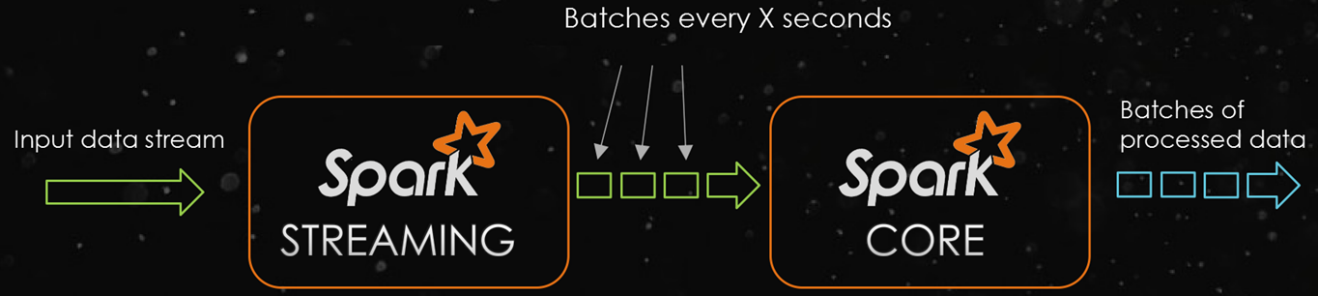
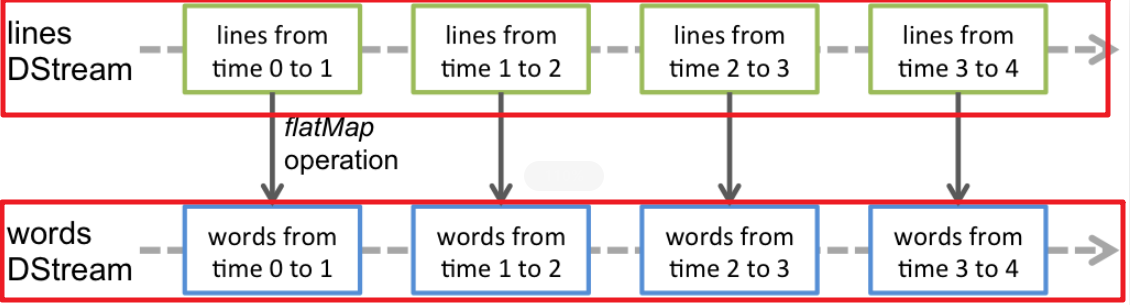
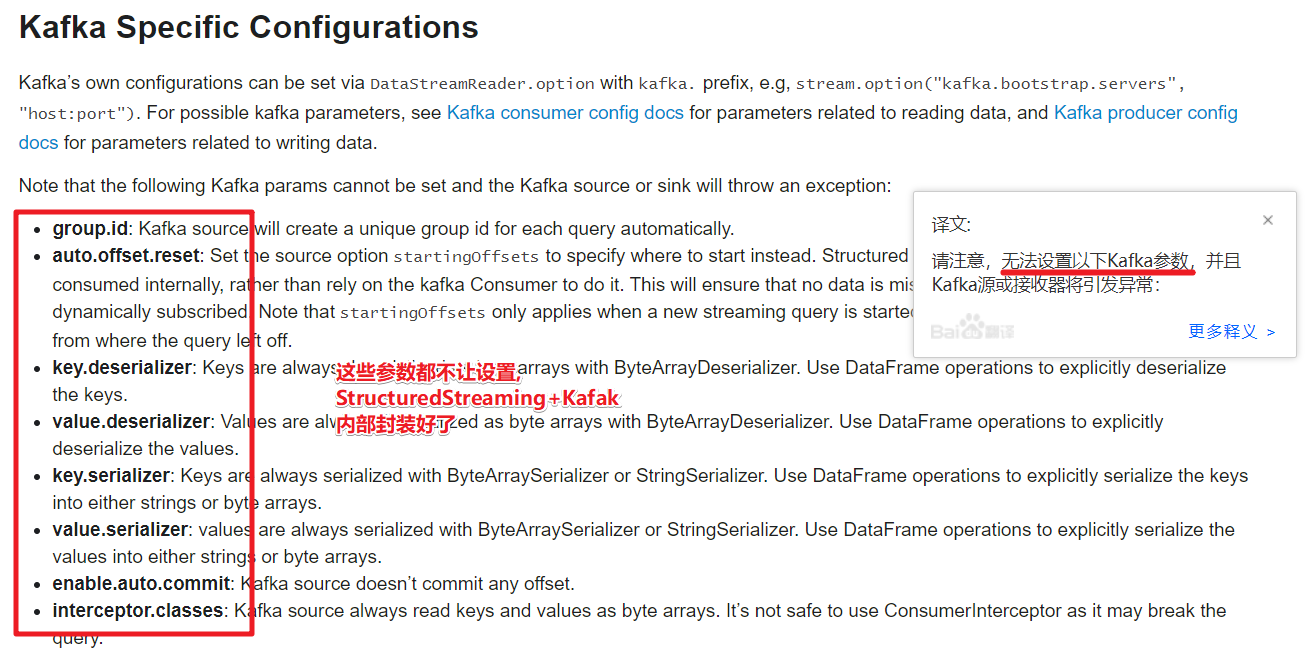
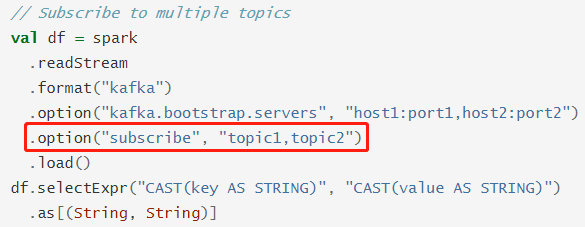
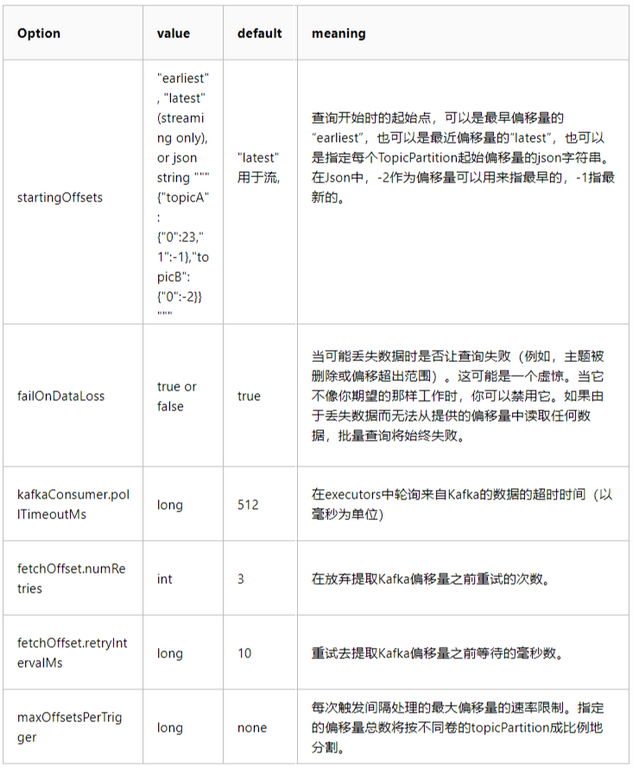
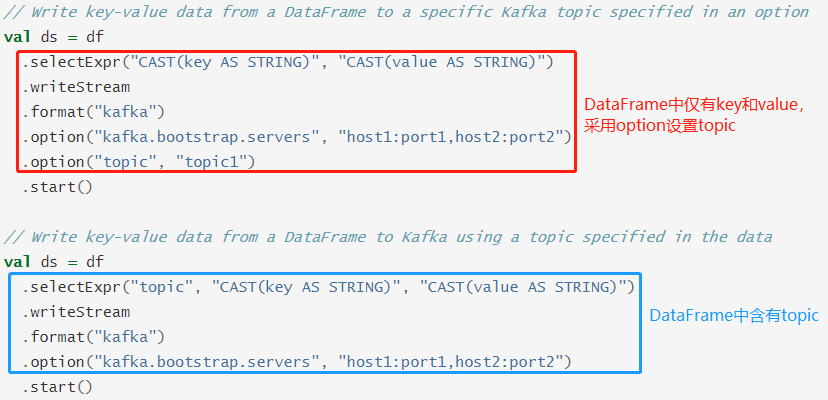
Apache Spark是一个用于大规模数据处理的统一分析引擎。
它提供了Java、Scala、Python和R的高级api,以及支持通用执行图的优化引擎。
它还支持一组丰富的高级工具,包括用于SQL和结构化数据处理的Spark SQL,用于机器学习的MLlib,用于图形处理的GraphX,以及用于增量计算和流处理的结构化流。
关注博主不迷路,获取更多干货资源
1 Spark概述
官网:http://spark.apache.org/ https://databricks.com/spark/about
Spark 是加州大学伯克利分校AMP实验室(Algorithms Machines and People Lab)开发的通用大数据出来框架。Spark生态栈也称为BDAS,是伯克利AMP实验室所开发的,力图在算法(Algorithms)、机器(Machines)和人(Person)三种之间通过大规模集成来展现大数据应用的一个开源平台。AMP实验室运用大数据、云计算等各种资源以及各种灵活的技术方案,对海量数据进行分析并转化为有用的信息,让人们更好地了解世界。
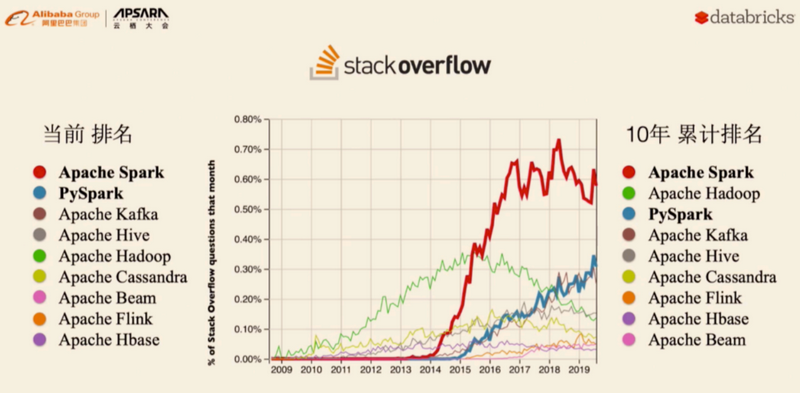
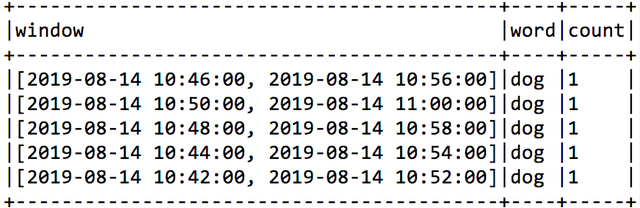
Spark的发展历史,经历过几大重要阶段,如下图所示:
Spark 是一种快速、通用、可扩展的大数据分析引擎,2009 年诞生于加州大学伯克利分校 AMPLab,2010 年开源, 2013年6月成为Apache孵化项目,2014年2月成为 Apache 顶级项目,用 Scala进行编写项目框架。
1.1 Spark是什么
Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
Spark 最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing,该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念,原文开头对其的解释是:
翻译过来就是:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着RDD进行。
1.2 Spark四大特点
Spark 使用Scala语言进行实现,它是一种面向对、函数式编程语言,能够像操作本地集合一样轻松的操作分布式数据集。Spark具有运行速度快、易用性好、通用性强和随处运行等特点。
1.2.1 速度快
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
其一、Spark处理数据时,可以将中间处理结果数据存储到内存中;
其二、Spark Job调度以DAG方式,并且每个任务Task执行以线程(Thread)方式,并不是像MapReduce以进程(Process)方式执行。
2014 年的如此Benchmark测试中,Spark 秒杀Hadoop,在使用十分之一计算资源的情况下,相同数据的排序上,Spark 比Map Reduce快3倍!
1.2.2 易于使用
Spark 的版本已经更新到 Spark 2.4.5(截止日期2020.05.01),支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语言。
1.2.3 通用性强
在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。其中,Spark SQL 提供了结构化的数据处理方式,Spark Streaming 主要针对流式处理任务(也是本书的重点),MLlib提供了很多有用的机器学习算法库,GraphX提供图形和图形并行化计算。
1.2.4 运行方式
Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark 2.3开始支持)上。
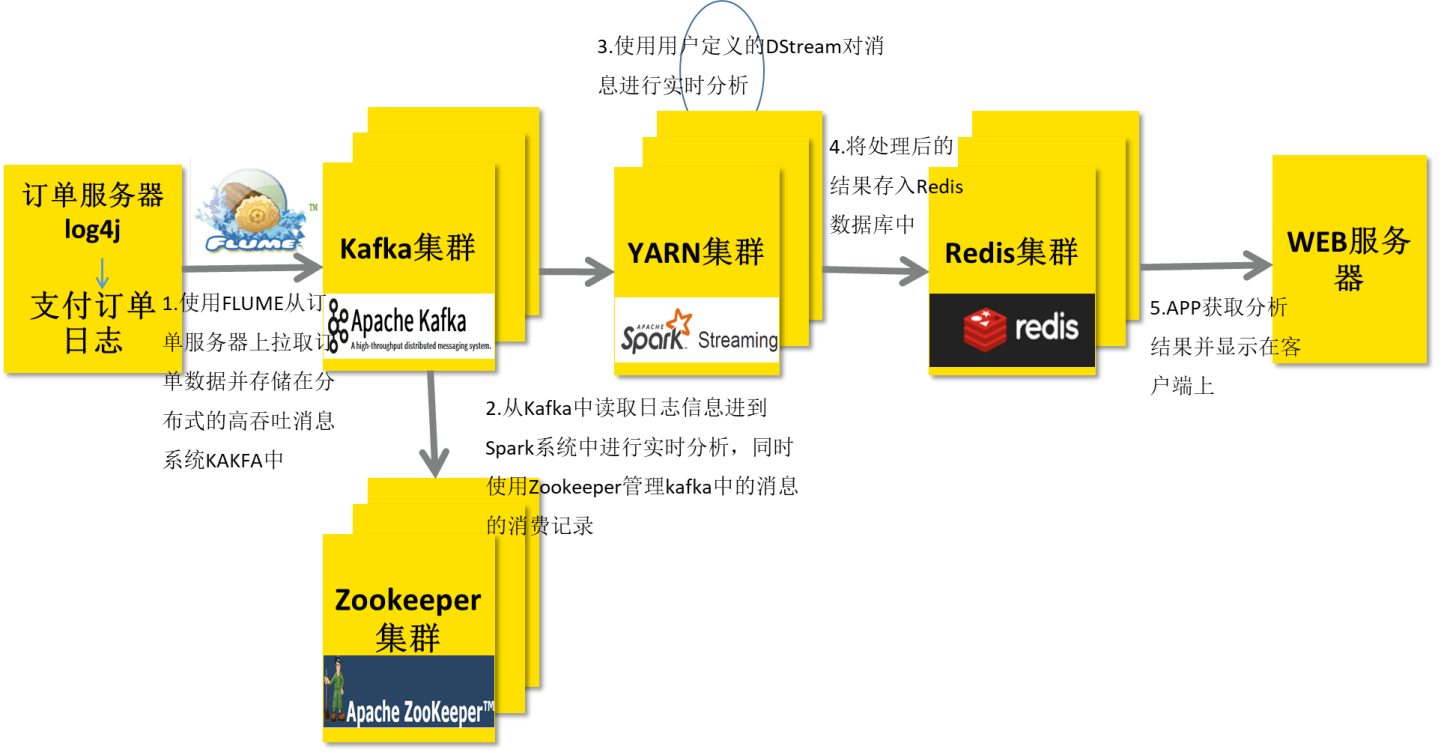
对于数据源而言,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
2 Spark环境搭建 2.1 Local 2.1.1 安装包下载
目前Spark最新稳定版本:2.4.x系列,官方推荐使用的版本,也是目前企业中使用较多版本,网址:
https://github.com/apache/spark/releases http://spark.apache.org/downloads.html http://archive.apache.org/dist/spark/spark-2.4.5/
Spark 2.4.x依赖其他语言版本如下,其中既支持Scala 2.11,也支持Scala 2.12,推荐使用2.11。
2.1.2 Spark安装
将spark安装包【spark-2.4.5-bin-hadoop2.7.tgz】解压至【/export/servers/】目录:
tar -zxvf spark-2 .4 .5 -bin-hadoop2 .7 .tgzln -s /export/servers//spark-2 .4 .5 -bin-hadoop2 .7 /export/servers//sparkchown -R root /export/servers//spark-2 .4 .5 -bin-hadoop2 .7 chgrp -R root /export/servers//spark-2 .4 .5 -bin-hadoop2 .7
其中各个目录含义如下:
bin 可执行脚本jars 依赖 jar 包sbin 集群管理命令
2.1.3 运行spark-shell
开箱即用
直接启动bin目录下的spark-shell:
## 进入Spark安装目录export /servers2 ]
spark-shell说明
1.直接使用./spark-shell
表示使用local 模式启动,在本机启动一个SparkSubmit进程
2.还可指定参数 –master,如:
spark-shell –master local[N] 表示在本地模拟N个线程来运行当前任务
3.不携带参数默认就是
spark-shell –master local[*]
4.后续还可以使用–master指定集群地址,表示把任务提交到集群上运行,如
./spark-shell –master spark://node01:7077,node02:7077
5.退出spark-shell
使用 :quit
本地模式启动spark-shell:
其中
创建SparkContext实例对象:scSparkSession实例对象:spark启动应用监控页面端口号:4040
2.1.4 初体验-读取本地文件
1:准备数据
vim /root/words .txtme you her
2:执行下面代码
val textFile = sc.textFile("file:///root/words.txt" ) val counts = textFile.flatMap(_ .split (" " ) ).map((_,1 )).reduceByKey(_ + _ )
2.1.5 初体验-读取HDFS文件
准备数据
上传文件到hdfs
hadoop fs -put /root/ words.txt /wordcount/i nput/words.txt
目录如果不存在可以创建
hadoop fs -mkdir -p /wordcount/i nput
结束后可以删除测试文件夹
hadoop fs -rm -r /wordcount
val textFile = sc.textFile("hdfs://node1:8020/wordcount/input/words.txt" ) val counts = textFile.flatMap(_ .split (" " ) ).map((_,1 )).reduceByKey(_ + _ ) AsTextFile("hdfs://node1:8020/wordcount/output" )
查看文件内容
hadoop fs -text /wordcount/ output/part*
2.1.6 监控页面
每个Spark Application应用运行时,启动WEB UI监控页面,默认端口号为4040,可以使用浏览器打开页面,
http://node1:4040/jobs/
2.2 Standalone
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
2.2.1 Standalone架构
Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。
http://spark.apache.org/docs/latest/cluster-overview.html
Spark Standalone集群,类似Hadoop YARN,管理集群资源和调度资源:
主节点Master:
管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
从节点Workers:
管理每个机器的资源,分配对应的资源来运行Task;
历史服务器HistoryServer:
Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
2.2.2 集群规划
Standalone集群安装服务规划与资源配置:
node01:master slave /worker slave /worker
官方文档:http://spark.apache.org/docs/2.4.5/spark-standalone.html
2.2.3 修改配置
修改slaves
