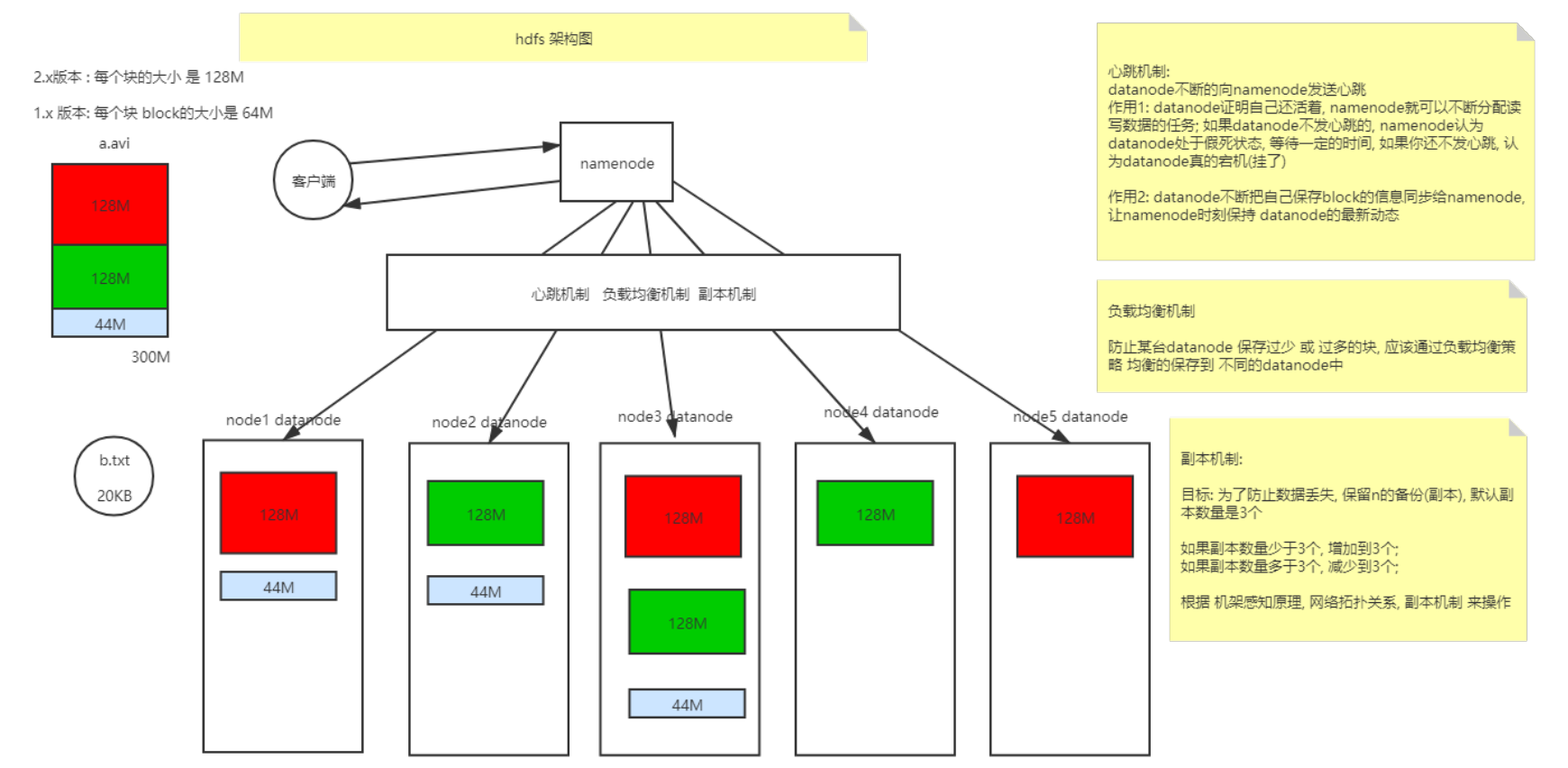
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block ,除了最后一个,所有的数据块都是同样大小的。
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
所有的文件都是以 block 块的方式存放在 HDFS 文件系统当中,作用如下
一个文件有可能大于集群中任意一个磁盘,引入块机制,可以很好的解决这个问题
使用块作为文件存储的逻辑单位可以简化存储子系统
块非常适合用于数据备份进而提供数据容错能力
副本优点是安全,缺点是占空间
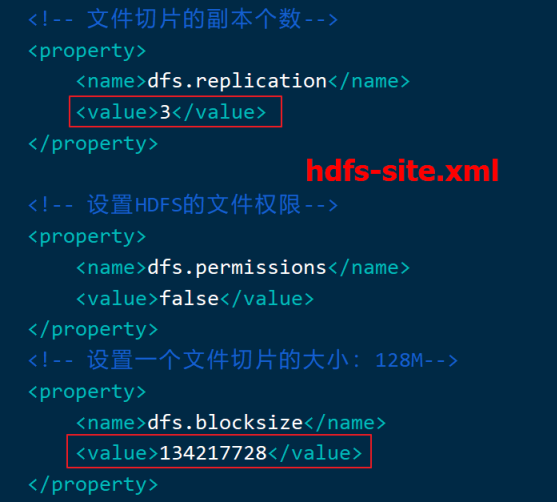
在 Hadoop1 当中, 文件的 block 块默认大小是 64M, hadoop2 当中, 文件的 block 块大小默认是 128M(134217728字节)。假设文件大小是100GB,从字节位置0开始,每128MB字节划分为一个block,依此类推,可以划分出很多的block。每个block就是128MB大小。
block块的大小可以通过 hdfs-site.xml 当中的配置文件进行指定,Hadoop默认的副本数为3,也就是每个block会存三份。
<property > <name > dfs.block.size</name > <value > 块大小以字节为单位</value > </property > \
注意当一个文件的大小不足128M时,比如文件大小为2M,那么这个文件也占用一个block,但是这个block实际只占2M的空间,所以从某种意义上来讲,block只是一个逻辑单位。
2.2 副本放置策略(机架感知)
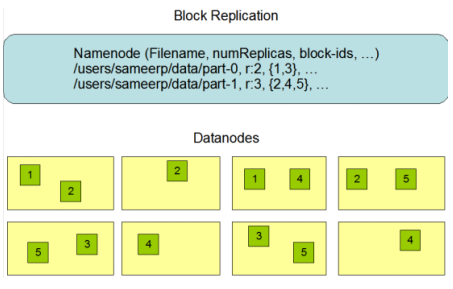
HDFS分布式文件系统的内部有一个副本存放策略,默认副本数为3,在这里以副本数=3为例:
第一副本:优先放置到离写入客户端最近的DataNode节点,如果上传节点就是DataNode,则直接上传到该节点,如果是集群外提交,则随机挑选一台磁盘不太慢,CPU不太忙的节点。
第二个副本:放置在与第一个同机架的不同机器中
第三个副本:放置在另一个机架中, 某一个服务器中
3 Shell命令行使用 官网手册
4 高级使用命令 4.1 HDFS的安全模式 安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。当集群启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整性。
