Flume 流式数据采集
Flume是一个分布式的、可靠的、可用的服务,用于高效地收集、聚合和移动大量的日志数据。
它有一个简单而灵活的基于流数据流的架构。
它具有鲁棒性和容错性,具有可调的可靠性机制和多种故障转移和恢复机制。
它使用一个简单的可扩展数据模型,允许在线分析应用程序。
关注博主不迷路,获取更多干货资源

1 Flume概述
1.1 Flume介绍
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的工具。基于流式架构,容错性强,也很灵活简单。
1.2 Flume核心流程
Flume 的核心是把数据从source数据源收集过来,再将收集到的数据送到指定的sink目的地/下沉地。为了保证输送的过程一定成功,在送到目的地sink之前,会先使用channel通道缓存数据,待数据真正到达目的地sink后,flume 再删除自己缓存的数据。
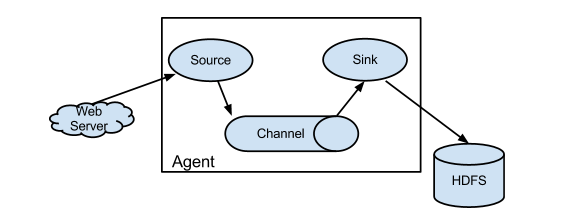
Flume 支持定制各类数据发送方,用于收集各类型数据;同时,Flume 支持定制各种数据接受方,用于最终存储数据。也就是支持各种数据源和目的地
一般的采集需求,通过对 flume 的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume 可以适用于大部分的日常数据采集场景。
1.3 Flume角色详解
Flume 系统中核心的角色是agent,agent 本身是一个 Java 进程,一般运行在日志收集节点。
1.3.1 Agent
每一个 Agent 相当于一个数据传递员,内部有三个组件:
Source、Channel、Sink
1.3.2 Source
数据源/采集源,用于跟数据源对接,以获取数据;同时Source会将收集到的数据流传输到Channel,常用的Source有:
1)
exec:可通过tail -f命令去tail一个文件,然后实时同步日志到sink2)
spooldir:可监听一个目录,同步目录中的新文件到sink,被同步完的文件可被立即删除或被打上标记。适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步。3)
taildir:可实时监控一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题4)
支持自定义
1.3.3 Channel
Channel是Agent 内部的数据传输通道,用于从 source 将数据传递到 sink;用于桥接Sources和Sinks,类似于一个队列/缓存。Channel分为:
1)
Memory Channel是基于内存的,速度快2)File Channel是基于文件的,速度慢,因为会将所有事件写到磁盘,但数据更安全
1.3.4 Sink
Sink是下沉地/目的地,采集数据的传送目的地,用于从Channel收集数据,将数据写到目标源,Sink分为:
1)可以是
HDFS、HBase、Kafka等2)也可以是下一个 FlumeAgent的Source
3)支持自定义
1.3.5 Event
在整个数据的传输的过程中,数据的流动用是Event表示从 source,流向 channel,再到 sink,是Flume 内部数据传输的最基本单元,本质就是一个字节数组。
Event 将传输的数据进行封装并可携带 headers(头信息)信息。
1.4 Flume复杂流程
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
Flume的一般流程是这样的:
source监控某个文件或数据流,数据源产生新的数据,拿到该数据后,将数据封装在一个Event中,并发送到channel后提交,channel队列先进先出,sink去channel队列中拉取数据,然后写入到HDFS/Kafka/或者其他的数据源,甚至是下一个Agent的Source。
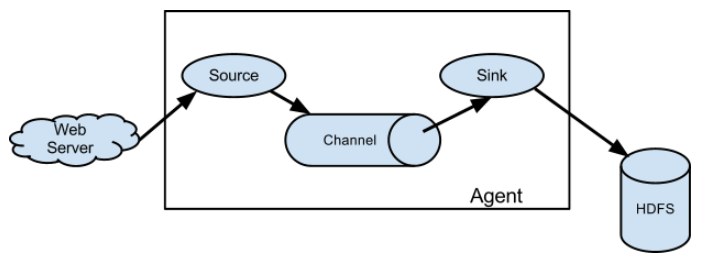
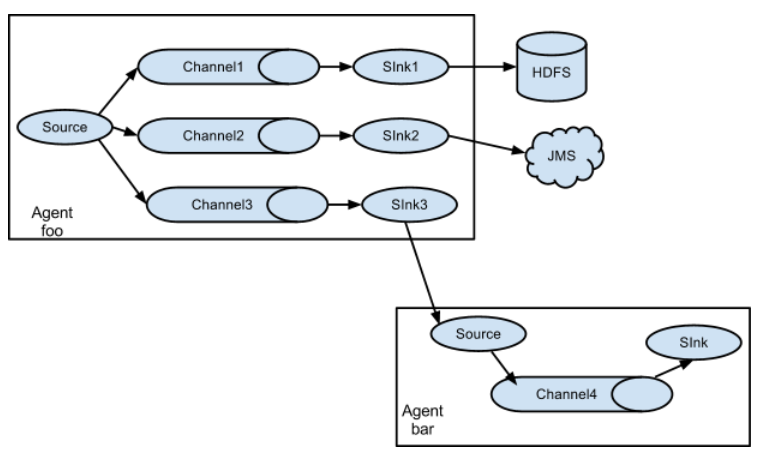
但是也支持如下的复杂流程:
串联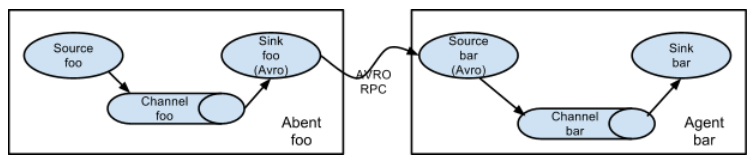
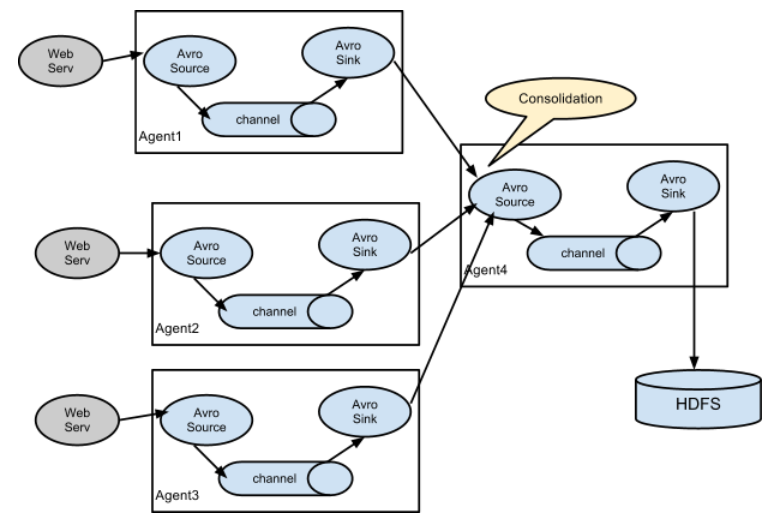
并联
多sink
2 Flume入门案例
2.1 模拟实时数据
1.准备一个数据生成脚本
1 | |
2.赋予执行权限
1 | |
3.执行
1 | |
4.测试
1 | |
2.2 编写配置文件
1 | |
1 | |
2.3 测试
1.启动ZK和Kafka并准备主题
启动
1 | |
查看主题
1 | |
创建主题
1 | |
启动消费者
1 | |
2.启动Flume
1 | |
3.执行数据模拟脚本
1 | |
关注博主不迷路
本博客所有文章除特别声明外,均为原创。版权归博主小马所有。任何团体、机构、媒体、网站、公众号及个人不得转载。如需转载,请联系博主(关于页面)。如其他团体、机构、媒体、网站、博客或个人未经博主允许擅自转载使用,请自负版权等法律责任!