## 进入配置目录export /servers
修改spark-env.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ## 进入配置目录export /serversexport /serversexport /serversexport SPARK_MASTER_HOST=node1export SPARK_MASTER_PORT=7077 8080 1 1 g"-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
增加如下内容:
注意:sparklog需要手动创建
hadoop fs -mkdir -p /sparklog
配置Spark应用保存sparklog
/export/ servers// spark/conf// node1:8020 /sparklog/ 18080
设置日志级别
## 进入目录export /servers
2.2.4 分发到其他服务器
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
cd /export/servers//scp -r spark-2 .4 .5 -bin-hadoop2 .7 root@node2 :$PWDscp -r spark-2 .4 .5 -bin-hadoop2 .7 root@node3 :$PWDln -s /export/servers//spark-2 .4 .5 -bin-hadoop2 .7 /export/servers//spark
2.2.5 启动服务进程
集群启动和停止
在主节点上启动spark集群/export/ servers// spark/sbin/ start-all.sh/export/ servers// spark/sbin/ stop-all.sh
单独启动和停止
在 master 安装节点上启动和停止 master :start -master .shstop -master .shMaster 所在节点上启动和停止worker (work指的是slaves 配置文件中的主机名)start -slaves.shstop -slaves.sh
WEB UI页面
http://node1:8080/
历史服务器HistoryServer:
/export/ servers// spark/sbin/ start-history-server.sh
WEB UI页面地址:
http://node1:18080/
2.2.6 测试 /export/ servers// spark/bin/ spark-shell --master spark:// node1:7077
运行程序
sc.textFile("hdfs://node1:8020/wordcount/input/words.txt" ) Map(_ .split (" " ) ).map((_, 1 )).reduceByKey(_ + _ ) AsTextFile("hdfs://node1:8020/wordcount/output2" )
hadoop fs -text /wordcount/ output2/part*
注意
集群模式下程序是在集群上运行的,不要直接读取本地文件,应该读取hdfs上的
SparkContext web UI
http://node1:4040/jobs/
查看Master主节点WEB UI界面:
http://node1:8080/
查看历史服务器
http://node1:18080/
2.2.7 Spark 应用架构-了解 2.2.7.1 Driver和Executors
从图中可以看到Spark Application运行到集群上时,由两部分组成:Driver Program和Executors。
第一、Driver Program
相当于AppMaster,整个应用管理者,负责应用中所有Job的调度执行;
第二、Executors
相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,一个Task运行需要1 Core CPU,所有可以认为Executor中线程数就等于CPU Core核数;
Driver Program是用户编写的数据处理逻辑,这个逻辑中包含用户创建的SparkContext。SparkContext 是用户逻辑与Spark集群主要的交互接口,它会和Cluster Manager交互,包括向它申请计算资源等。 Cluster Manager负责集群的资源管理和调度,现在支持Standalone、Apache Mesos和Hadoop的 YARN。Worker Node是集群中可以执行计算任务的节点。 Executor是在一个Worker Node上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。Task 是被送到某个Executor上的计算单元,每个应用都有各自独立的 Executor,计算最终在计算节点的 Executor中执行。
用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
1)、用户程序创建 SparkContext 时,新创建的 SparkContext 实例会连接到 ClusterManager。 Cluster Manager 会根据用户提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动 Executor。
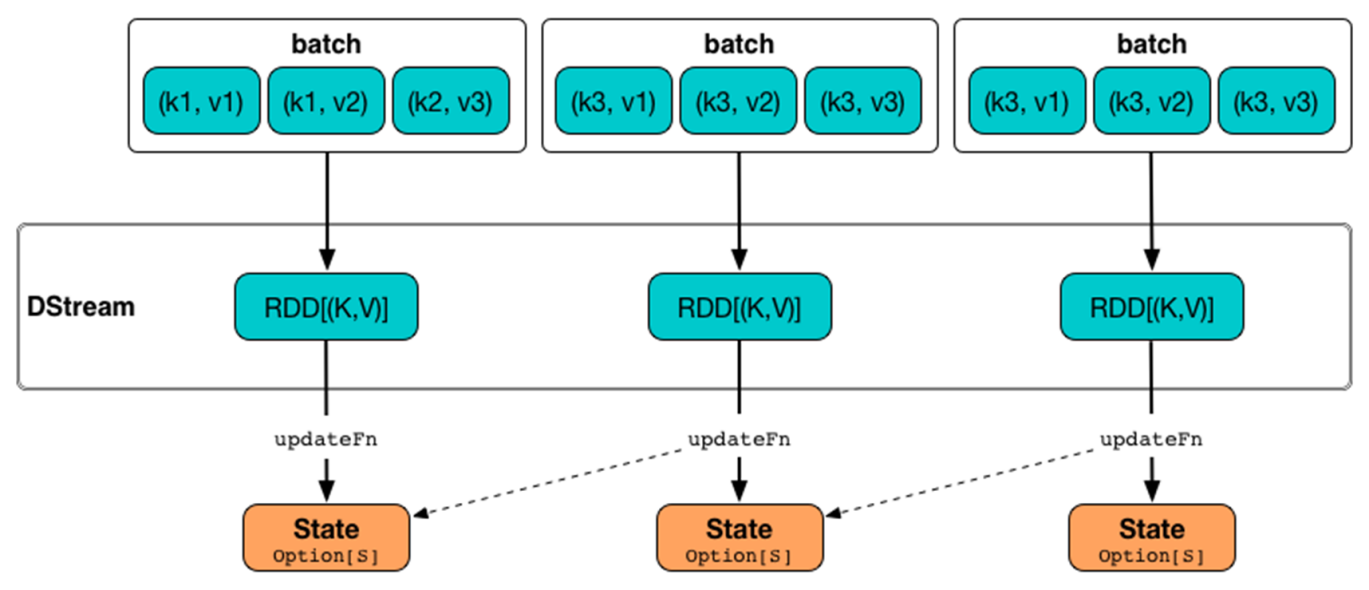
2.2.7.2 Job、DAG和Stage
还可以发现在一个Spark Application中,包含多个Job,每个Job有多个Stage组成,每个Job执行按照DAG图进行的。
其中每个Stage中包含多个Task任务,每个Task以线程Thread方式执行,需要1Core CPU。
可以看到Spark为应用程序提供了非常详尽的统计页面,每个应用的Job和Stage等信息都可以在这里查看到。通过观察应用详情页的各个信息,对进一步优化程序,调整瓶颈有着重要作用,后期综合项目案例详细讲解。
Spark Application程序运行时三个核心概念:Job、Stage、Task,说明如下:
Task:被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一般来说有多少个 Paritition(物理层面的概念,即分支可以理解为将数据划分成不同部分并行处理),就会有多少个 Task,每个 Task 只会处理单一分支上的数据。Job:由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect,后面进一步说明),会生成一个 Job。Stage:Job 的组成单位,一个 Job 会切分成多个 Stage,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多个 Task 的集合,类似 map 和 reduce stage。
2.3 Standalone HA 2.3.1 高可用HA
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。
如何解决这个单点故障的问题,Spark提供了两种方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)–只能用于开发或测试环境。
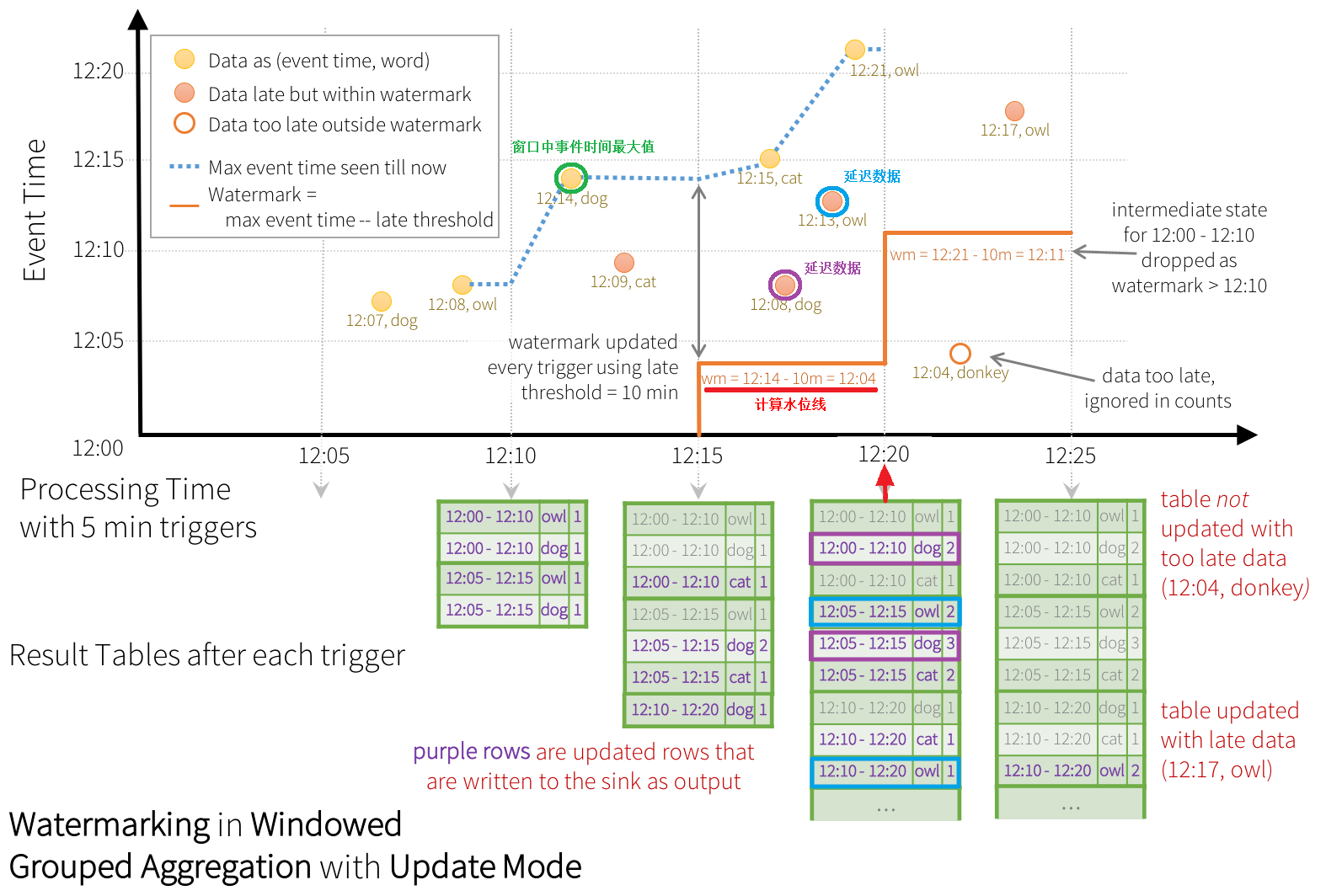
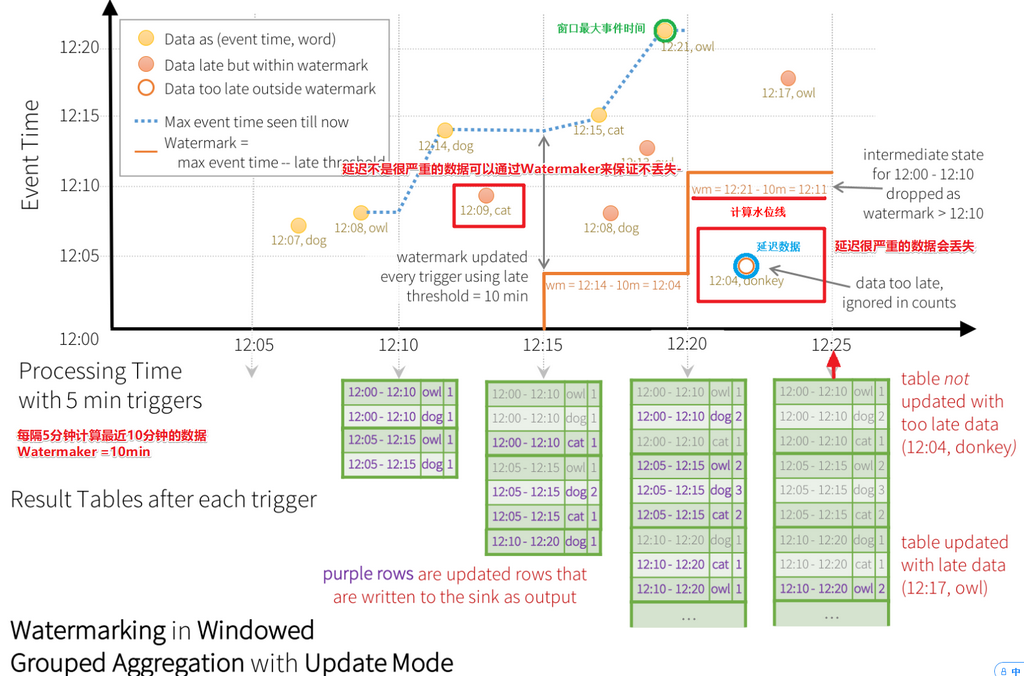
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
2.3.2 基于Zookeeper实现HA
官方文档:http://spark.apache.org/docs/2.4.5/spark-standalone.html#standby-masters-with-zookeeper
先停止Sprak集群
/export/ servers// spark/sbin/ stop-all.sh
在node01上配置:
vim /export/ servers// spark/conf/ spark-env.sh"-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
将spark-env.sh分发集群
cd /export/serversenv .sh root@node2:$PWDenv .sh root@node3:$PWD
启动集群服务
/export/ servers// spark/sbin/ start-all.sh/export/ servers// spark/sbin/ start-master.sh
查看WebUI
http://node1:8080/ http://node2:8080/
2.3.3 测试运行
测试主备切换
1.在node1上使用jps查看master进程id
如启动spark-shell,需要指定多个master地址
/export/ servers// spark/bin/ spark-shell --master spark:// node01:7077 ,node02:7077
sc.textFile("hdfs://node1:8020/wordcount/input/words.txt" ) Map(_ .split (" " ) ).map((_, 1 )).reduceByKey(_ + _ ) AsTextFile("hdfs://node1:8020/wordcount/output3" )
停止集群
/export/ servers// spark/sbin/ stop-all.sh
2.4 Spark on Yarn
Yarn是一个成熟稳定且强大的资源管理和任务调度的大数据框架,在企业中市场占有率很高,意味着有很多公司都在用Yarn,将公司的资源交给Yarn做统一的管理!并支持对任务做多种模式的调度,如FIFO/Capacity/Fair等多种调度模式!
所以很多计算框架,都主动支持将计算任务放在Yarn上运行,如Spark/Flink
企业中也都是将Spark Application提交运行在YANR上,文档: http://spark.apache.org/docs/2.4.5/running-on-yarn.html#launching-spark-on-yarn
2.4.1 注意事项
Spark On Yarn的本质?
将Spark任务的class字节码文件打成jar包,提交到Yarn的JVM中去运行
Spark On Yarn需要啥?