假设我们设置的副本数(即参数dfs.replication)是3,那么在datanode上就应该有3个副本存在,假设只存在2个副本,那么比例就是2/3=0.666。hdfs默认的副本率0.999。我们的副本率0.666明显小于0.999,因此系统会自动的复制副本到其他dataNode,使得副本率不小于0.999。如果系统中有5个副本,超过我们设定的3个副本,那么系统也会删除多于的2个副本。
在安全模式状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求 。
安全模式操作命令
hdfs dfsadmin -safemode get
4.2 HDFS基准测试
实际生产环境当中,hadoop的环境搭建完成之后,第一件事情就是进行压力测试,测试我们的集群的读取和写入速度,测试我们的网络带宽是否足够等一些基准测试
8.2.1 测试写入速度
向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO中
hadoop jar /export/servers/hadoop-2 .7 .5 /share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2 .7 .5 .jar TestDFSIO -write -nrFiles 10 -fileSize 10 MB
完成之后查看写入速度结果
hadoop fs -text /benchmarks/ TestDFSIO/io_write/ part-00000
4.2.2 测试读取速度
测试hdfs的读取文件性能
hadoop jar /export/servers/hadoop-2 .7 .5 /share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2 .7 .5 .jar TestDFSIO -read -nrFiles 10 -fileSize 10 MB
查看读取果
hadoop fs -text /benchmarks/ TestDFSIO/io_read/ part-00000
4.2.3 清除测试数据 hadoop jar /export/servers/hadoop-2 .7 .5 /share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2 .7 .5 .jar TestDFSIO -clean
5 基本原理 5.1 NameNode