1.需要Yarn集群:已经安装了
2.需要提交工具:spark-submit命令–在spark/bin目录
3.需要被提交的jar:Spark任务的jar包(如spark/example/jars中有示例程序,或我们后续自己开发的Spark任务)
4.需要其他依赖jar:Yarn的JVM运行Spark的字节码需要Spark的jar包支持!Spark安装目录中有jar包,在spark/jars/中
总结:SparkOnYarn
不需要搭建Spark集群
只需要:Yarn+单机版Spark(里面有提交命令,依赖jar,示例jar)
当然还要一些配置
2.4.2 修改配置
当Spark Application运行到YARN上时,在提交应用时指定master为yarn即可,同时需要告知YARN集群配置信息(比如ResourceManager地址信息),此外需要监控Spark Application,配置历史服务器相关属性。
2.4.2.1 修改spark-env.sh cd /export/ servers// spark/conf/export/ servers// spark/conf/ spark-env.sh
/export/ servers// hadoop-2.7 .5 /etc/ hadoop/export/ servers// hadoop-2.7 .5 /etc/ hadoop
同步
cd /export/serversenv .sh root@node2:$PWDenv .sh root@node3:$PWD
2.4.2.2 整合历史服务器并关闭资源检查
整合Yarn历史服务器并关闭资源检查
在【$HADOOP_HOME/etc/hadoop/yarn-site.xml】配置文件中,指定MRHistoryServer地址信息,添加如下内容,
在node1上修改
cd /export/ servers// hadoop-2.7 .5 /etc/ hadoop/export/ servers// hadoop-2.7 .5 /etc/ hadoop/yarn-site.xml
添加内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 <configuration > <property > <name > yarn.resourcemanager.hostname</name > <value > node1</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 20480</value > </property > <property > <name > yarn.scheduler.minimum-allocation-mb</name > <value > 2048</value > </property > <property > <name > yarn.nodemanager.vmem-pmem-ratio</name > <value > 2.1</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property > <property > <name > yarn.log.server.url</name > <value > http://node1:19888/jobhistory/logs</value > </property > <property > <name > yarn.nodemanager.pmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property > </configuration >
由于使用虚拟机运行服务,默认情况下YARN检查机器内存,当内存不足时,提交的应用无法运行,可以设置不检查资源
同步
cd /export/ servers// hadoop-2.7 .5 /etc/ hadoop$PWD $PWD
配置spark历史服务器–前面已经配置过
在node1上修改
cd /export/ servers// spark/conf/export/ servers// spark/conf/ spark-defaults.conf
添加内容
spark.eventLog .enabled true.eventLog .dir hdfs:.eventLog .compress true.yarn .historyServer .address node1:18080
同步
cd /export/ servers// spark/conf$PWD $PWD
2.4.2.3 配置依赖Spark Jar包
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。
/spark/ jars//export/ servers// spark/jars/ * /spark/ jars/
在spark-defaults.conf中增加Spark相关jar包位置信息:
在node1上操作
vim /export/ servers// spark/conf/ spark-defaults.conf
添加内容
spark.yarn.jars hdfs:// node1:8020 /spark/ jars/*
同步
cd /export/ servers// spark/conf$PWD $PWD
2.4.3 启动服务
Spark Application运行在YARN上时,上述配置完成
启动服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
/export/ servers// spark/sbin/ start-history-server.sh
2.4.4 Spark On Yarn两种模式 2.4.4.1 引入
当一个MR应用提交运行到Hadoop YARN上时
包含两个部分:应用管理者AppMaster和运行应用进程Process(如MapReduce程序MapTask和ReduceTask任务),如下图所示:
当一个Spark应用提交运行在集群上时,
应用架构有两部分组成:Driver Program(资源申请和调度Job执行)和Executors(运行Job中Task任务和缓存数据),都是JVM Process进程:
而Driver程序运行的位置可以通过--deploy-mode 来指定, 值可以是:
1.client:表示Driver运行在提交应用的Client上(默认)
2.cluster:表示Driver运行在集群中(Standalone:Worker,YARN:NodeManager)
补充Driver是什么:
The process running the main() function of the application and creating the SparkContext
运行应用程序的main()函数并创建SparkContext的进程
注意
cluster和client模式最最本质的区别是:Driver程序运行在哪里。
企业实际生产环境中使用cluster
2.4.4.2 client模式
DeployMode为Client,表示应用Driver Program运行在提交应用Client主机上,示意图如下:
运行圆周率PI程序,采用client模式,命令如下:
SPARK_HOME=/export/ servers// spark${SPARK_HOME} /bin/ spark-submit \512 m \512 m \1 \2 \${SPARK_HOME} /examples/ jars/spark-examples_2.11 -2.4 .5 .jar \10
http://node1:8088/cluster
2.4.4.3 cluster模式
DeployMode为Cluster,表示应用Driver Program运行在集群从节点某台机器上,示意图如下:
运行圆周率PI程序,采用cluster模式,命令如下:
SPARK_HOME=/export/ servers// spark${SPARK_HOME} /bin/ spark-submit \512 m \512 m \1 \2 \${SPARK_HOME} /examples/ jars/spark-examples_2.11 -2.4 .5 .jar \10
http://node1:8088/cluster
2.4.4.4 总结
Cluster和Client模式最最本质的区别是:Driver程序运行在哪里。
cluster模式:生产环境中使用该模式
1.Driver运行在Client上
2.Driver输出结果会在客户端显示
client模式:学习测试时使用,开发不用,了解即可
1.Driver程序在YARN集群中,
2.Driver输出结果不能在客户端显示
3.该模式下Driver运行ApplicattionMaster这个节点上,如果出现问题,yarn会重启ApplicattionMaster(Driver)
2.4.5 扩展阅读:两种模式详细流程 2.4.5.1 client模式
在YARN Client模式下,Driver在任务提交的本地机器上运行,示意图如下:
具体流程步骤如下:
1)、Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;
3)、ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
5)、之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
2.4.5.2 cluster模式
在YARN Cluster模式下,Driver运行在NodeManager Contanier中,此时Driver与AppMaster合为一体,示意图如下:
具体流程步骤如下:
1)、任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver;
3)、Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册;
5)、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行;
2.4.6 扩展阅读:Spark 集群角色
当Spark Application运行在集群上时,主要有四个部分组成,如下示意图:
1)Driver:是一个JVM Process 进程,编写的Spark应用程序就运行在Driver上,由Driver进程执行;Master(ResourceManager):是一个JVM Process 进程,主要负责资源的调度和分配,并进行集群的监控等职责;Worker(NodeManager):是一个JVM Process 进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。Executor:是一个JVM Process 进程,一个Worker(NodeManager)上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
2.4.7 扩展阅读:spark-shell和spark-submit
Spark支持多种集群管理器(Cluster Manager),取决于传递给SparkContext的MASTER环境变量的值:local、spark、yarn,区别如下:
Master URLMeaning
local在本地运行,只有一个工作进程,无并行计算能力。
local[K]在本地运行,有K个工作进程,通常设置K为机器的CPU核心数量。
local[*]在本地运行,工作进程数量等于机器的CPU核心数量。
spark://HOST:PORT以Standalone模式运行,这是Spark自身提供的集群运行模式,默认端口号: 7077。详细文档见:Spark standalone cluster。
mesos://HOST:PORT在Mesos集群上运行,Driver进程和Worker进程运行在Mesos集群上,部署模式必须使用固定值:–deploy-mode cluster。详细文档见:MesosClusterDispatcher.
yarn-client --master yarn--deploy-mode client在Yarn集群上运行,Driver进程在本地,Executor进程在Yarn集群上,部署模式必须使用固定值:–deploy-mode client。Yarn集群地址必须在HADOOP_CONF_DIR or YARN_CONF_DIR变量里定义。
yarn-cluster --master yarn--deploy-mode cluster在Yarn集群上运行,Driver进程在Yarn集群上,Executor进程也在Yarn集群上,部署模式必须使用固定值:–deploy-mode cluster。Yarn集群地址必须在HADOOP_CONF_DIR or YARN_CONF_DIR变量里定义。
2.4.7.1 spark-shell
引入
之前我们使用提交任务都是使用spark-shell提交,spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下可以用scala编写spark程序,适合学习测试时使用!
示例
spark-shell可以携带参数
spark-shell –master local[N] 数字N表示在本地模拟N个线程来运行当前任务
spark-shell –master local[*] *表示使用当前机器上所有可用的资源
默认不携带参数就是–master local[*]
spark-shell –master spark://node01:7077,node02:7077 表示运行在集群上
2.4.7.1 spark-submit
引入
spark-shell交互式编程确实很方便我们进行学习测试,但是在实际中我们一般是使用IDEA开发Spark应用程序打成jar包交给Spark集群/YARN去执行,所以我们还得学习一个spark-submit命令用来帮我们提交jar包给spark集群/YARN
spark-submit命令是我们开发时常用的!!!
示例
SPARK_HOME=/export/ servers// spark${SPARK_HOME} /bin/ spark-submit \2 ] \${SPARK_HOME} /examples/ jars/spark-examples_2.11 -2.4 .5 .jar \10
SPARK_HOME=/export/ servers// spark${SPARK_HOME} /bin/ spark-submit \// node1:7077 \${SPARK_HOME} /examples/ jars/spark-examples_2.11 -2.4 .5 .jar \10
SPARK_HOME=/export/ servers// spark${SPARK_HOME} /bin/ spark-submit \// node1:7077 ,node2:7077 \${SPARK_HOME} /examples/ jars/spark-examples_2.11 -2.4 .5 .jar \10
2.4.8 扩展阅读:命令参数
开发中需要根据实际任务的数据量大小、任务优先级、公司服务器的实际资源情况,参考公司之前的提交的任务的脚本参数,灵活设置即可
官方文档:http://spark.apache.org/docs/2.4.5/submitting-applications.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 [root@node1 ~ ]# / export/ servers/ / spark/ bin/ spark- submit - submit [options] < app jar | python file | R file> [app arguments]- submit - submit - submit run- example [options] example- class [example args]/ / https:/ / host:port, or local (Default : local [* ]).on one of the worker machines inside the cluster ("cluster")Default : client).and executor classpaths.on the driver and executor classpaths. Will search the local then maven central and any additional remoteby in search for the maven coordinates given with on the PYTHONPATH for Python apps.of each executor. File paths of these filesin executors can be accessed via SparkFiles.get(fileName).for conf/ spark- defaults.conf.with not work with only :Default : 1 ).or Mesos with cluster deploy mode only :and Mesos only :and YARN only :or all available cores on the worker in standalone mode)- only :dynamic allocation is enabled, the initial number of at least NUM.of each executor.to running the Application Master via the Securefor renewing the login tickets and the
2.4.8.1 应用提交语法
使用【spark-submit】提交应用语法如下:
Usage: spark-submit [options] <app jar | python file > [app arguments]
如果使用Java或Scala语言编程程序,需要将应用编译后达成Jar包形式,提交运行。
2.4.8.2 基本参数配置
提交运行Spark Application时,有些基本参数需要传递值,如下所示:
动态加载Spark Applicaiton运行时的参数,通过–conf进行指定,如下使用方式:
2.4.8.3 Driver Program 参数配置
每个Spark Application运行时都有一个Driver Program,属于一个JVM Process进程,可以设置内存Memory和CPU Core核数。
2.4.8.4 Executor 参数配置
每个Spark Application运行时,需要启动Executor运行任务Task,需要指定Executor个数及每个Executor资源信息(内存Memory和CPU Core核数)。
2.4.8.5 官方案例
Spark 官方提供一些针对不同模式运行Spark Application如何设置参数提供案例,具体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 ./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master local[8] \/path/to/examples.jar \./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://207.184.161.138 :7077 \--executor-memory 20G \--total-executor-cores 100 \/path/to/examples.jar \./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://207.184.161.138 :7077 \--deploy-mode cluster \--supervise \--executor-memory 20G \--total-executor-cores 100 \/path/to/examples.jar \./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \ --executor-memory 20G \--num-executors 50 \/path/to/examples.jar \./bin/spark-submit \--master spark://207.184.161.138 :7077 \./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master mesos://207.184.161.138 :7077 \--deploy-mode cluster \--supervise \--executor-memory 20G \--total-executor-cores 100 \//path/to/examples.jar \./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master k8s://xx.yy.zz.ww :443 \--deploy-mode cluster \--executor-memory 20G \--num-executors 50 \//path/to/examples.jar \
3 Spark基础应用开发 3.1 Pom 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 <?xml version="1.0" encoding="UTF-8"?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion > 4.0.0</modelVersion > <groupId > cn.xiaoma</groupId > <artifactId > spark_study_42</artifactId > <version > 1.0-SNAPSHOT</version > <repositories > <repository > <id > aliyun</id > <url > http://maven.aliyun.com/nexus/content/groups/public/</url > </repository > <repository > <id > apache</id > <url > https://repository.apache.org/content/repositories/snapshots/</url > </repository > <repository > <id > cloudera</id > <url > https://repository.cloudera.com/artifactory/cloudera-repos/</url > </repository > </repositories > <properties > <encoding > UTF-8</encoding > <maven.compiler.source > 1.8</maven.compiler.source > <maven.compiler.target > 1.8</maven.compiler.target > <scala.version > 2.11.12</scala.version > <hadoop.version > 2.7.5</hadoop.version > <spark.version > 2.4.5</spark.version > </properties > <dependencies > {scala.version} <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-core_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-sql_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-hive_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-hive-thriftserver_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-streaming_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-mllib_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-streaming-kafka-0-10_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-sql-kafka-0-10_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > 2.7.5</version > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 5.1.38</version > </dependency > <dependency > <groupId > com.alibaba</groupId > <artifactId > fastjson</artifactId > <version > 1.2.47</version > </dependency > <dependency > <groupId > com.hankcs</groupId > <artifactId > hanlp</artifactId > <version > portable-1.7.7</version > </dependency > <dependency > <groupId > redis.clients</groupId > <artifactId > jedis</artifactId > <version > 2.9.0</version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-mllib_2.11</artifactId > <version > 2.4.5</version > </dependency > </dependencies > <build > <sourceDirectory > src/main/scala</sourceDirectory > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <version > 3.5.1</version > </plugin > <plugin > <groupId > net.alchim31.maven</groupId > <artifactId > scala-maven-plugin</artifactId > <version > 3.2.2</version > <executions > <execution > <goals > <goal > compile</goal > <goal > testCompile</goal > </goals > <configuration > <args > <arg > -dependencyfile</arg > <arg > $ {project.build.directory} /.scala_dependencies</arg > </args > </configuration > </execution > </executions > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-surefire-plugin</artifactId > <version > 2.18.1</version > <configuration > <useFile > false</useFile > <disableXmlReport > true</disableXmlReport > <includes > <include > **/*Test.*</include > <include > **/*Suite.*</include > </includes > </configuration > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-shade-plugin</artifactId > <version > 2.3</version > <executions > <execution > <phase > package</phase > <goals > <goal > shade</goal > </goals > <configuration > <filters > <filter > <artifact > *:*</artifact > <excludes > <exclude > META-INF/*.SF</exclude > <exclude > META-INF/*.DSA</exclude > <exclude > META-INF/*.RSA</exclude > </excludes > </filter > </filters > <transformers > <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass > </mainClass > </transformer > </transformers > </configuration > </execution > </executions > </plugin > </plugins > </build > </project >
3.2 WordCount本地运行 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import org.apache.spark.rdd.RDD2020 /11/ 13 14 :44 // 1 .准备环境(Env)sc-->SparkContext"wc" ).setMaster("local[*]" )"WARN" )// 2 .加载文件(Source)// RDD:弹性分布式数据集(RDD),Spark中的基本抽象。// 先简单理解为分布式集合!类似于DataSet!// fileRDD: RDD[一行行的数据]"data/input/words.txt" )// 3 .处理数据(Transformation)// 3.1 切分// wordRDD: RDD[一个个的单词]// val wordRDD: RDD[String] = fileRDD.flatMap((line)=>line.split(" " ))" " ))// _下划线表示每一行// 3.2 每个单词记为1 // wordAndOneRDD: RDD[(单词, 1 )]// val wordAndOneRDD: RDD[(String, Int)] = wordRDD.map((word)=>(word,1 ))1 ))// _表示每一个单词// 3.3 .分组聚合reduceByKey= 先groupByKey + sum或reduce// val groupedRDD: RDD[(String, Iterable[Int])] = wordAndOneRDD.groupByKey()// val resultRDD: RDD[(String, Int)] = groupedRDD.mapValues(_.sum)// val resultRDD: RDD[(String, Int)] = wordAndOneRDD.reduceByKey((temp,current)=>temp + current)// 4 .输出结果(Sink)// 将分布式集合收集为本地集合// action// println(array.toBuffer)// array.foreach(t=>println(t))// array.foreach(println(_))// array.foreach(println _)// 行为参数化// cation1000 * 1200 )// 等待20 分钟,方便查看webUI:http:// localhost:4040 /jobs/ // 5 .关闭资源