5.1.1 概念 NameNode在内存中保存着整个文件系统的名称空间和文件数据块的地址映射
整个HDFS可存储的文件数受限于NameNode的内存大小
1 NameNode元数据信息
文件名,文件目录结构,文件属性(生成时间,副本数,权限)每个文件的块列表。 以及列表中的块与块所在的DataNode之间的地址映射关系 在内存中加载文件系统中每个文件和每个数据块的引用关系(文件、block、datanode之间的映射信息) 数据会定期保存到本地磁盘(fsImage文件和edits文件)
2 NameNode文件操作
NameNode负责文件元数据的操作 DataNode负责处理文件内容的读写请求,数据流不经过NameNode,会询问它跟那个DataNode联系
3 DataNode副本
文件数据块到底存放到哪些DataNode上,是由NameNode决定的,NameNode根据全局情况做出放置副本的决定
4 NameNode心跳机制
全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包含该DataNode上所有数据块的列表) 若接受到心跳信息,NameNode认为DataNode工作正常,如果在10分钟后还接受到不到DataNode的心跳,那么NameNode认为DataNode已经宕机 ,这时候NN准备要把DN上的数据块进行重新的复制。 块的状态报告包含了一个DataNode上所有数据块的列表,blocks report 每个6小时发送一次.(默认6小时,去官网看就好了)
5.1.2 作用
1 NameNode是HDFS的核心。
2 NameNode也称为Master。
3 NameNode仅存储HDFS的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件。
4 NameNode不存储实际数据或数据集。数据本身实际存储在DataNodes中。
5 NameNode知道HDFS中任何给定文件的块列表及其位置。使用此信息NameNode知道如何从块中构建文件。
6 NameNode并不持久化存储每个文件中各个块所在的DataNode的位置信息,这些信息会在系统启动时从数据节点重建。
7 NameNode对于HDFS至关重要,当NameNode关闭时,HDFS / Hadoop集群无法访问。
8 NameNode是Hadoop集群中的单点故障。
9 NameNode所在机器通常会配置有大量内存(RAM)。
5.2 DataNode
1 Data Node以数据块的形式存储HDFS文件
2 DataNode也称为Slave。