3.3 WordCount集群运行 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import org.apache.spark.rdd.RDD2020 /11/ 13 14 :44 if (args.length != 2 ){"请携带2个参数: input-path oupput-path" )exit (1 )// 非0 表示非正常退出程序// 1 .准备环境(Env)sc-->SparkContext"wc" )// .setMaster("local[*]" )"WARN" )// 2 .加载文件(Source)// RDD:弹性分布式数据集(RDD),Spark中的基本抽象。// 先简单理解为分布式集合!类似于DataSet!// fileRDD: RDD[一行行的数据]0 ))// 表示启动该程序的时候需要通过参数执行输入数据路径// 3 .处理数据(Transformation)// 3.1 切分// wordRDD: RDD[一个个的单词]// val wordRDD: RDD[String] = fileRDD.flatMap((line)=>line.split(" " ))" " ))// _下划线表示每一行// 3.2 每个单词记为1 // wordAndOneRDD: RDD[(单词, 1 )]// val wordAndOneRDD: RDD[(String, Int)] = wordRDD.map((word)=>(word,1 ))1 ))// _表示每一个单词// 3.3 .分组聚合reduceByKey= 先groupByKey + sum或reduce// val groupedRDD: RDD[(String, Iterable[Int])] = wordAndOneRDD.groupByKey()// val resultRDD: RDD[(String, Int)] = groupedRDD.mapValues(_.sum)// val resultRDD: RDD[(String, Int)] = wordAndOneRDD.reduceByKey((temp,current)=>temp + current)// val resultRDD: RDD[(String, Int)] = wordAndOneRDD.reduceByKey(_+_)// 4 .输出结果(Sink)// 将分布式集合收集为本地集合// val array: Array[(String, Int)] = resultRDD.collect()// println(array.toBuffer)// array.foreach(t=>println(t))// array.foreach(println(_))// array.foreach(println _)// array.foreach(println)// 行为参数化"${args(1)}_${System.currentTimeMillis()}" )// Thread.sleep(1000 * 120 )// 等待2 分钟,方便查看webUI:http:// localhost:4040 /jobs/ // 5 .关闭资源
打包
改名并上传到linux/hdfs(方便以后在任意客户端提交)
提交任务
SPARK_HOME= /export/ servers// spark${SPARK_HOME} /bin/ spark-submit \512 m \512 m \1 \2 \/root/ wc.jar \// node1:8020 /wordcount/i nput/words.txt hdfs:/ /node1:8020/ wordcount/output42
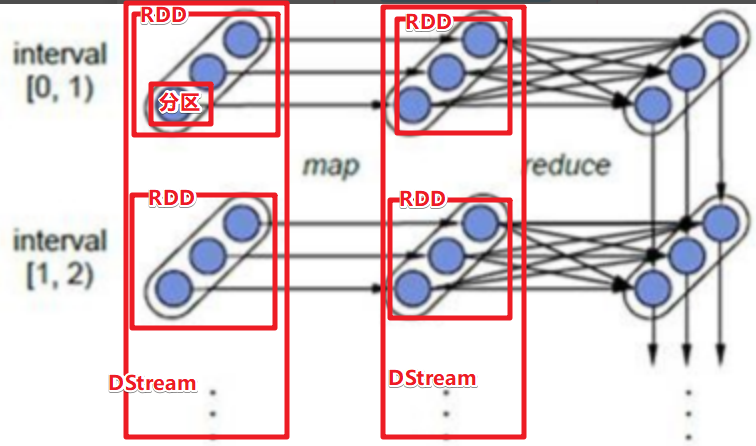
3.4 WordCount-java8版本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import org.apache.spark.SparkConf;class WordCount {[] args) {new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) ;new JavaSparkContext(sparkConf ) ;LogLevel("WARN" ) ;File("data/input/words.txt" ) ;Map((line ) -> Arrays .as List(line .split (" " ) ).iterator() );ToPair(word -> new Tuple2(word , 1) );ByKey((a , b ) -> a + b);list = resultRDD.collect() ;list .for Each(System.out ::println ) ;
3.5 WordCount流程图解
3.6 扩展阅读:main函数执行流程
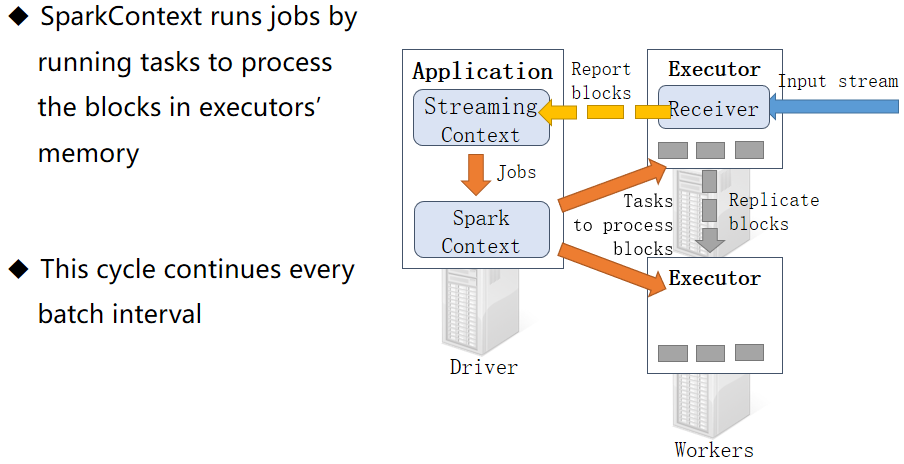
Spark Application应用程序运行时,无论client还是cluster部署模式DeployMode,当Driver Program和Executors启动完成以后,就要开始执行应用程序中MAIN函数的代码,以词频统计WordCount程序为例剖析讲解。
第一、构建SparkContex对象和关闭SparkContext资源,都是在Driver Program中执行,上图中①和③都是,如下图所示:
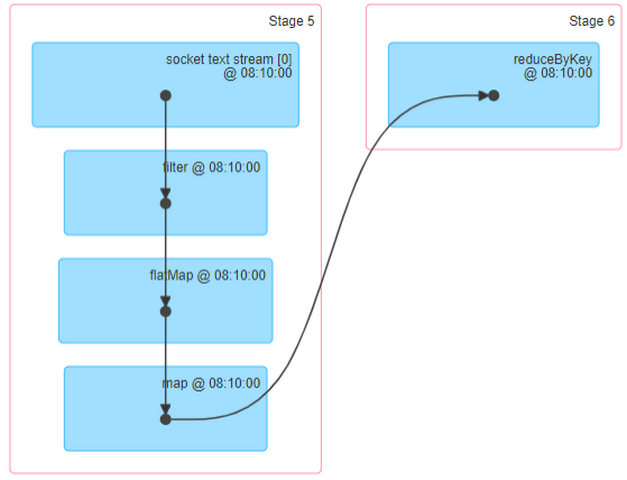
第二、上图中②的加载数据【A】、处理数据【B】和输出数据【C】代码,都在Executors上执行,从WEB UI监控页面可以看到此Job(RDD#action触发一个Job)对应DAG图,如下所示:
将结果数据resultRDD调用saveAsTextFile方法,保存数据到外部存储系统中,代码在Executor中执行的。但是如果resultRDD调用take、collect或count方法时,获取到最终结果数据返回给Driver,代码如下:
运行应用程序时,将数组resultArray数据打印到标准输出,Driver Program端日志打印结果:
综上所述Spark Application中Job执行有两个主要点:
1)、RDD输出函数分类两类
第一类:返回值给Driver Progam,比如count、first、take、collect等
第二类:没有返回值,比如直接打印结果、保存至外部存储系统(HDFS文件)等
2)、在Job中从读取数据封装为RDD和一切RDD调用方法都是在Executor中执行,其他代码都是在Driver Program中执行
SparkContext创建与关闭、其他变量创建等在Driver Program中执行
RDD调用函数都是在Executors中执行
4 Spark Core 4.1 RDD详解 4.1.1 为什么需要RDD
1.原生集合:Java/Scala中的List,但是只支持单机版! 不支持分布式!如果要做分布式的计算,需要做很多额外工作,线程/进程通信,容错,自动均衡…..麻烦,所以就诞生了框架!
2.MR:效率低(运行效率低,开发效率低)–早就淘汰
3.诞生了Spark/Flink
Spark/Flink,对原生集合进行了封装, 抽象出一个新的数据类型–RDD/DataSet
4.1.2 什么是RDD
在Spark开山之作Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing这篇paper中(以下简称 RDD Paper),Matei等人提出了RDD这种数据结构,文中开头对RDD的定义是:
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel.
RDD(Resilient Distributed Dataset)弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
所有的运算以及操作都建立在 RDD 数据结构的基础之上。
RDD设计的核心点为:
拆分核心要点三个方面:
可以认为RDD是分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract Class和泛型Generic Type:
RDD弹性分布式数据集核心点示意图如下:
4.1.3 RDD5大特性
RDD 数据结构内部有五个特性(摘录RDD 源码)
前三个特征每个RDD都具备的,后两个特征可选的。
第一个:A list of partitions
一组分片(Partition)/一个分区(Partition)列表,即数据集的基本组成单位;
对于RDD来说,每个分片都会被一个计算任务处理,分片数决定并行度;
用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值;
第二个:A function for computing each split
一个函数会被作用在每一个分区;
Spark中RDD的计算是以分片为单位的,compute函数会被作用到每个分区上;
第三个:A list of dependencies on other RDDs
一个RDD会依赖于其他多个RDD;
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算(Spark的容错机制);
第四个:Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
可选项,对于KeyValue类型的RDD会有一个Partitioner,即RDD的分区函数;
当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。
只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。
Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
第五个:Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
可选项,一个列表,存储存取每个Partition的优先位置(preferred location);
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。
按照”移动数据不如移动计算“的理念,Spark在进行任务调度的时候,会尽可能选择那些存有数据的worker节点来进行任务计算。(数据本地性)
RDD 是一个数据集的表示,不仅表示了数据集,还表示了这个数据集从哪来、如何计算,主要属性包括五个方面(必须牢记,通过编码加深理解,面试常问):
RDD将Spark的底层的细节都隐藏起来(自动容错、位置感知、任务调度执行,失败重试等),让开发者可以像操作本地集合一样以函数式编程的方式操作RDD这个分布式数据集,进行各种并行计算,RDD中很多处理数据函数与列表List中相同与类似。
4.2 RDD创建
官方文档:http://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds
如何将数据封装到RDD集合中,主要有两种方式:并行化本地集合(Driver Program中)和引用加载外部存储系统(如HDFS、Hive、HBase、Kafka、Elasticsearch等)数据集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 object RDDDemo01_Create {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val rdd1: RDD[String ] = sc.parallelize(List("hadoop spark" , "hive flink" , "hive flink" ) )val rdd2: RDD[String ] = sc.parallelize(List("hadoop spark" , "hive flink" , "hive flink" ) , 8 )val rdd3: RDD[String ] = sc.makeRDD(List("hadoop spark" , "hive flink" , "hive flink" ) , 9 ) val rdd4: RDD[String ] = sc.textFile("data/input/words.txt" ) val rdd5: RDD[String ] = sc.textFile("data/input/words.txt" , 3) val rdd6: RDD[String ] = sc.textFile("data/input/ratings10" ) val rdd7: RDD[String ] = sc.textFile("data/input/ratings10" , 3) val rdd8: RDD[(String , String )] = sc.wholeTextFiles("data/input/ratings10" ) val rdd9: RDD[(String , String )] = sc.wholeTextFiles("data/input/ratings10" , 3) val arr: Array[(String , String )] = rdd9.take(1 ) "rdd1:" + rdd1.getNumPartitions) "rdd2:" + rdd2.getNumPartitions) "rdd3:" + rdd3.getNumPartitions) "rdd4:" + rdd4.getNumPartitions) "rdd5:" + rdd5.getNumPartitions) "rdd6:" + rdd6.getNumPartitions) "rdd7:" + rdd7.getNumPartitions) "rdd8:" + rdd8.getNumPartitions) "rdd9:" + rdd9.getNumPartitions)
4.3 RDD操作 4.3.1 函数分类
官方文档:http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-operations
对于 Spark 处理的大量数据而言,会将数据切分后放入RDD作为Spark 的基本数据结构,开发者可以在 RDD 上进行丰富的操作,之后 Spark 会根据操作调度集群资源进行计算。总结起来,RDD 的操作主要可以分为 Transformation 和 Action 两种。
RDD中操作(函数、算子)分为两类:
1)、Transformation转换操作:返回一个新的RDD
which create a new dataset from an existing one
所有Transformation函数都是Lazy,不会立即执行,需要Action函数触发
2)、Action动作操作:返回值不是RDD(无返回值或返回其他的)
which return a value to the driver program after running a computation on the datase
所有Action函数立即执行(Eager),比如count、first、collect、take等
此外注意RDD中函数细节:
第一点:RDD不实际存储真正要计算的数据,而是记录了数据的位置在哪里,数据的转换关系(调用了什么方法,传入什么函数);
第二点:RDD中的所有转换都是惰性求值/延迟执行的,也就是说并不会直接计算。只有当发生一个要求返回结果给Driver的Action动作时,这些转换才会真正运行。之所以使用惰性求值/延迟执行,是因为这样可以在Action时对RDD操作形成DAG有向无环图进行Stage的划分和并行优化,这种设计让Spark更加有效率地运行。
面试题1:Spark中的RDD操作API/算子为什么要区分Transformation和Action?
Transformation可以懒执行/延迟执行Action 会触发执行
面试题2:为什么要有懒执行/延迟执行和触发执行?
因为在触发执行的之后可以对前面的懒执行/延迟执行的代码进行优化!
4.3.2 常用函数 4.3.2.1 分区操作函数
每个RDD由多分区组成的,实际开发建议对每个分区数据的进行操作,map函数使用mapPartitions代替、foreache函数使用foreachPartition代替。
map是对每个分区的每个数据操作
mapPartitions是对每个分区操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import org.apache.spark.rdd.RDD2020 /11/ 13 14 :44 // 1 .准备环境(Env)sc-->SparkContext"wc" ).setMaster("local[*]" )"WARN" )// 2 .加载文件(Source)"data/input/words.txt" )// 3 .处理数据(Transformation)" " ))// _下划线表示每一行//m ap(函数),该函数会作用在每个分区中的每一条数据上,value是每一条数据// wordRDD.map((_,1 ))// 开启连接-有几条数据就几次1 )// 关闭连接-有几条数据就几次// _表示每一个单词//m apPartitions(函数):该函数会作用在每个分区上,values是每个分区上的数据// 开启连接-有几个分区就几次// values.map((_,1 ))1 )) // value是该分区中的每一条数据// 关闭连接-有几个分区就几次// 4 .输出结果(Sink)// foreach(函数),该函数会作用在每个分区中的每一条数据上,value是每一条数据// Applies a function f to all elements of this RDD.// 开启连接-有几条数据就几次// 关闭连接-有几条数据就几次// foreachPartition(函数),该函数会作用在每个分区上,values是每个分区上的数据// Applies a function f to each partition of this RDD.// 开启连接-有几个分区就几次// value是该分区中的每一条数据// 关闭连接-有几个分区就几次// 5 .关闭资源
4.3.2.2 重分区函数
Flink中的重分区函数:
* global();全部发往第一个* broadcast();广播* forward();前后并行度一样的时候一对一转发* shuffle();随机打乱* rebalance();重平衡* rescale();本地轮流分区,如前2后4,前1->,如前4后2,前2->1* partitionCustom:自定义分区
Spark里面也有重分区函数:
1)增加分区函数:repartition
函数名称:repartition,此函数使用的谨慎,会产生Shuffle。
注意: repartition底层调用coalesce(numPartitions, shuffle=true)
2)、减少分区函数:coalesce
函数名称:coalesce,shuffle参数默认为false,不会产生Shuffle,默认只能减少分区
比如RDD的分区数目为10个分区,此时调用rdd.coalesce(12),不会对RDD进行任何操作。
3)、调整分区函数
在PairRDDFunctions中partitionBy函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 object RDDDemo03_partition def main Array [String ]): Unit = {val sparkConf: SparkConf = new SparkConf ().setAppName("wc" ).setMaster("local[*]" )val sc: SparkContext = new SparkContext (sparkConf)"WARN" )val rdd1: RDD [String ] = sc.parallelize(List ("hadoop spark" , "hive flink" , "hive flink" ), 4 )val rdd2: RDD [String ] = rdd1.repartition(5 )val rdd3: RDD [String ] = rdd1.repartition(3 )val rdd4: RDD [String ] = rdd1.coalesce(5 )val rdd5: RDD [String ] = rdd1.coalesce(3 )val resultRDD = sc.textFile("data/input/words.txt" )" " ))1 )) val key: String = t._1val num: Int = TaskContext .getPartitionId()s"默认的hash分区器进行的分区:分区编号:${num} ,key:${key} " )val resultRDD2: RDD [(String , Int )] = sc.textFile("data/input/words.txt" )" " ))1 )) new MyPartitioner (1 ),_+_)val key: String = t._1val num: Int = TaskContext .getPartitionId()s"自定义分区器进行的分区:分区编号:${num} ,key:${key} " )class MyPartitioner (partitions: Int ) extends Partitioner override def numPartitions Int = partitionsoverride def getPartition Any ): Int = {0
4.3.2.3 聚合函数 4.3.2.3.1 没有key的聚合函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 object RDDDemo04_Aggregate {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val nums: RDD[Int ] = sc.parallelize( 1 to 10 ) val result1: Double = nums.sum() val result2: Int = nums.reduce(_+_)val result3: Int = nums.fold(0 )(_+_)val result4: Int = nums.aggregate(0 )(_+_,_+_)()
4.3.2.3.2 有key的聚合函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 object RDDDemo05_Aggregate {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val wordAndOne: RDD[(String , Int )] = sc.textFile("data/input/words.txt" ) Map(_ .split (" " ) )1 ))val groupedRDD: RDD[(String , Iterable [Int ] )] = wordAndOne.groupByKey() val result1: RDD[(String , Int )] = groupedRDD.mapValues(_ .sum ) val result2: RDD[(String , Int )] = wordAndOne.reduceByKey(_ +_ ) val result3: RDD[(String , Int )] = wordAndOne.aggregateByKey(0) (_+_,_+_)()
4.3.2.3.3 面试题:groupByKey和reduceByKey
区别1:reduceByKey代码简单一步搞定
区别2:reduceByKey比groupByKey性能要好
4.3.2.4 关联函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 object RDDDemo06_join {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val empRDD: RDD[(Int , String )] = sc.parallelize(Seq((1001, "zhangsan" ) , (1002 , "lisi" ), (1003 , "wangwu" ), (1004 , "zhangliu" ))val deptRDD: RDD[(Int , String )] = sc.parallelize(Seq((1001, "销售部" ) , (1002 , "技术部" ))val result1: RDD[(Int , (String , String ))] = empRDD.join(deptRDD)"============================" )val result2: RDD[(Int , (String , Option [String ] ))] = empRDD.leftOuterJoin(deptRDD ) ()
4.3.2.5 排序函数-求TopKey 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 object RDDDemo07_sort {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val result: RDD[(String , Int )] = sc.textFile("data/input/words.txt" ) Map(_ .split (" " ) )1 ))ByKey(_ + _ ) "============sortBy:适合大数据量排序====================" )val sortedResult1: RDD[(String , Int )] = result.sortBy(_ ._2 ,false ) 3 ).foreach(println)"============sortByKey:适合大数据量排序====================" )val sortedResult2: RDD[(Int , String )] = result.map(_ .ByKey(false ) 3 ).foreach(println)"============top:适合小数据量排序====================" )val sortedResult3: Array[(String , Int )] = result.top(2 )(Ordering ._ ._2 )()
4.4 RDD持久化与Checkpoint
在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
4.4.1 RDD持久化
缓存/持久化级别
在Spark框架中对数据缓存可以指定不同的级别,对于开发来说至关重要,如下所示:
持久化级别
说明
MEMORY_ONLY(默认)将RDD以非序列化的Java对象存储在JVM中。 如果没有足够的内存存储RDD,则某些分区将不会被缓存,每次需要时都会重新计算。 这是默认级别。
MEMORY_AND_DISK(开发中可以使用这个) 将RDD以非序列化的Java对象存储在JVM中。如果数据在内存中放不下,则溢写到磁盘上.需要时则会从磁盘上读取
MEMORY_ONLY_SER
(Java and Scala)
将RDD以序列化的Java对象(每个分区一个字节数组)的方式存储.这通常比非序列化对象(deserialized objects)更具空间效率,特别是在使用快速序列化的情况下,但是这种方式读取数据会消耗更多的CPU。
MEMORY_AND_DISK_SER (Java and Scala)
与MEMORY_ONLY_SER类似,但如果数据在内存中放不下,则溢写到磁盘上,而不是每次需要重新计算它们。
DISK_ONLY
将RDD分区存储在磁盘上。
MEMORY_ONLY_2, MEMORY_AND_DISK_2等
与上面的储存级别相同,只不过将持久化数据存为两份,备份每个分区存储在两个集群节点上。
OFF_HEAP(实验中)
与MEMORY_ONLY_SER类似,但将数据存储在堆外内存中。 (即不是直接存储在JVM内存中)
实际项目中缓存数据时,往往选择MEMORY_AND_DISK
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 object RDDDemo08_cache {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val result: RDD[(String , Int )] = sc.textFile("data/input/words.txt" ) Map(_ .split (" " ) )1 ))ByKey(_ + _ ) "============sortBy:适合大数据量排序====================" )val sortedResult1: RDD[(String , Int )] = result.sortBy(_ ._2 ,false ) 3 ).foreach(println)"============sortByKey:适合大数据量排序====================" )val sortedResult2: RDD[(Int , String )] = result.map(_ .ByKey(false ) 3 ).foreach(println)"============top:适合小数据量排序====================" )val sortedResult3: Array[(String , Int )] = result.top(3 )(Ordering ._ ._2 )() ()
4.4.2 RDD CheckPoint
RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
在Spark Core中对RDD做checkpoint,可以切断做checkpoint RDD的依赖关系,将RDD数据保存到可靠存储(如HDFS)以便数据恢复;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 object RDDDemo09_checkpoint {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val result: RDD[(String , Int )] = sc.textFile("data/input/words.txt" ) Map(_ .split (" " ) )1 ))ByKey(_ + _ ) CheckpointDir("./ckp" ) () "============sortBy:适合大数据量排序====================" )val sortedResult1: RDD[(String , Int )] = result.sortBy(_ ._2 ,false ) 3 ).foreach(println)"============sortByKey:适合大数据量排序====================" )val sortedResult2: RDD[(Int , String )] = result.map(_ .ByKey(false ) 3 ).foreach(println)"============top:适合小数据量排序====================" )val sortedResult3: Array[(String , Int )] = result.top(3 )(Ordering ._ ._2 )() ()
4.4.3 总结:持久化和Checkpoint的区别
区别:1)、存储位置
Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存);
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上;
2)、生命周期
Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法;
Checkpoint的RDD在程序结束后依然存在,不会被删除;
3)、Lineage(血统、依赖链、依赖关系)
Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来;
Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链;
结论:怎么用!
实际开发对于计算复杂且后续会被频繁使用的RDD先进行缓存/持久化提高效率, 再使用Checkpoint保证数据觉得安全
sc.setCheckpointDir("hdfs路径")//实际开发写HDFS路径 checkpoint ()
4.5 共享变量 4.5.1 广播变量
广播变量Broadcast Variables
和Flink中的广播变量一样,Spark中的广播变量也是将变量发送到各个Worker,然后各个Worker上的各个分区任务去各自的Worker上读取, 避免发给各个分区
广播变量是不可变的, 如果数据有变化需要重新广播,
广播变量的数据不能太大
4.5.2 累加器
累加器Accumulators
和Flink的累加器一样
4.5.3 示例
words2.txt
hadoop spark # hadoop spark spark
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 object RDDDemo10_ShareVariable {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val dataRDD: RDD[String ] = sc.textFile("data/input/words2.txt" , minPartitions = 2) val list : List[String ] = List("," , "." , "!" , "#" , "$" , "%" ) val broadcast: Broadcast[List [String ] ] = sc.broadcast(list )val accumulator: LongAccumulator = sc.longAccumulator("my-counter" ) val result: RDD[(String , Int )] = dataRDDStringUtils .NotBlank(_ ) )Map(_ .split ("\\s+" ) ) val workerList: List[String ] = broadcast.valueif (workerList.contains(value)) {1 )false else {true 1 ))ByKey(_ + _ ) "wordcount的结果为:" )"获取到的累加器的值/特殊字符的总数为:" +accumulator.value)()
4.6 外部数据源-了解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 object RDDDemo11_externalDataSource{[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val result: RDD[(String , Int )] = sc.textFile("data/input/words.txt" ) Map(_ .split (" " ) )1 )) ByKey(_ + _ ) 1 ).saveAsSequenceFile("data/output/sequence" ) 1 ).saveAsObjectFile("data/output/object" ) val rdd1: RDD[(String , Int )] = sc.sequenceFile("data/output/sequence" ) val rdd2: RDD[(String , Int )] = sc.object File("data/output/object" ) ()
4.6.1 Mysql数据源 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 object RDDDemo12_jdbc{Unit = {val sparkConf: SparkConf = new SparkConf().setAppName("wc" ).setMaster("local[*]" )val sc: SparkContext = new SparkContext(sparkConf)"WARN" )val data : RDD[(String, Int )] = sc.parallelize(List(("jack" , 18 ), ("tom" , 19 ), ("rose" , 20 )))data .foreachPartition(rows=>{val conn: Connection = DriverManager.getConnection("jdbc:mysql://192.168.88.161:3306/bigdata?characterEncoding=UTF-8" ,"root" ,"123456" )val sql:String = "INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (NULL, ?, ?);" val ps: PreparedStatement = conn.prepareStatement(sql)val name: String = row._1val age: Int = row._21 ,name)2 ,age)if (conn != null ) conn.close()if (ps != null ) ps.close()val getConnection = () =>DriverManager.getConnection("jdbc:mysql://192.168.88.161:3306/bigdata?characterEncoding=UTF-8" ,"root" ,"123456" )val querySQL = "select id,name,age from t_student where ? <= id and id <= ?" val mapRow = (rs:ResultSet) =>{val id: Int = rs.getInt("id" )val name: String = rs.getString("name" )val age: Int = rs.getInt("age" )val studentRDD = new JdbcRDD[(Int , String, Int )](4 , 6 , 2 ,
4.6.2 HBase数据源
后续学习需要的时候直接使用工具类!
因为原生API很难用!
https://github.com/teeyog/blog/issues/22
https://blog.csdn.net/u011817217/article/details/81667115
4.7 Spark内核原理
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
以词频统计WordCount程序为例,Job执行是DAG图:
4.7.1 RDD 依赖
RDD 的容错机制是通过将 RDD 间转移操作构建成有向无环图来实现的。从抽象的角度看,RDD 间存在着血统继承关系,其本质上是 RDD之间的依赖(Dependency)关系。
从图的角度看,RDD 为节点,在一次转换操作中,创建得到的新 RDD 称为子 RDD,同时会产生新的边,即依赖关系,子 RDD 依赖向上依赖的 RDD 便是父 RDD,可能会存在多个父 RDD。可以将这种依赖关系进一步分为两类,分别是窄依赖(NarrowDependency)和 Shuffle 依赖(Shuffle Dependency 在部分文献中也被称为 Wide Dependency,即宽依赖)。
4.7.1.1 窄依赖(Narrow Dependency)
窄依赖中:即父 RDD 与子 RDD 间的分区是一对一的。换句话说父RDD中,一个分区内的数据是不能被分割的,只能由子RDD中的一个分区整个利用。
上图中 P代表 RDD中的每个分区(Partition),我们看到,RDD 中每个分区内的数据在上面的几种转移操作之后被一个分区所使用,即其依赖的父分区只有一个。比如图中的 map、union 和 join 操作,都是窄依赖的。注意,join 操作比较特殊,可能同时存在宽、窄依赖。
4.7.1.2 Shuffle 依赖(宽依赖 Wide Dependency)
Shuffle 有“洗牌、搅乱”的意思,这里所谓的 Shuffle 依赖也会打乱原 RDD 结构的操作。具体来说,父 RDD 中的分区可能会被多个子 RDD 分区使用。因为父 RDD 中一个分区内的数据会被分割并发送给子 RDD 的所有分区,因此 Shuffle 依赖也意味着父 RDD与子 RDD 之间存在着 Shuffle 过程。
上图中 P 代表 RDD 中的多个分区,我们会发现对于 Shuffle 类操作而言,结果 RDD 中的每个分区可能会依赖多个父 RDD 中的分区。需要说明的是,依赖关系是 RDD 到 RDD 之间的一种映射关系,是两个 RDD 之间的依赖,如果在一次操作中涉及多个父 RDD,也有可能同时包含窄依赖和 Shuffle 依赖。
4.7.1.3 如何区分宽窄依赖
区分RDD之间的依赖为宽依赖还是窄依赖,主要在于父RDD分区数据与子RDD分区数据关系:
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖;宽依赖:父RDD的一个分区会被子RDD的多个分区依赖,涉及Shuffle;
为什么要设计宽窄依赖??
1)、对于窄依赖来说
Spark可以并行计算
如果有一个分区数据丢失,只需要从父RDD的对应个分区重新计算即可,不需要重新计算整个任务,提高容错。
2)、对应宽依赖来说
划分Stage的依据,产生Shuffle
4.7.2 DAG和Stage
在图论中,如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。而在Spark中,由于计算过程很多时候会有先后顺序,受制于某些任务必须比另一些任务较早执行的限制,必须对任务进行排队,形成一个队列的任务集合,这个队列的任务集合就是DAG图,每一个定点就是一个任务,每一条边代表一种限制约束(Spark中的依赖关系)。
Spark中DAG生成过程的重点是对Stage的划分,其划分的依据是RDD的依赖关系,对于不同的依赖关系,高层调度器会进行不同的处理。
对于窄依赖,RDD之间的数据不需要进行Shuffle,多个数据处理可以在同一台机器的内存中完成,所以窄依赖在Spark中被划分为同一个Stage;
对于宽依赖,由于Shuffle的存在,必须等到父RDD的Shuffle处理完成后,才能开始接下来的计算,所以会在此处进行Stage的切分。
在Spark中,DAG生成的流程关键在于回溯,在程序提交后,高层调度器将所有的RDD看成是一个Stage,然后对此Stage进行从后往前的回溯,遇到Shuffle就断开,遇到窄依赖,则归并到同一个Stage。等到所有的步骤回溯完成,便生成一个DAG图。
把DAG划分成互相依赖的多个Stage,划分依据是RDD之间的宽依赖,Stage是由一组并行的Task组成。Stage切割规则:从后往前,遇到宽依赖就切割Stage。
Stage计算模式:pipeline管道计算模式,pipeline只是一种计算思想、模式,来一条数据然后计算一条数据,把所有的逻辑走完,然后落地。准确的说:一个task处理一串分区的数据,整个计算逻辑全部走完。
4.7.3 Spark基本概念
官方文档:http://spark.apache.org/docs/2.4.5/cluster-overview.html#glossary
Spark Application运行时,涵盖很多概念,主要如下表格:
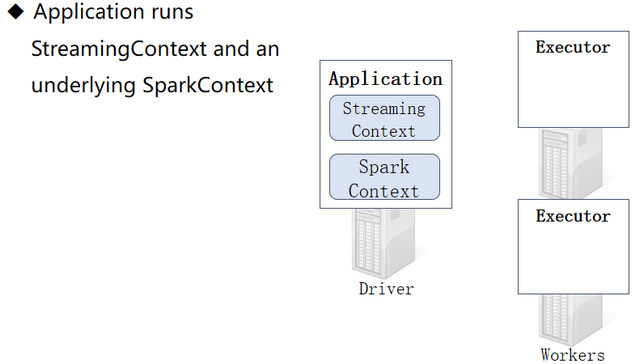
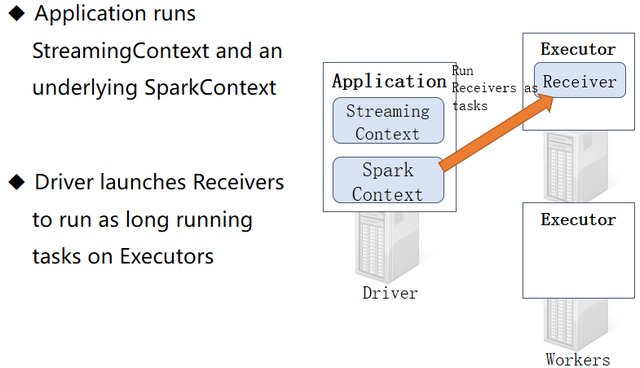
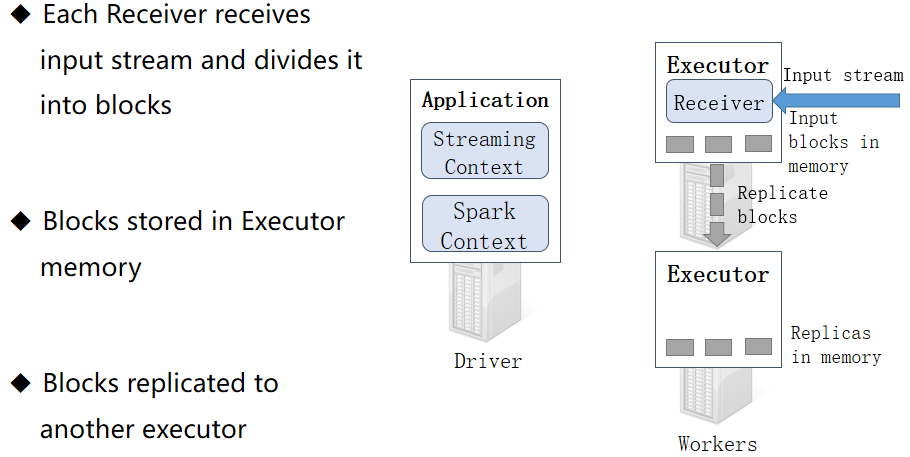
1.Application:应用,就是程序员编写的Spark代码,如WordCount代码
2.Driver:驱动,就是用来执行main方法的JVM进程,里面会执行一些Drive端的代码,如创建SparkContext,设置应用名,设置日志级别…
3.SparkContext:Spark运行时的上下文环境,用来和ClusterManager进行通信的,并进行资源的申请、任务的分配和监控等
4.ClusterManager:集群管理器,对于Standalone模式,就是Master,对于Yarn模式就是ResourceManager/ApplicationMaster,在集群上做统一的资源管理的进程
5.Worker:工作节点,是拥有CPU/内存的机器,是真正干活的节点
6.Executor:运行在Worker中的JVM进程!
7.RDD:弹性分布式数据集
8.DAG:有向无环图,就是根据Action形成的RDD的执行流程图—静态的图
9.Job:作业,按照DAG进行执行就形成了Job—按照图动态的执行
10.Stage:DAG中,根据shuffle依赖划分出来的一个个的执行阶段!
11.Task:一个分区上的一系列操作(pipline上的一系列操作)就是一个Task,同一个Stage中的多个Task可以并行执行!(每一个Task由线程执行),所以也可以这样说:Task(线程)是运行在Executor(进程)中的最小单位!
12.TaskSet:任务集,就是同一个Stage中的各个Task组成的集合!