3 NameNode和DataNode会保持不断通信。
4 DataNode启动时,它将自己发布到NameNode并汇报自己负责持有的块列表。
5 datanode 每隔6个小时, 会向namenode报告一次完整的块信息
6 当某个DataNode关闭时,它不会影响数据或群集的可用性。NameNode将安排由其他DataNode管理的块进行副本复制。
7 DataNode所在机器通常配置有大量的硬盘空间。因为实际数据存储在DataNode中。
8 DataNode会定期(dfs.heartbeat.interval配置项配置,默认是3秒)向NameNode发送心跳,如果NameNode长时间没有接受到DataNode发送的心跳, NameNode就会认为该DataNode失效。
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的heartbeat.recheck.interval大小为5分钟(单位毫秒),
所以namenode如果在10分钟+30秒后,仍然没有收到datanode的心跳,就认为datanode已经宕机,并标记为dead。
9 datanode block汇报时间间隔取参数dfs.blockreport.intervalMsec,参数未配置的话默认为6小时.
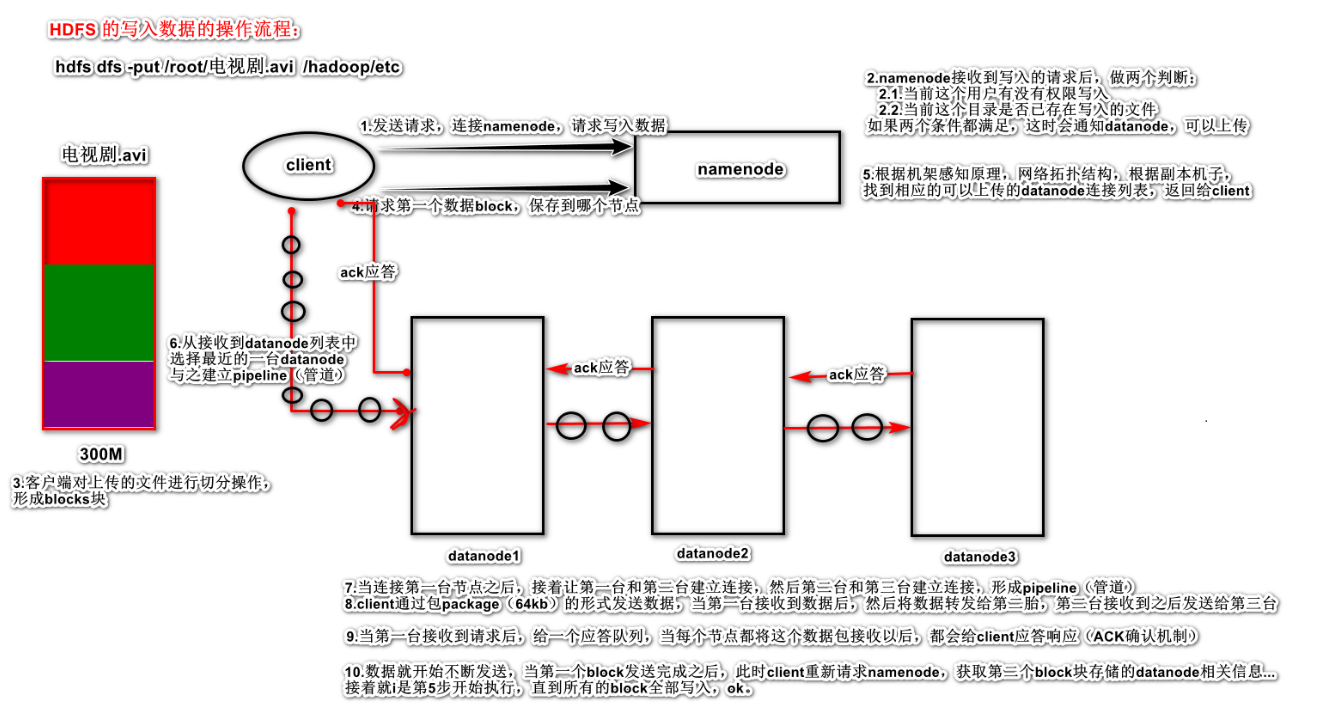
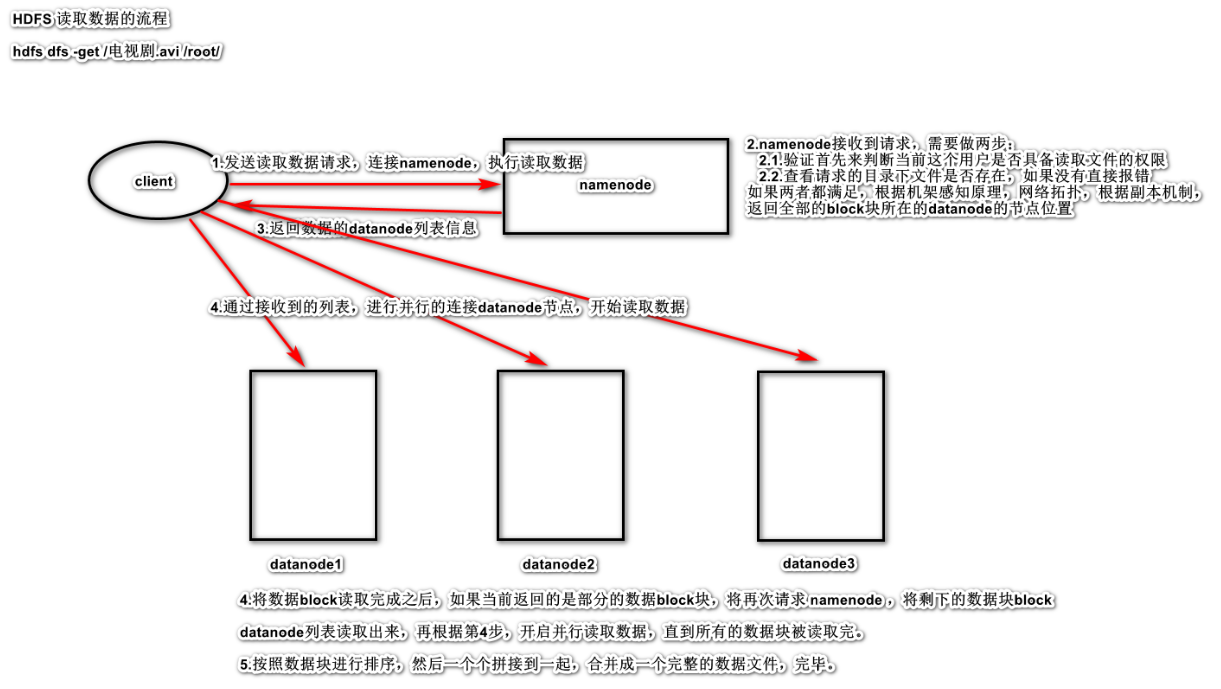
6 HDFS的读写工作机制 6.1 HDFS写数据流程
6.2 HDFS读数据流程
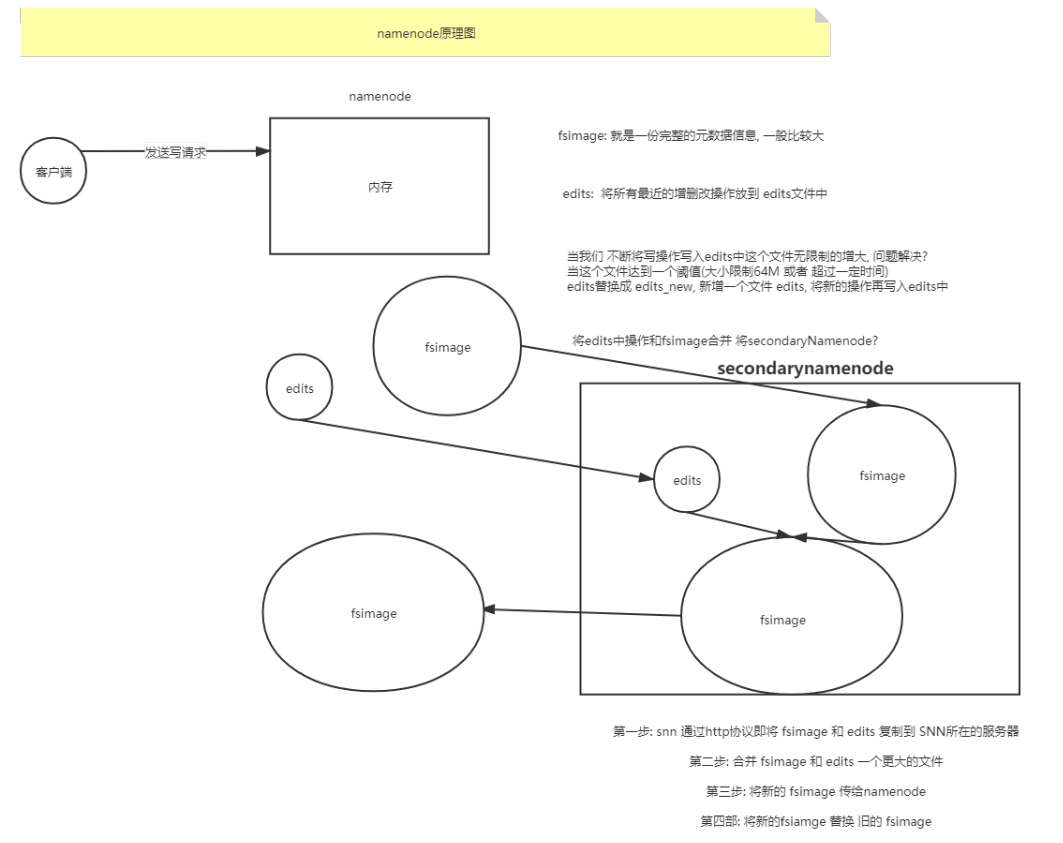
7 元数据辅助管理 当 Hadoop 的集群当中, NameNode的所有元数据信息都保存在了 FsImage 与 Eidts 文件当中, 这两个文件就记录了所有的数据的元数据信息, 元数据信息的保存目录配置在了 hdfs-site.xml 当中
<property>// /export/ serverss/hadoop2.7.5/ hadoopDatas/namenodeDatas</ value>// /export/ serverss/hadoop-2.7.5/ hadoopDatas/nn/ edits</value>
7.1 FsImage和Edits
edits
edits 是在NameNode启动时对整个文件系统的快照存放了客户端最近一段时间的操作日志
FsImage
fsimage是在NameNode启动时对整个文件系统的快照block 及 block 所在的 DataNode 的元数据信息.