4.7.4 Job调度流程
Spark运行基本流程
1.当一个Spark应用被提交时,首先需要为这个Spark Application构建基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext(还会构建DAGScheduler和TaskScheduler)
2.SparkContext向资源管理器注册并申请运行Executor资源;
3.资源管理器为Executor分配资源并启动Executor进程,Executor运行情况将随着心跳发送到资源管理器上;
4.SparkContext根据RDD的依赖关系构建成DAG图,并提交给DAGScheduler进行解析划分成Stage,并把该Stage中的Task组成的Taskset发送给TaskScheduler。
5.TaskScheduler将Task发放给Executor运行,同时SparkContext将应用程序代码发放给Executor。
6.Executor将Task丢入到线程池中执行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
Spark Application应用的用户代码都是基于RDD的一系列计算操作,实际运行时,这些计算操作是Lazy执行的,并不是所有的RDD操作都会触发Spark往Cluster上提交实际作业,基本上只有一些需要返回数据或者向外部输出的操作才会触发实际计算工作(Action算子),其它的变换操作基本上只是生成对应的RDD记录依赖关系(Transformation算子)。
当RDD调用Action函数(比如count、saveTextFile或foreachPartition)时,触发一个Job执行,调度中流程如下图所示:
Spark RDD通过其Transactions操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发Job并调度执行。
Spark的任务调度总体来说分两路进行:Stage级的调度和Task级的调度
DAGScheduler负责Stage级的调度,主要是将DAG依据RDD宽依赖切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。
TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。
一个Spark应用程序包括Job、Stage及Task:
Job/DAG是以Action方法为界,遇到一个Action方法则触发一个Job;
Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
4.7.5 扩展阅读:Spark并行度 4.7.5.1 资源并行度与数据并行度
在Spark Application运行时,并行度可以从两个方面理解:
1)、资源的并行度:由节点数(executor)和cpu数(core)决定的
2)、数据的并行度:task的数据,partition大小
task又分为map时的task和reduce(shuffle)时的task;
task的数目和很多因素有关,资源的总core数,spark.default.parallelism参数,spark.sql.shuffle.partitions参数,读取数据源的类型,shuffle方法的第二个参数,repartition的数目等等。
如果core有多少Task就有多少,那么有些比较快的task执行完了,一些资源就会处于等待的状态。
如果Task的数量多,能用的资源也多,那么并行度自然就好。
如果Task的数据少,资源很多,有一定的浪费,但是也还好。
如果Task数目很多,但是资源少,那么会执行完一批,再执行下一批。
所以官方给出的建议是,这个Task数目要是core总数的2-3倍为佳。
4.7.5.2 案例1
将Task/Partition/Parallelism数量设置成与Application总CPU Core 数量相同
150个core,理想情况,设置150 Task
与理想情况不同的是: 有些Task会运行快一点,比如50s就完了, 有些Task可能会慢一点,要一分半才运行完,
如果你的Task数量,刚好设置的跟CPU Core数量相同,也可能会导致资源的浪费,比如150 Task,10个先运行完了,剩余140个还在运行,但是这个时候,就有10个CPU Core空闲出来了,导致浪费。
如果设置2~3倍,那么一个Task运行完以后,另外一个Task马上补上来,尽量让CPU Core不要空闲。
所以,官方推荐,Task数量,设置成Application总CPU Core数量的2~3倍(150个cpu core,设置task数量为300~500
参数spark.defalut.parallelism默认是没有值的,如果设置了值,是在shuffle的过程才会起作用
4.7.5.3 案例2
当提交一个Spark Application时,设置资源信息如下,基本已经达到了集群或者yarn队列的资源上限:
Task设置为100个task ,平均分配一下,每个executor 分配到2个task,每个executor 剩下的一个cpu core 就浪费掉了!
虽然分配充足了,但是问题是:并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。合理的并行度的设置,应该要设置的足够大,大到可以完全合理的利用你的集群资源。可以调整Task数目,按照原则:Task数量,设置成Application总CPU Core数量的2~3倍
4.7.6 扩展阅读:Spark Shuffle
MapReduce框架中Shuffle过程,整体流程图如下:
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及到序列化反序列化、跨节点网络IO以及磁盘读写IO等。
Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是Child Stage的第一步。
执行Shuffle的主体是Stage中的并发任务,这些任务分ShuffleMapTask和ResultTask两种,ShuffleMapTask要进行Shuffle,ResultTask负责返回计算结果,一个Job中只有最后的Stage采用ResultTask,其他的均为ShuffleMapTask。如果要按照map端和reduce端来分析的话,ShuffleMapTask可以即是map端任务,又是reduce端任务,因为Spark中的Shuffle是可以串行的;ResultTask则只能充当reduce端任务的角色。
Spark在1.1以前的版本一直是采用Hash Shuffle的实现的方式,到1.1版本时参考Hadoop MapReduce的实现开始引入Sort Shuffle,在1.5版本时开始Tungsten钨丝计划,引入UnSafe Shuffle优化内存及CPU的使用,在1.6中将Tungsten统一到Sort Shuffle中,实现自我感知选择最佳Shuffle方式,到的2.0版本,Hash Shuffle已被删除,所有Shuffle方式全部统一到Sort Shuffle一个实现中。
5 Spark SQL 5.1 SparkSQL概述
Spark SQL允许开发人员直接处理RDD,同时可以查询在Hive上存储的外部数据。Spark SQL的一个重要特点就是能够统一处理关系表和RDD,使得开发人员可以轻松的使用SQL命令进行外部查询,同时进行更加复杂的数据分析。
5.1.1 前世今生
SparkSQL模块一直到Spark 2.0版本才算真正稳定,发挥其巨大功能,发展经历如下几个阶段。
5.1.1.1 Shark框架
首先回顾SQL On Hadoopp框架:Hive(可以说Hive时大数据生态系统中第一个SQL框架),架构如下所示:
可以发现Hive框架底层就是MapReduce,所以在Hive中执行SQL时,往往很慢很慢。
Spark出现以后,将HiveQL语句翻译成基于RDD操作,此时Shark框架诞生了。
Spark SQL的前身是Shark,它发布时Hive可以说是SQL on Hadoop的唯一选择(Hive负责将SQL编译成可扩展的MapReduce作业),鉴于Hive的性能以及与Spark的兼容,Shark由此而生。Shark即Hive on Spark,本质上是通过Hive的HQL进行解析,把HQL翻译成Spark上对应的RDD操作,然后通过Hive的Metadata获取数据库里表的信息,实际为HDFS上的数据和文件,最后有Shark获取并放到Spark上计算。
但是Shark框架更多是对Hive的改造,替换了Hive的物理执行引擎,使之有一个较快的处理速度。然而不容忽视的是Shark继承了大量的Hive代码,因此给优化和维护带来大量的麻烦。为了更好的发展,Databricks在2014年7月1日Spark Summit上宣布终止对Shark的开发,将重点放到SparkSQL模块上。
文档:https://databricks.com/blog/2014/07/01/shark-spark-sql-hive-on-spark-and-the-future-of-sql-on-spark.html
SparkSQL模块主要将以前依赖Hive框架代码实现的功能自己实现,称为Catalyst引擎。
5.1.1.2 SparkSQL模块
从Spark框架1.0开始发布SparkSQL模块开发,直到1.3版本发布SparkSQL Release版本可以在生产环境使用,此时数据结构为DataFrame = RDD + Schame。
1)、解决的问题
Spark SQL 执行计划和优化交给优化器 Catalyst;
内建了一套简单的SQL解析器,可以不使用HQL;
还引入和 DataFrame 这样的DSL API,完全可以不依赖任何 Hive 的组件;
2)、新的问题
对于初期版本的SparkSQL,依然有挺多问题,例如只能支持SQL的使用,不能很好的兼容命令式,入口不够统一等;
SparkSQL 在 1.6 时代,增加了一个新的API叫做 Dataset,Dataset 统一和结合了 SQL 的访问和命令式 API 的使用,这是一个划时代的进步。在 Dataset 中可以轻易的做到使用 SQL 查询并且筛选数据,然后使用命令式 API 进行探索式分析。
Spark 2.x发布时,将Dataset和DataFrame统一为一套API,以Dataset数据结构为主(Dataset = RDD + Schema),其中DataFrame = Dataset[Row]。
5.1.1.3 Hive与SparkSQL
从SparkSQL模块前世今生可以发现,从Hive框架衍生逐渐发展而来,Hive框架提供功能SparkSQL几乎全部都有,并且SparkSQL完全兼容Hive,从其加载数据进行处理。
Hive是将SQL转为MapReduce,SparkSQL可以理解成是将SQL解析成RDD + 优化再执行。
5.1.2 官方定义
SparkSQL模块官方定义:针对结构化数据处理Spark Module模块。
主要包含三层含义:
第一、针对结构化数据处理,属于Spark框架一个部分
结构化数据:一般指数据有固定的 Schema(约束),例如在用户表中,name 字段是 String 型,那么每一条数据的 name 字段值都可以当作 String 来使用;
schema信息,包含字段的名称和字段的类型,比如:JSON、XML、CSV、TSV、MySQL Table、ORC、Parquet,ES、MongoDB等都是结构化数据;
第二、抽象数据结构:DataFrame
将要处理的结构化数据封装在DataFrame中,来源Python数据分析库Pandas和R语言dataframe;
DataFrame = RDD + Schema信息;
第三、分布式SQL引擎,类似Hive框架
从Hive框架继承而来,Hive中提供bin/hive交互式SQL命令行及HiveServer2服务,SparkSQL都可以;
Spark SQL模块架构示意图如下:
5.1.3 SparkSQL特性
Spark SQL是Spark用来处理结构化数据的一个模块,主要四个特性:
第一、易整合
可以使用Java、Scala、Python、R等语言的API操作。
第二、统一的数据访问
连接到任何数据源的方式相同。
第三、兼容Hive
支持Hive HQL的语法,兼容hive(元数据库、SQL语法、UDF、序列化、反序列化机制)。
第四、标准的数据连接
可以使用行业标准的JDBC或ODBC连接。
SparkSQL模块官方文档:http://spark.apache.org/docs/2.4.5/sql-programming-guide.html
5.2 SparkSQL数据抽象 5.2.1 DataFrame 5.2.1.1 引入
就易用性而言,对比传统的MapReduce API,Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。
另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。
为了解决这一矛盾,Spark SQL 1.3.0在原有SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。
新的DataFrame AP不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分布式大数据场景。
注意:
DataFrame它不是Spark SQL提出来的,而是早期在R、Pandas语言就已经有了的。
5.2.1.2 DataFrame是什么
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行针对性的优化,最终达到大幅提升运行时效率。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
上图中左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而中间的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。了解了这些信息之后,Spark SQL的查询优化器就可以进行针对性的优化。后者由于在编译期有详尽的类型信息,编译期就可以编译出更加有针对性、更加优化的可执行代码。官方定义:
Dataset:A DataSet is a distributed collection of data. (分布式的数据集)
DataFrame: A DataFrame is a DataSet organized into named columns.(以列(列名,列类型,列值)的形式构成的分布式的数据集,按照列赋予不同的名称)
DataFrame有如下特性:
1 )、分布式的数据集,并且以列的方式组合的,相当于具有schema 的RDD;2 )、相当于关系型数据库中的表,但是底层有优化;3 )、提供了一些抽象的操作,如select 、filter 、aggregation、plot;4 )、它是由于R语言或者Pandas语言处理小数据集的经验应用到处理分布式大数据集上;5 )、在1.3 版本之前,叫SchemaRDD;
5.2.1.3 Schema信息
查看DataFrame中Schema是什么,执行如下命令:
Schema信息封装在StructType中,包含很多StructField对象,源码。
StructType 定义,是一个样例类,属性为StructField的数组
StructField 定义,同样是一个样例类,有四个属性,其中字段名称和类型为必填
自定义Schema结构,官方提供的示例代码:
5.2.1.4 Row
DataFrame中每条数据封装在Row中,Row表示每行数据
如何构建Row对象:要么是传递value,要么传递Seq,官方实例代码:
import org.apache.spark.sql._Row(value1 , value2 , value3 , ... ) Row .Seq(Seq(value1 , value2 , ... ) )
如何获取Row中每个字段的值呢????
方式一:下标获取,从0开始,类似数组下标获取
方式二:指定下标,知道类型
方式三:通过As转换类型
5.2.2 DataSet 5.2.2.1 引入
Spark在Spark 1.3版本中引入了Dataframe,DataFrame是组织到命名列中的分布式数据集合,但是有如下几点限制:
编译时类型不安全:
Dataframe API不支持编译时安全性,这限制了在结构不知道时操纵数据。
以下示例在编译期间有效。但是,执行此代码时将出现运行时异常。
无法对域对象(丢失域对象)进行操作:
将域对象转换为DataFrame后,无法从中重新生成它;
下面的示例中,一旦我们从personRDD创建personDF,将不会恢复Person类的原始RDD(RDD [Person]);
基于上述的两点,从Spark 1.6开始出现Dataset,至Spark 2.0中将DataFrame与Dataset合并,其中DataFrame为Dataset特殊类型,类型为Row。
针对RDD、DataFrame与Dataset三者编程比较来说,Dataset API无论语法错误和分析错误在编译时都能发现,然而RDD和DataFrame有的需要在运行时才能发现。
此外RDD与Dataset相比较而言,由于Dataset数据使用特殊编码,所以在存储数据时更加节省内存。
总结:
Dataset是在Spark1.6中添加的新的接口,是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。
与RDD相比:保存了更多的描述信息,概念上等同于关系型数据库中的二维表;
与DataFrame相比:保存了类型信息,是强类型的,提供了编译时类型检查,调用Dataset的方法先会生成逻辑计划,然后被Spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行;
5.2.2.2 DataSet是什么
Dataset是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换。
从Spark 2.0开始,DataFrame与Dataset合并,每个Dataset也有一个被称为一个DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。
Dataset API是DataFrames的扩展,它提供了一种类型安全的,面向对象的编程接口。它是一个强类型,不可变的对象集合,映射到关系模式。在数据集的核心 API是一个称为编码器的新概念,它负责在JVM对象和表格表示之间进行转换。表格表示使用Spark内部Tungsten二进制格式存储,允许对序列化数据进行操作并提高内存利用率。Spark 1.6支持自动生成各种类型的编码器,包括基本类型(例如String,Integer,Long),Scala案例类和Java Bean。
Spark 框架从最初的数据结构RDD、到SparkSQL中针对结构化数据封装的数据结构DataFrame,最终使用Dataset数据集进行封装,发展流程如下。
所以在实际项目中建议使用Dataset进行数据封装,数据分析性能和数据存储更加好。
5.2.3 RDD、DataFrame和DataSet
SparkSQL中常见面试题:如何理解Spark中三种数据结构RDD、DataFrame和Dataset关系?