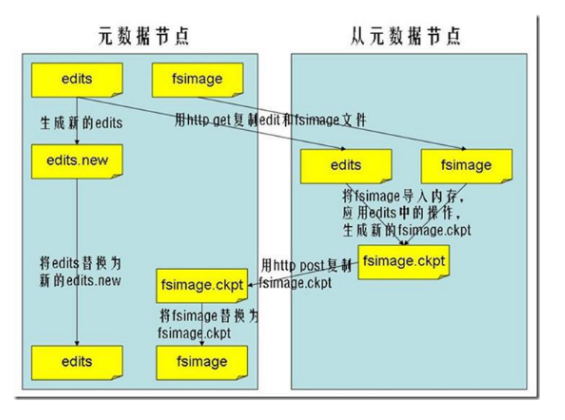
7.2 SecondaryNameNode的作用 SecondaryNameNode的作用是合并fsimage和edits文件。
7.3 SecondaryNameNode出现的原因 但是如果NameNode执行了很多操作的话,就会导致edits文件会很大,那么在下一次启动的过程中,就会导致NameNode的启动速度很慢,慢到几个小时也不是不可能,所以出现了SecondNameNode。
7.4 SecondaryNameNode唤醒合并的规则 SecondaryNameNode 会按照一定的规则被唤醒,进行fsimage和edits的合并,防止文件过大。checkpoint .period:单位秒,默认值3600 ,检查点的间隔时间,当距离上次检查点执行超过该时间后启动检查点,就是edits和fsimage的合并checkpoint .txns:事务操作次数,默认值1000000 ,当edits文件事务操作超过这个次数,就进行edits和fsimage的合并checkpoint .check .period:单位秒,默认值60 。1 分钟检查一次操作次数
[core-site.xml]
<property > <name > dfs.namenode.checkpoint.period</name > <value > 3600</value > </property > <property > <name > dfs.namenode.checkpoint.txns</name > <value > 1000000</value > </property > <property > <name > dfs.namenode.checkpoint.check.period</name > <value > 60</value > </property >
SecondaryNameNode一般处于休眠状态,当两个检查点满足一个,即唤醒SecondaryNameNode执行合并过程。
7.5 SecondaryNameNode工作过程 第一步:将hdfs更新记录写入一个新的文件——edits.new 。new 为edits。checkpoint 触发SecondaryNameNode进行工作,一直这样循环操作。
注意:SecondaryNameNode 在合并 edits 和 fsimage 时需要消耗的内存和 NameNode 差不多, 所以一般
SNN服务器内存一般要>=NameNode内存
7.6 FsImage中的文件信息查看 使用命令
cd /export/ server/hadoop-2.7.5/ hadoopDatas/namenodeDatas/ /export/ data//export/ data && ll
7.7 edits中的文件信息查看 使用命令
cd /export/ server/hadoop-2.7.5/ hadoopDatas/nn/ edits0000000000000000148 /export/ data//export/ data/0000000000000000148 -p XML -o myedit.xml
7.8 NameNode元数据恢复 当NameNode发生故障时,我们可以通过将SecondaryNameNode中数据拷贝到NameNode存储数据的目录的方式来恢复NameNode的数据
1 杀死NameNode进程
2 删除NameNode存储的数据
rm -rf /export/ server/hadoop-2.7.5/ hadoopDatas/namenodeDatas/ */export/ server/hadoop-2.7.5/ hadoopDatas/nn/ edits/*
3 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
cd /export/ server/hadoop-2.7.5/ hadoopDatas/namenodeDatas/ /export/ server/hadoop-2.7.5/ hadoopDatas/snn/ name/* ./
cd /export/ server/hadoop-2.7.5/ hadoopDatas/nn/ edits/export/ server/hadoop-2.7.5/ hadoopDatas/dfs/ snn/edits/ * ./
4 重新启动NameNode
hadoop-daemon.sh start namenode
8 API操作 8.1 配置Windows下Hadoop环境 在windows上做HDFS客户端应用开发,需要设置Hadoop环境,而且要求是windows平台编译的Hadoop
1 将已经编译好的Windows版本Hadoop解压到到一个没有中文没有空格的路径下面
链接:https:// pan.baidu.com/s/ 1 AxiSFAFNw88o7XVHxwebGA 6666
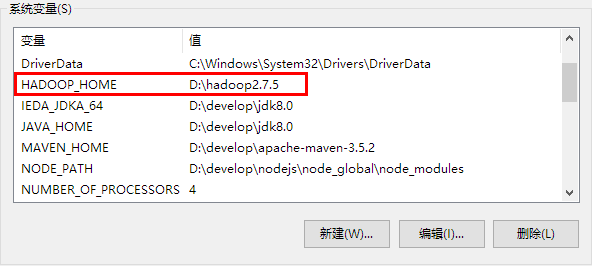
2 在windows上面配置hadoop的环境变量: HADOOP_HOME,并将%HADOOP_HOME%\bin添加到path中
3 把hadoop2.7.5文件夹中bin目录下的hadoop.dll文件放到系统盘: C:\Windows\System32 目录下
4 关闭windows重启
8.2 导入maven依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <dependencies > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > 2.7.5</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > 2.7.5</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-hdfs</artifactId > <version > 2.7.5</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-mapreduce-client-core</artifactId > <version > 2.7.5</version > </dependency > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.13</version > </dependency > </dependencies >