第一、数据结构RDD:
RDD(Resilient Distributed Datasets)叫做弹性分布式数据集,是Spark中最基本的数据抽象,源码中是一个抽象类,代表一个不可变、可分区、里面的元素可并行计算的集合。
编译时类型安全,但是无论是集群间的通信,还是IO操作都需要对对象的结构和数据进行序列化和反序列化,还存在较大的GC的性能开销,会频繁的创建和销毁对象。
第二、数据结构DataFrame:
与RDD类似,DataFrame是一个分布式数据容器,不过它更像数据库中的二维表格,除了数据之外,还记录这数据的结构信息(即schema)。
DataFrame也是懒执行的,性能上要比RDD高(主要因为执行计划得到了优化)。
由于DataFrame每一行的数据结构一样,且存在schema中,Spark通过schema就能读懂数据,因此在通信和IO时只需要序列化和反序列化数据,而结构部分不用。
Spark能够以二进制的形式序列化数据到JVM堆以外(off-heap:非堆)的内存,这些内存直接受操作系统管理,也就不再受JVM的限制和GC的困扰了。但是DataFrame不是类型安全的。
第三、数据结构Dataset:
Dataset是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。
DataFrame=Dataset[Row](Row表示表结构信息的类型),DataFrame只知道字段,但是不知道字段类型,而Dataset是强类型的,不仅仅知道字段,而且知道字段类型。
样例类CaseClass被用来在Dataset中定义数据的结构信息,样例类中的每个属性名称直接对应到Dataset中的字段名称。
Dataset具有类型安全检查,也具有DataFrame的查询优化特性,还支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
5.2.4 入门案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 object SparkSQLDemo01_hello {"hello" ).master("local[*]" ).getOrCreate()"WARN" )"data/input/person.json" )"name" ).show(3)* * -- age: long (nullable = true) |-- hobby: string (nullable = true) |-- name: string (nullable = true) +---+----------+-------+ |age |hobby |name |23 |running |json |32 |basketball |charles |28 |football |tom | name | json |charles | tom |* /
5.3 RDD、DF、DS相关操作
实际项目开发中,往往需要将RDD数据集转换为DataFrame,本质上就是给RDD加上Schema信息,官方提供两种方式:类型推断和自定义Schema。
官方文档:http://spark.apache.org/docs/2.4.5/sql-getting-started.html#interoperating-with-rdds
5.3.1 获取DataFrame/DataSet 5.3.1.1 使用样例类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 object SparkSQLDemo02_CreateDFDS {"hello" ).master("local[*]" ).getOrCreate()"WARN" )"data/input/person.txt" )" " )* * -- id: integer (nullable = false) |-- name: string (nullable = true) |-- age: integer (nullable = false) +---+--------+---+ | id | name |age | 1 |zhangsan | 20 | 2 | lisi | 29 | 3 | wangwu | 25 | 4 | zhaoliu | 30 | 5 | tianqi | 35 | 6 | kobe | 40 |-- id: integer (nullable = false) |-- name: string (nullable = true) |-- age: integer (nullable = false) +---+--------+---+ | id | name |age | 1 |zhangsan | 20 | 2 | lisi | 29 | 3 | wangwu | 25 | 4 | zhaoliu | 30 | 5 | tianqi | 35 | 6 | kobe | 40 |* /
5.3.1.2 指定类型+列名 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 object SparkSQLDemo02_CreateDFDS2 {"hello" ).master("local[*]" ).getOrCreate()"WARN" )"data/input/person.txt" )" " )"id" ,"name" ,"age" )* * -- id: integer (nullable = false) |-- name: string (nullable = true) |-- age: integer (nullable = false) +---+--------+---+ | id | name |age | 1 |zhangsan | 20 | 2 | lisi | 29 | 3 | wangwu | 25 | 4 | zhaoliu | 30 | 5 | tianqi | 35 | 6 | kobe | 40 |* /
5.3.1.3 自定义Schema 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 object SparkSQLDemo02_CreateDFDS3 {"hello" ).master("local[*]" ).getOrCreate()"WARN" )"data/input/person.txt" )" " )* val schema: StructType = StructType("id" , IntegerType, true) ::"name" , StringType, true) ::"age" , IntegerType, true) :: Nil)* /"id" , IntegerType, true),"name" , StringType, true),"age" , IntegerType, true)* * -- id: integer (nullable = true) |-- name: string (nullable = true) |-- age: integer (nullable = true) +---+--------+---+ | id | name |age | 1 |zhangsan | 20 | 2 | lisi | 29 | 3 | wangwu | 25 | 4 | zhaoliu | 30 | 5 | tianqi | 35 | 6 | kobe | 40 |* /
5.3.2 RDD、DF、DS相互转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 object SparkSQLDemo03_Transformation {"hello" ).master("local[*]" ).getOrCreate()"WARN" )"data/input/person.txt" )" " )* * -- id: integer (nullable = false) |-- name: string (nullable = true) |-- age: integer (nullable = false) +---+--------+---+ | id | name |age | 1 |zhangsan | 20 | 2 | lisi | 29 | 3 | wangwu | 25 | 4 | zhaoliu | 30 | 5 | tianqi | 35 | 6 | kobe | 40 |-- id: integer (nullable = false) |-- name: string (nullable = true) |-- age: integer (nullable = false) +---+--------+---+ | id | name |age | 1 |zhangsan | 20 | 2 | lisi | 29 | 3 | wangwu | 25 | 4 | zhaoliu | 30 | 5 | tianqi | 35 | 6 | kobe | 40 |* /
5.4 SparkSQL数据处理分析
在SparkSQL模块中,将结构化数据封装到DataFrame或Dataset集合中后,提供两种方式分析处理数据,正如前面案例【词频统计WordCount】两种方式:
第一种:DSL(domain-specific language)编程,调用DataFrame/Dataset API(函数),类似RDD中函数;
第二种:SQL 编程,将DataFrame/Dataset注册为临时视图或表,编写SQL语句,类似HiveQL;
两种方式底层转换为RDD操作,包括性能优化完全一致,在实际项目中语句不通的习惯及业务灵活选择。比如机器学习相关特征数据处理,习惯使用DSL编程;比如数据仓库中数据ETL和报表分析,习惯使用SQL编程。无论哪种方式,都是相通的,必须灵活使用掌握。
5.4.1 案例一 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 object SparkSQLDemo04_FlowerQuery {Array [String]): Unit = {1. 准备SparkSQL开发环境2. 获取RDDline => {Array [String] = line .split(" ")0 ).toInt, arr(1 ), arr(2 ).toInt)3. RDD->DataFrameimport spark.implicits._ //隐式转换4. 输出约束和类型show ()-1. 注册表-2. 各种查询1. 查看name 字段的数据sql ("select name from t_person").show (false )2. 查看 name 和age字段数据sql ("select name,age from t_person").show (false )3. 查询所有的name 和age,并将age+1 sql ("select name,age,age+1 from t_person").show (false )4. 过滤age大于等于25 的sql ("select id,name,age from t_person where age >= 25").show (false )5. 统计年龄大于30 的人数sql ("select count(*) from t_person where age > 30").show (false )6. 按年龄进行分组并统计相同年龄的人数sql ("select age,count(*) from t_person group by age").show (false )7. 查询姓名=张三的name = "zhangsan"sql ("select id,name,age from t_person where name='zhangsan'").show (false )sql (s"select id,name,age from t_person where name='${name}'").show (false )1. 查看name 字段的数据select (df.col("name")).show (false )import org.apache.spark.sql .functions ._select (col("name")).show (false )select ("name").show (false )2. 查看 name 和age字段数据select ("name", "age").show (false )3. 查询所有的name 和age,并将age+1 select ("name","age","age+1").show (false )//报错:没有"age+1"这个列名select ("name","age","age"+1 ).show (false )//报错:没有"age+1"这个列名select ($"name", $"age", $"age" + 1 ).show (false ) //$"age"表示获取该列的值/$"列名"表示将该列名字符串转为列对象select ('name, ' age, 'age + 1).show(false) //' 列名表示将该列名字符串转为列对象4. 过滤age大于等于25 的filter ("age >= 25").show (false )where ("age >= 25").show (false )5. 统计年龄大于30 的人数filter ("age > 30").count()6. 按年龄进行分组并统计相同年龄的人数show (false )7. 查询姓名=张三的filter ("name ='zhangsan'").show (false )where ("name ='zhangsan'").show (false )filter ($"name" === "zhangsan").show (false )filter ('name === "zhangsan").show(false) //=8.查询姓名!=张三的 df.filter($"name" =!= name).show(false) df.filter(' name =!= "zhangsan").show (false )5. 关闭资源case class Person(id: Int , name : String, age: Int )
5.4.2 案例二:WordCount 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 object SparkSQLDemo05_WordCount def main Array [String ]): Unit = {val spark: SparkSession = SparkSession .builder().appName("hello" ).master("local[*]" ).getOrCreate()val sc: SparkContext = spark.sparkContext"WARN" )import spark.implicits._val fileRDD: RDD [String ] = sc.textFile("data/input/words.txt" )val df: DataFrame = fileRDD.toDF("value" )val ds: Dataset [String ] = df.as[String ]false )false )val df2: DataFrame = spark.read.text("data/input/words.txt" )false )val ds2: Dataset [String ] = spark.read.textFile("data/input/words.txt" )false )val wordDS: Dataset [String ] = ds.flatMap(_.split(" " ))false )"t_words" )val sql: String =""" |select value as word,count(*) as counts |from t_words |group by word |order by counts desc |""" .stripMarginfalse )"value" )'count .desc)false )case class Person (id: Int , name: String , age: Int )}
5.4.3 案例三:电影评分数据分析
数据
196 242 3 881250949 186 302 3 891717742 22 377 1 878887116 244 51 2 880606923 166 346 1 886397596 298 474 4 884182806 115 265 2 881171488 253 465 5 891628467 305 451 3 886324817 6 86 3 883603013 62 257 2 879372434 286 1014 5 879781125
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 object SparkSQLDemo06_MovieTop10 def main Array [String ]): Unit = {val spark: SparkSession = SparkSession .builder().appName("hello" ).master("local[*]" ).getOrCreate()val sc: SparkContext = spark.sparkContext"WARN" )import spark.implicits._val fileDS: Dataset [String ] = spark.read.textFile("data/input/rating_100k.data" )val rowDS: Dataset [(Int , Int )] = fileDS.map(line => {val arr: Array [String ] = line.split("\t" )1 ).toInt, arr(2 ).toInt)val cleanDF: DataFrame = rowDS.toDF("mid" ,"score" )false )"t_scores" )val sql:String =""" |select mid, round(avg(score),2) avg,count(*) counts |from t_scores |group by mid |having counts > 200 |order by avg desc,counts desc |limit 10 |""" .stripMarginfalse )import org.apache.spark.sql.functions._"mid" )'score ),2 ) as "avg" ,'mid ) as "counts" 'avg .desc,'counts .desc)'counts > 200 )10 )false )
5.5 自定义UDF函数
无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在org.apache.spark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
回顾Hive中自定义函数有三种类型:
第一种:UDF(User-Defined-Function) 函数
一对一的关系,输入一个值经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
第二种:UDAF(User-Defined Aggregation Function) 聚合函数
多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;
第三种:UDTF(User-Defined Table-Generating Functions) 函数
一对多的关系,输入一个值输出多个值(一行变为多行);
用户自定义生成函数,有点像flatMap;
注意
目前来说Spark 框架各个版本及各种语言对自定义函数的支持:
在SparkSQL中,目前仅仅支持UDF函数和UDAF函数:
UDF函数:一对一关系;UDAF函数:聚合函数,通常与group by 分组函数连用,多对一关系;
由于SparkSQL数据分析有两种方式:DSL编程和SQL编程,所以定义UDF函数也有两种方式,不同方式可以在不同分析中使用。
SQL方式 :使用SparkSession中udf方法定义和注册函数,在SQL中使用,使用如下方式定义:
DSL方式 :使用org.apache.sql.functions.udf函数定义和注册函数,在DSL中使用,如下方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 object SparkSQLDemo08_UDF {Array [String ]): Unit = {val spark: SparkSession = SparkSession .builder().appName("hello" ).master("local[*]" ).getOrCreate()val sc: SparkContext = spark.sparkContext"WARN" )val df: DataFrame = spark.read.text("data/input/udf.txt" )false )"small2big" ,(value:String )=>{"t_words" )val sql =""" |select value,small2big(value) big_value |from t_words |""" .stripMarginfalse )val small2big2 = udf((value:String )=>{'value,small2big2(' value).as ("big_value2" )).show(false )
5.6 External DataSource 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 object SparkSQLDemo07_datasource {main (args: Array[String]): Unit = {1 .准备SparkSQL开发环境builder ().appName ("hello" ).master ("local[*]" ).getOrCreate ()setLogLevel ("WARN" )1 :RDD-->DF/DS:兼容之前的RDD的项目2 :直接读取为DF/DS:优先考虑使用,支持多种数据源/数据格式:json/csv/parquet/jdbc....2 .准备一个DFtextFile ("data/input/person.txt" )map (line => {split (" " )Person (arr (0 ).toInt, arr (1 ), arr (2 ).toInt).implicits ._ //隐式转换toDF ()printSchema ()show (false)3 .写coalesce (1 ).write.mode (SaveMode.Overwrite)text ("data/output/text" )//注意:往普通文件写不支持Schemacoalesce (1 ).write.mode (SaveMode.Overwrite)json ("data/output/json" )coalesce (1 ).write.mode (SaveMode.Overwrite)csv ("data/output/csv" )coalesce (1 ).write.mode (SaveMode.Overwrite)parquet ("data/output/parquet" )Properties ()setProperty ("user" ,"root" )setProperty ("password" ,"123456" )coalesce (1 ).write.mode (SaveMode.Overwrite)jdbc ("jdbc:mysql://192.168.88.161:3306/bigdata?characterEncoding=UTF-8" ,"person" ,prop)//表会自动创建4 .读text ("data/output/text" ).show (false)json ("data/output/json" ).show (false)csv ("data/output/csv" ).toDF ("id1" ,"name1" ,"age1" ).show (false)parquet ("data/output/parquet" ).show (false)jdbc ("jdbc:mysql://192.168.88.161:3306/bigdata?characterEncoding=UTF-8" ,"person" ,prop).show (false)5 .关闭资源stop ()stop ()
5.7 Spark On Hive
Spark SQL模块从发展来说,从Apache Hive框架而来,发展历程:Hive(MapReduce)-> Shark (Hive on Spark) -> Spark SQL(SchemaRDD -> DataFrame -> Dataset),所以SparkSQL天然无缝集成Hive,可以加载Hive表数据进行分析。
http://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
5.7.1 HiveOnSpark和SparkOnHive
HiveOnSpark:SparkSql诞生之前的Shark项目使用的,是把Hive的执行引擎换成Spark,剩下的使用Hive的,严重依赖Hive,早就淘汰了没有人用了
SparkOnHive:SparkSQL诞生之后,Spark提出的,是仅仅使用Hive的元数据(库/表/字段/位置等信息…),剩下的用SparkSQL的,如:执行引擎,语法解析,物理执行计划,SQL优化
5.7.2 SparkOnHive如何On 5.7.2.1 命令行整合
1.启动Hive的元数据库服务
nohup /export/ servers// hive/bin/ hive --service metastore &
2.告诉SparkSQL:Hive的元数据库在哪里
要在哪一台机器上使用SparkOnHive就把配置文件放到哪台
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 cd /export/servers//spark/conf/<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration > <property > <name > hive.metastore.warehouse.dir</name > <value > /user/hive/warehouse</value > </property > <property > <name > hive.metastore.local</name > <value > false</value > </property > <property > <name > hive.metastore.uris</name > <value > thrift://node3:9083</value > </property > </configuration >
也可以将hive-site.xml分发到集群中所有Spark的conf目录,此时任意机器启动应用都可以访问Hive表数据。
scp -r /export/ servers// spark/conf/ hive-site.xml root@node2:$PWD /export/ servers// spark/conf/ hive-site.xml root@node3:$PWD
3.使用sparksql操作hive
启动spark-sql命令行
/export/servers//spark/bin/spark-sql show database ;show tables ;CREATE TABLE person3 (id int , name string, age int ) row format delimited fields terminated by ' ' ;LOAD DATA LOCAL INPATH 'file:///root/person.txt' INTO TABLE person3;show tables ;select * from person3;
vim /root/person.txt1 zhangsan 20 2 lisi 29 3 wangwu 25 4 zhaoliu 30 5 tianqi 35 6 kobe 40
5.7.2.2 代码中整合
开启hive元数据库
nohup /export/ servers// hive/bin/ hive --service metastore &
pom
<dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-hive_2.11</artifactId > <version > $ {spark.version} </version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-hive-thriftserver_2.11</artifactId > <version > $ {spark.version} </version > </dependency >
在代码中告诉SparkSQL:Hive的元数据服务的配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 object SparkSQLDemo09_SparkOnHive {Array [String]): Unit = {1. 准备SparkSQL开发环境200 ,本地测试给少一点import org.apache.spark.sql .functions ._import spark.implicits._2. 执行Hive-SQL show database ;show tables ;CREATE TABLE person3 (id int , name string, age int ) row format delimited fields terminated by ' ' ;LOAD DATA LOCAL INPATH 'file:///root/person.txt' INTO TABLE person3;show tables ;select * from person;sql ("show databases").show (false )sql ("show tables").show (false )sql ("CREATE TABLE person6 (id int, name string, age int) row format delimited fields terminated by ' '")sql ("LOAD DATA LOCAL INPATH 'file:///D:/person.txt' INTO TABLE person5")sql ("show tables").show (false )sql ("select * from person5").show (false )5. 关闭资源
5.8 分布式SQL引擎
Hive或SparkSQL在企业中应该是作为一个分布式SQL执行/查询引擎存在的!
回忆之前Hive的访问方式:
通过Hive命令行访问: /export/servers//hive/bin/hive
启动HiveServer2/thriftserver使用beeline访问:
SparkSQL访问
SparkSQL命令行
SparkSQL代码中访问
启动sparkSQL的thriftserver使用beeline访问
使用JDBC协议访问
5.8.1 通过thriftServer+beeline访问
1.启动SaprkSQL的thriftserver--类似与Hive的HiveServer2
node1上启动
/export/servers.server2 .thrift .port=10000 \.server2 .thrift .bind .host=node1 \[2]
在实际大数据分析项目中,使用SparkSQL时,往往启动一个ThriftServer服务,分配较多资源(Executor数目和内存、CPU),不同的用户启动beeline客户端连接,编写SQL语句分析数据。
停止使用:
/export/ servers// spark/sbin/ stop-thriftserver.sh
监控WEB UI界面:http://node1:4040/jobs/
2.启动beeline,所有机器都可以
/export/ servers// spark/bin/ beeline
3.连接SaprkSQL的thriftserver
/export/ servers// spark/bin/ beeline// node1:10000 123456
4.执行sql
show database ;show tables ;select * from person;
5.注意:
看上去像是在操作Hive,但本质是使用SparkSQL的thriftserver在操作Hive,写的Hive的SQL,但执行的Spark引擎!
如果感觉乱,记住一句话:
只有元数据使用的Hive的,剩下的全部使用Spark的!
5.8.2 通过JDBC协议访问 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 object SparkSQLDemo10_ThriftJDBC def main Array [String ]): Unit = {Class .forName("org.apache.hive.jdbc.HiveDriver" ) val conn: Connection = DriverManager .getConnection("jdbc:hive2://node1:10000/default" , "root" ,"123456" val sqlStr: String =""" |select * from person3 """ .stripMarginval ps: PreparedStatement = conn.prepareStatement(sqlStr)val rs: ResultSet = ps.executeQuery()while (rs.next()) {s"id = ${rs.getInt(1)} , name = ${rs.getString(2)} , age = ${rs.getInt(3)} " )if (null != rs) rs.close()if (null != ps) ps.close()if (null != conn) conn.close()
记住一句话:
只有元数据使用的Hive的,剩下的全部使用Spark的(包括:语法解析,物理执行计划生成,SQL执行引擎,SQL优化)!