8.3 java操作hadoop
代码示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 package cn.itcast.hdfs;import org.apache.commons.io.IOUtils;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.*;import org.junit.Test;import java.io.IOException;import java.net.URI;import java.net.URISyntaxException;public class HdfsTest @Test public void test01 () throws IOException, URISyntaxException, InterruptedException new Configuration();new Configuration();"fs.defaultFS" , "hdfs://node1:8020" );new URI("hdfs://node1:8020" );"root" );@Test public void test02 () throws URISyntaxException, IOException, InterruptedException new URI("hdfs://node1:8020" ), new Configuration(), "root" );new Path("/user" ), true );while (listFiles.hasNext()) {@Test public void makeDir () throws URISyntaxException, IOException, InterruptedException new URI("hdfs://node1:8020" );new Configuration();"root" );new Path("/app/config" ));@Test public void makeFile () throws URISyntaxException, IOException, InterruptedException new URI("hdfs://node1:8020" );new Configuration();"root" );new Path("/app/config/c3p0.xml" ));"username=zhangsan\r\npassword=123456" .getBytes());@Test public void download () throws URISyntaxException, IOException, InterruptedException new URI("hdfs://node1:8020" );new Configuration();"root" );new Path("/app/config/c3p0.xml" ),new Path("F:\\_workspace_java\\hadoop_hdfs\\" ));@Test public void upload () throws URISyntaxException, IOException, InterruptedException new URI("hdfs://node1:8020" );new Configuration();"root" );new Path("F:\\_workspace_java\\hadoop_hdfs\\c3p0.xml" ),new Path("/" ));@Test public void mergeUpload () throws Exceptionnew URI("hdfs://node1:8020" );new Configuration();"root" );new Path("/merge.txt" ));new Configuration());new Path("F:\\_workspace_java\\hadoop_hdfs\\" ), false );while (localListFiles.hasNext()){@Test public void acl () throws Exceptionnew URI("hdfs://node1:8020" );new Configuration();"root" );new Path("/config2/core-site.xml" ),new Path("F:\\_workspace_java\\hadoop_hdfs\\core-site.xml" ));
9 拷贝、归档、快照、回收站 9.1 跨集群数据拷贝 DistCp(distributed copy)是一款被用于大型集群间/集群内的复制工具,该命令的内部原理是MapReduce。
cd /export/serverss/hadoop-2.7.5/
9.2 归档 archive
功能:对存储的小文件进行合并成为大文件。
目的:减少hdfs中小文件的数量。
如何进行小文件的归档操作呢:
如何查看归档文件的内容?
# 格式 # 示例.将config2 下的所有内容归档保存到 outputdir 文件夹下
如何查看归档文件的内容?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 1.直接在web browser 50070端口web查看 # 2.通过shell 命令进行查看 # 3.查看 har 文件中原有的文件列表 # 格式 # har://scheme-hostname:port/archivepath/fileinarchive # 4.查看 har 文件中某一个文件的内容 # 5.将归档的文件解压出来 # 5.1 创建一个文件夹 config3 # 5.2 将归档的文件解压到config3中
9.3 快照
快照就是snapshot (几乎不用)
hdfs 的快照什么场景上使用:
数据的备份
放置用户操作不当出现错误的操作
试验、测试
灾备恢复
hdfs 的快照是什么呢?
相当于对HDFS中的某一个文件夹进行 拍照,保持当前这个文件夹的一个状态信息(差异化快照)
差异化快照:拍完快照,快照文件只是对源文件的映射关系匹配。
dfs 的快照主要是针对文件夹。
如何进行快照的使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 hdfs dfsadmin -allowSnapshot /config3 hdfs dfs -createSnapshot /config3 backup_config3 _20200820 _1521 hdfs dfs -rm -r /config3 /core-site.xmlhdfs dfs -createSnapshot /config3 backup_config3 _20200820 _1523 hdfs dfs -ls /config3 /.snapshothdfs dfs renameSnapshot /config3 backup_config3 _20200820 _1523 backup_config3 _20200820 _1525 hdfs dfs -deleteSnapshot /config3 backup_config3 _20200820 _1521 hdfs dfsadmin -disallowSnapshot /config3 hdfs lsSnapshottableDir
总结:HDFS的快照功能虽然能够保证数据的安全性,但是一般不建议大家使用,快照功能会占用非常大的磁盘空间。HDFS本身是带3备份,不能放置数据丢失,这个时候就开启快照功能。
9.4 Trash回收站
Trash回收机制应用场景
放置用户手一抖彻底删除数据,当放置到Trash回收站里,还可以再次恢复数据。
Trash回收站原理
当用户默认删除数据的时候,并不是直接从物理磁盘删掉,而只是将文件移动到指定的文件夹下,如果一致不恢复数据(根据默认时间7天等相关参数),Trash数据将从磁盘中抹掉。(这个默认是关闭的,也就是fs.trash.interval=0)
<property > <name > fs.trash.interval</name > <value > 10080</value > <description > Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled.</description > </property > <property > <name > fs.trash.checkpoint.interval</name > <value > 0</value > <description > Number of minutes between trash checkpoints. Should be smaller or equal to fs.trash.interval. If zero, the value is set to the value of fs.trash.interval.</description > </property >
属性
说明
fs.trash.interval
分钟数,回收站文件的存活时间, 当超过这个分钟数后文件会被删除。如果为零,回收站功能将被禁用。
fs.trash.checkpoint.interval
检查点创建的时间间隔(单位为分钟)。其值应该小于或等于fs.trash.interval。如果为零,则将该值设置为fs.trash.interval的值。
/config3/y arn-site.xml /config3/y arn-site.xml
恢复数据
// node1:8020 /user/ root/.Trash/ 200820154000 /config3/y arn-site.xml /config3/
清空Trash回收站
总结,Trash回收机制为了保证操作数据,删除数据的时候,防止误删除,所以建议生产环境,在删除数据的时候,不要 skipTrash 跳过Trash回收机制。
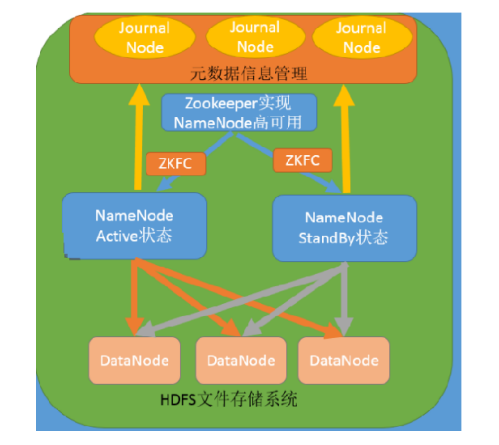
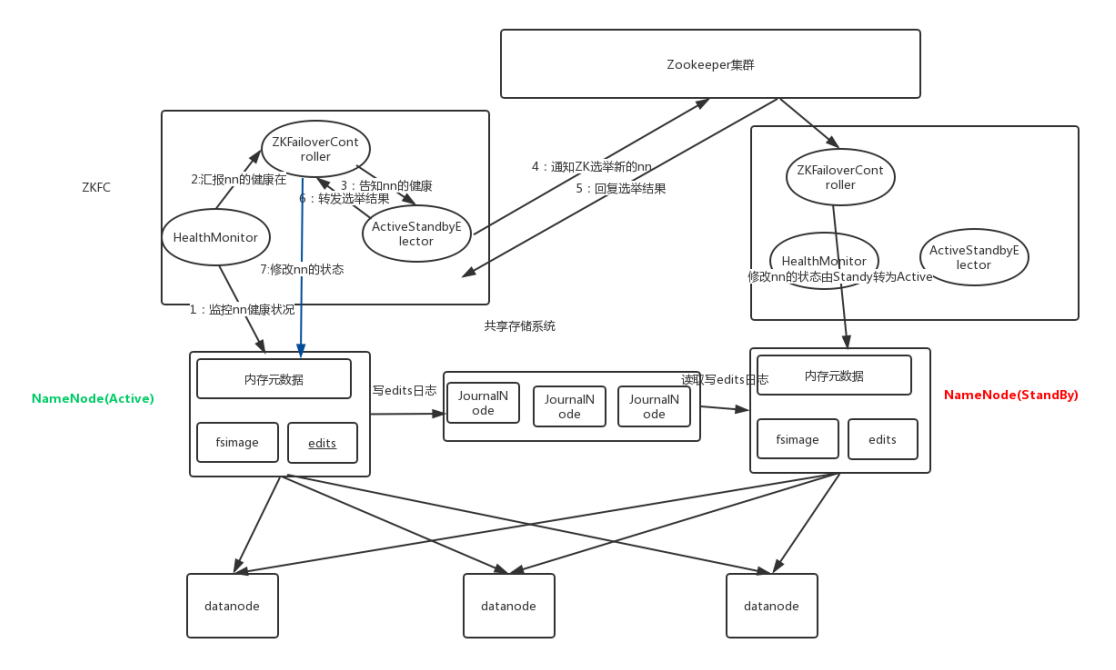
10 HDFS的高可用机制 10.1 介绍 在Hadoop 中,NameNode 所处的位置是非常重要的,整个HDFS文件系统的元数据信息都由NameNode 来管理,NameNode的可用性直接决定了Hadoop 的可用性,一旦NameNode进程不能工作了,就会影响整个集群的正常使用。
在典型的HA集群中,两台独立的机器被配置为NameNode。在工作集群中,NameNode机器中的一个处于Active状态,另一个处于Standby状态。Active NameNode负责群集中的所有客户端操作,而Standby充当从服务器。Standby机器保持足够的状态以提供快速故障切换(如果需要)。
10.2 组件介绍
ZKFailoverController
是基于Zookeeper的故障转移控制器,它负责控制NameNode的主备切换,ZKFailoverController会监测NameNode的健康状态,当发现Active NameNode出现异常时会通过Zookeeper进行一次新的选举,完成Active和Standby状态的切换
HealthMonitor
周期性调用NameNode的HAServiceProtocol RPC接口(monitorHealth 和 getServiceStatus),监控NameNode的健康状态并向ZKFailoverController反馈
ActiveStandbyElector
接收ZKFC的选举请求,通过Zookeeper自动完成主备选举,选举完成后回调ZKFailoverController的主备切换方法对NameNode进行Active和Standby状态的切换.
DataNode
NameNode包含了HDFS的元数据信息和数据块信息(blockmap),其中数据块信息通过DataNode主动向Active NameNode和Standby NameNode上报
共享存储系统
共享存储系统负责存储HDFS的元数据(EditsLog),Active NameNode(写入)和 Standby NameNode(读取)通过共享存储系统实现元数据同步,在主备切换过程中,新的Active NameNode必须确保元数据同步完成才能对外提供服务
10.3 高可用集群搭建 高可用HDFS集群搭建教程 。
11 Hadoop的联邦机制(Federation) 11.1 背景概述 单NameNode的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode进程使用的内存可能会达到上百G,NameNode成为了性能的瓶颈。因而提出了namenode水平扩展方案– Federation。
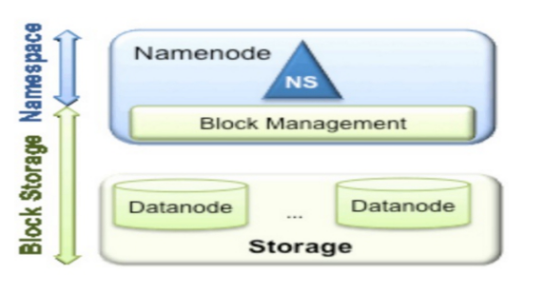
Federation中文意思为联邦,联盟,是NameNode的Federation,也就是会有多个NameNode。多个NameNode的情况意味着有多个namespace(命名空间),区别于HA模式下的多NameNode,它们是拥有着同一个namespace。既然说到了NameNode的命名空间的概念,这里就看一下现有的HDFS数据管理架构,如下图所示:
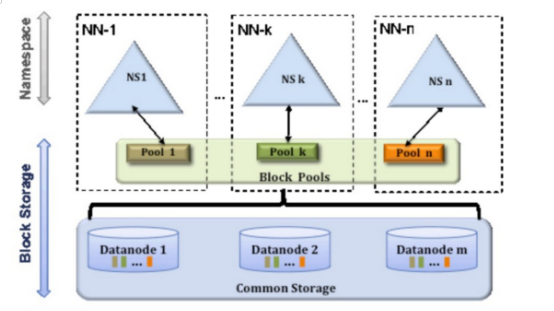
从上图中,我们可以很明显地看出现有的HDFS数据管理,数据存储2层分层的结构.也就是说,所有关于存储数据的信息和管理是放在NameNode这边,而真实数据的存储则是在各个DataNode下.而这些隶属于同一个NameNode所管理的数据都是在同一个命名空间下的.而一个namespace对应一个block pool。Block Pool是同一个namespace下的block的集合.当然这是我们最常见的单个namespace的情况,也就是一个NameNode管理集群中所有元数据信息的时候.如果我们遇到了之前提到的NameNode内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高NameNode的jvm大小绝对不是一个持久的办法.这时候就诞生了HDFS Federation的机制.
11.2 Federation架构设计
HDFS Federation是解决namenode内存瓶颈问题的水平横向扩展方案。
Federation意味着在集群中将会有多个namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
Federation一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集群中所有的DataNode的,它们还是在同一个集群内的。
概括起来:
多个NN共用一个集群里的存储资源,每个NN都可以单独对外提供服务。
11.3 HDFS Federation不足 HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。
关注博主不迷路