1.自己开发SparkSQL代码需要整合Hive, 直接在SparkSQL代码中使用即可(5.7.2.2)
2.写完的项目需要提供给别人访问里面的数据
启动Spark的ThriftServer(类似与HiveServer2)
然后让别人通过beeline或JDBC访问
3.自己学习测试时可以使用spark-sql命令行
6 Spark Streaming 6.1 Spark Streaming概述
在传统的数据处理过程中,我们往往先将数据存入数据库中,当需要的时候再去数据库中进行检索查询,将处理的结果返回给请求的用户;另外,MapReduce 这类大数据处理框架,更多应用在离线计算场景中。而对于一些实时性要求较高的场景,我们期望延迟在秒甚至毫秒级别,就需要引出一种新的数据计算结构——流式计算,对无边界的数据进行连续不断的处理、聚合和分析。
SparkStreaming是Spark之前的处理实时数据的实时计算组件/模块/框架
在Spark2.0的时候又推出来StructuredStreaming作为新的流式数据实时计算组件/模块/框架
官方是推荐使用StructuredStreaming,但是在实际开发中SparkStreaming使用的还是较多!,所以现在SparkStreaming和StructuredStreaming都得学
也就是说学完之后我们会掌握:SparkStreaming/StructuredStreaming/Flink 3套大数据实时处理框架!
但是在实际开发中的使用:
老的项目:SparkStreaming > StructuredStreaming > Flink==
新的项目:Flink > StructuredStreaming > SparkStreaming==
而之前的Storm早已淘汰!
6.1.1 Streaming 应用场景
如下的场景需求, 仅仅通过传统的批处理/离线处理/离线计算/处理历史数据是无法完成的:
1):电商实时大屏:每年双十一时,淘宝和京东实时订单销售额和产品数量大屏展示,要求:
数据量大,可能每秒钟上万甚至几十万订单量
2):商品推荐:京东和淘宝的商城在购物车、商品详情等地方都有商品推荐的模块,商品推荐的要求:
快速的处理, 加入购物车以后就需要迅速的进行推荐
数据量大
需要使用一些推荐算法
3):工业大数据:现在的工场中, 设备是可以联网的, 汇报自己的运行状态, 在应用层可以针对这些数据来分析运行状况和稳健程度, 展示工件完成情况, 运行情况等,工业大数据的需求:
快速响应, 及时预测问题
数据是以事件的形式动态的产品和汇报
因为是运行状态信息, 且一般都是几十上百台机器, 所以汇报的数据量很大
4):集群监控:一般的大型集群和平台, 都需要对其进行监控,监控的需求
要针对各种数据库, 包括 MySQL, HBase 等进行监控
上述展示场景需要实时对数据进行分析处理,属于大数据中的实时流式数据处理
6.1.2 Streaming计算模式
流式处理任务是大数据处理中很重要的一个分支,关于流式计算的框架也有很多,如比较出名的Storm流式处理框架,是由Nathan Marz等人于 2010 年最先开发,之后将Storm开源,成为 Apache 的顶级项目,Trident 对Storm进行了一个更高层次的抽象;另外由LinkedIn贡献给社区的 Samza 也是一种流处理解决方案,不过其构建严重依赖于另一个开源项目 Kafka。
Spark Streaming 构建在Spark的基础之上的实时流处理框架,随着Spark的发展,Spark Streaming和Structured Streaming也受到了越来越多的关注。
不同的流式处理框架有不同的特点,也适应不同的场景,主要有如下两种模式。
6.1.2.1 原生流处理(Native)/事件驱动模式:真正的实时
所有输入记录会一条接一条地被处理,上面提到的 Storm 和 Flink都是采用这种方式;
数据来一条就可以触发计算,处理一条
如Flink,Strom(已经淘汰,延迟低,吞吐量小)
但Flink还做了优化,平衡延迟和吞吐量,可以做到低延迟,高吞吐(可以设置缓冲块大小阈值/时间阈值毫秒级来触发)
6.1.2.2 微批处理(Batch):假实时
将输入的数据以某一时间间隔 T,切分成多个微批量数据,然后对每个批量数据进行处理,Spark Streaming 和 StructuredStreaming采用的是这种方式;
数据来一批处理一批:对于实时到来的数据,按照固定的时间间隔(一般是秒级,毫秒),进行划分批次,然后对各个批次的数据进行处理! 当数据源源不断到来,处理源源不断进行的时候, 整个过程就连续起来了,像是再做实时处理! 但本质上还是微批处理,如:SparkStreaming
也就是说SparkStreaming底层还是微批处理(执行引擎用的还是SparkCore)
后续的StructuredStreaming也是微批模式,只不过后续开始支持毫秒级的微批!
6.1.3 Spark Streaming计算思想
Spark Streaming是Spark生态系统当中一个重要的框架,它建立在Spark Core之上,下图也可以看出Sparking Streaming在Spark生态系统中地位。
官方定义Spark Streaming模块:
SparkStreaming是一个基于SparkCore之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。
对于Spark Streaming来说,将流式数据封装的数据结构:DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流,其实就是将流式数据按照时间间隔BatchInterval划分为很多Batch批次,针对每个Batch批次数据当做RDD进行快速分析和处理。
SparkStreaming模块对流式数据处理,介于Batch批处理和RealTime实时处理之间处理数据方式。
官网介绍
6.2 Spark Streaming数据抽象-DStream 6.2.1 DStream是什么
Spark Streaming的核心是DStream,DStream类似于RDD,它实质上一系列的RDD的集合,DStream可以按照秒、分等时间间隔将数据流进行批量的划分。
SparkCore:RDD
SparkSQL:DataFrame和DataSet, 底层之前是SchemaRDD, 后续新版本实现了RDD的功能+SQL操作,可以认为底层还是RDD
SparkStreaming:DStream,底层使用的也是RDD
如下图所示:将流式数据按照【X seconds】划分很多批次Batch,每个Batch数据封装到RDD中进行处理分析,最后每批次数据进行输出。
DStream代表了一种连续的数据流,要么从某种数据源提取数据,要么从其他数据流映射转换而来。DStream内部是由一系列连续的RDD组成的,每个RDD都包含了特定时间间隔内的一批数据,如下图所示:
SparkStreaming的DStream是对源源不断的流数据,按照固定的时间间隔(一般为秒级),进行微批划分而来的, 而每一个微批中的数据就一个RDD,这些个时间上连续的RDD就组成了DStream
DStream本质上是一个:一系列时间上连续的RDD(Seq[RDD]),DStream = Seq[RDD]。
DStream = Seq[RDD]
对DStream进行操作(如:flatMap/map/filter..)就是对其底层的RDD进行操作!
对RDD操作会返回新的RDD,所以对DStream进行操作也会返回新的DStream
通过WEB UI界面可知,对DStream调用函数操作,底层就是对RDD进行操作,发现很多时候DStream中函数与RDD中函数一样的。
DStream中每批次数据RDD在处理时,各个RDD之间存在依赖关系,DStream直接也有依赖关系,RDD具有容错性,那么DStream也具有容错性。
上图相关说明:
1):每一个椭圆形表示一个RDD
Spark Streaming将流式计算分解成多个Spark Job,对于每一时间段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。
6.2.2 DStream Operations
DStream的99%的API和RDD一样
不一样的API后面通过案例直接学习
大多数和RDD中的类似,有一些特殊的针对特定类型应用使用的函数,比如updateStateByKey状态函数、window窗口函数等,后续具体结合案例讲解。
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#transformations-on-dstreams
Transformation
Meaning
map(func)
对DStream中的各个元素进行func函数操作,然后返回一个新的DStream
flatMap(func)
与map方法类似,只不过各个输入项可以被输出为零个或多个输出项
filter(func)
过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream
union(otherStream)
将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream.
reduceByKey(func, [numTasks])
利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream
join(otherStream, [numTasks])
输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W)类型的DStream
transform(func)通过RDD-to-RDD函数作用于DStream中的各个RDD,可以是任意的操作,从而返回一个新的RDD
6.2.2.2 Output函数
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#output-operations-on-dstreams
Output Operation
Meaning
print()打印到控制台
saveAsTextFiles(prefix, [suffix])
保存流的内容为文本文件,文件名为”prefix-TIME_IN_MS[.suffix]”.
saveAsObjectFiles(prefix,[suffix])
保存流的内容为SequenceFile,文件名为 “prefix-TIME_IN_MS[.suffix]”.
saveAsHadoopFiles(prefix,[suffix])
保存流的内容为hadoop文件,文件名为”prefix-TIME_IN_MS[.suffix]”.
foreachRDD(func)对Dstream里面的每个RDD执行func
6.3 Spark Streaming实战 6.3.1 案例一:WordCount
1.在node1上安装nc命令
2.在node1启动客户端工具发送消息
http://spark.apache.org/docs/latest/streaming-programming-guide.html
从官方文档可知,提供两种方式构建StreamingContext实例对象,如下:
第一种方式:构建SparkConf对象
第二种方式:构建SparkContext对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 object SparkStreamingDemo01_WordCount {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val ssc: StreamingContext = new StreamingContext(sc ,Seconds(5) )val socketDStream: ReceiverInputDStream[String ] = ssc.socketTextStream("node1" ,9999) val resultDS: DStream[(String , Int )] = socketDStreamMap(_ .split (" " ) )1 ))ByKey(_ + _ ) () () Termination() true ,true )
运行上述词频统计案例,登录到WEB UI监控页面:http://localhost:4040/
查看相关监控信息。
其一、Streaming流式应用概要信息
运行结果监控截图:
每批次Batch数据处理总时间TD = 批次调度延迟时间SD + 批次数据处理时间PT
其二、性能衡量标准
SparkStreaming实时处理数据性能如何(是否可以实时处理数据)??如何衡量的呢??每批次数据处理时间TD <= BatchInterval每批次时间间隔
6.3.2 案例二:UpdatesStateByKey
对从Socket接收的数据做WordCount并要求能够和历史数据进行累加!
如:先发了一个spark,得到(spark,1) ,然后不管隔多久再发一个spark,得到(spark,2) ,也就是说要对数据的历史状态进行维护!
注意:可以使用如下API对状态进行维护
1.updateStateByKey
统计全局的key的状态,但是就算没有数据输入,他也会在每一个批次的时候返回之前的key的状态。假设5s产生一个批次的数据,那么5s的时候就会更新一次的key的值,然后返回。
这样的缺点就是,如果数据量太大的话,而且我们需要checkpoint数据,这样会占用较大的存储。
如果要使用updateStateByKey,就需要设置一个checkpoint目录,开启checkpoint机制。因为key的state是在内存维护的,如果宕机,则重启之后之前维护的状态就没有了,所以要长期保存它的话需要启用checkpoint,以便恢复数据。
2.mapWithState
也是用于全局统计key的状态,但是它如果没有数据输入,便不会返回之前的key的状态,有一点增量的感觉。
这样做的好处是,我们可以只是关心那些已经发生的变化的key,对于没有数据输入,则不会返回那些没有变化的key的数据。这样的话,即使数据量很大,checkpoint也不会像updateStateByKey那样,占用太多的存储。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 object SparkStreamingDemo02_UpdateStateByKey {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val ssc: StreamingContext = new StreamingContext(sc ,Seconds(5) )"./ckp" )val socketDStream: ReceiverInputDStream[String ] = ssc.socketTextStream("node1" ,9999) val mappingFunc = (word : String , current : Option [Int ], state : State [Int ]) => {val newState = current.getOrElse(0) + state.getOption.getOrElse(0) val output = (word, newState)val resultDS: DStream[(String , Int )] = socketDStreamMap(_ .split (" " ) )1 ))WithState(StateSpec.function (mappingFunc ) )() () Termination() true ,true )
6.3.3 案例三:状态恢复-扩展
在上面的基础之上,实现SparkStreaming程序停止之后再启动时还能够接着上次的结果进行累加
如:
先发送spark,得到spark,1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 object SparkStreamingDemo03_StateRecovery {val checkppintDir = "./ckp" val creatingFunc = () => {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val ssc: StreamingContext = new StreamingContext(sc ,Seconds(5) )"./ckp" )val socketDStream: ReceiverInputDStream[String ] = ssc.socketTextStream("node1" ,9999) val updateFunc = (currentValues :Seq [Int ],historyValue :Option [Int ])=> {if (currentValues.size > 0 ){val newState: Int = currentValues.sum + historyValue.getOrElse(0) Some(newState ) else {val resultDS: DStream[(String , Int )] = socketDStreamMap(_ .split (" " ) )1 ))StateByKey(updateFunc ) () [String ] ): Unit = {val ssc: StreamingContext = StreamingContext .OrCreate(checkppintDir ,creatingFunc ) val sc: SparkContext = ssc.sparkContextLogLevel("WARN" ) () Termination() true ,true )
6.3.4 案例四:窗口函数
使用窗口计算: 每隔5s(滑动间隔)计算最近10s(窗口长度)的数据!
回顾窗口:
窗口长度:要计算多久的数据
滑动间隔:每隔多久计算一次
窗口长度10s > 滑动间隔5s:每隔5s计算最近10s的数据--滑动窗口
窗口长度10s = 滑动间隔10s:每隔10s计算最近10s的数据--滚动窗口
窗口长度10s < 滑动间隔15s:每隔15s计算最近10s的数据--会丢失数据,开发不用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 object SparkStreamingDemo04_Window {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val ssc: StreamingContext = new StreamingContext(sc , Seconds(5) )val socketDStream: ReceiverInputDStream[String ] = ssc.socketTextStream("node1" , 9999) val resultDS: DStream[(String , Int )] = socketDStreamMap(_ .split (" " ) )1 ))ByKeyAndWindow((a : Int, b : Int) => a + b, Seconds(10) , Seconds(5) )() () Termination() true , true )
使用窗口计算模拟热搜排行榜:每隔10s计算最近20s的热搜排行榜!
注意:
DStream没有直接排序的方法!所以应该调用transform方法对DStream底层的RDD进行操作,调用RDD的排序方法!
transform(函数),该函数会作用到DStream底层的RDD上!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 object SparkStreamingDemo05_TopN {[String ] ): Unit = {val sparkConf: SparkConf = new SparkConf() .setAppName("wc" ) .setMaster("local[*]" ) val sc: SparkContext = new SparkContext(sparkConf ) LogLevel("WARN" ) val ssc: StreamingContext = new StreamingContext(sc , Seconds(5) )val socketDStream: ReceiverInputDStream[String ] = ssc.socketTextStream("node1" , 9999) val sortedDS: DStream[(String , Int )] = socketDStreamMap(_ .split (" " ) )1 ))ByKeyAndWindow((a : Int, b : Int) => a + b, Seconds(20) , Seconds(10) )val sortedRDD: RDD[(String , Int )] = rdd.sortBy(_ ._2 , false ) val arr: Array[(String , Int )] = sortedRDD.take(3 )"========top3-begin======" )"========top3-end======" )() () Termination() true , true )
6.3.6 案例六:自定义输出-foreachRDD
对上述案例的结果数据输出到控制台外的其他组件,如MySQL/HDFS
注意:
foreachRDD函数属于将DStream中结果数据RDD输出的操作,类似transform函数,针对每批次RDD数据操作,但无返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 /**2020 /11/ 17 14 :37 9999 发送的数据并做WordCount// 1 .准备环境"wc" )// 设置数据输出文件系统的算法版本为2 // https:// blog.csdn.net/u013332124/ article/details/ 92001346 "spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version" , "2" )"local[*]" )"WARN" )// batchDuration the time interval at which streaming data will be divided into batches// 将流数据划分为微批的时间间隔/微批划分的时间间隔5 ))// 2 .数据"node1" , 9999 )// 3 .做WordCount" " ))1 ))20 ), Seconds(10 ))3 ) // 在这里取top3,或再后面print的时候取print(3 )"========top3-begin======" )// 本地集合的输出"========top3-end======" )// 4 .使用自带API进行输出// 全部输出// 接下来可以使用自定义输出"yyyy-MM-dd HH:mm:ss" )// 注意:df.format(Date,Timestamp,Long等类型)"-------------------------------------------" )"Time: ${formatTimeStr}" )"-------------------------------------------" )if (!rdd.isEmpty()) { // 当前批次数据不为空才输出// 自定义输出:// 1 .输出到控制台// 2 .输出到HDFS1 ).saveAsTextFile(s"hdfs://node1:8020/wordcount/output-${System.currentTimeMillis()}" )// 3 .输出到MySQL255 ) NOT NULL,11 ) DEFAULT NULL,1 ).foreachPartition(iter => {// 开启连接"jdbc:mysql://192.168.88.161:3306/bigdata?characterEncoding=UTF-8" , "root" , "123456" )// REPLACE INTO:表示如果有就删除再重新插入新的(相当于更新),如果没有则插入"REPLACE INTO `bigdata`.`t_words` (`word`, `count`) VALUES (?, ?);" 1 , t._1)2 , t._2)// 关闭连接// 5 .启动并等待结束// 流程序需要启动// 流程序会一直运行等待数据到来或手动停止// 是否停止sc,是否优雅停机// 注意:// 先启动nc -lk 9999 // 再启动程序
6.4 Spark Streaming整合kafka
在实际项目中,无论使用Storm还是SparkStreaming与Flink,主要从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下:
技术栈: Flume/SDK/Kafka Producer API -> KafKa —> SparkStreaming/Flink/Storm(Hadoop YARN) -> Redis -> UI
1)、阿里工具Canal:监控MySQL数据库binlog文件,将数据同步发送到Kafka Topic中
https://gi thub.com/alibaba/ canal//gi thub.com/alibaba/ canal/wiki/ QuickStart
2)、Maxwell:实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。
http://m axwells-daemon.io///gi thub.com/zendesk/m axwell
扩展:Kafka 相关常见面试题:
1)、Kafka 集群大小(规模),Topic分区函数名及集群配置?
Apache Kafka: 最原始功能【消息队列】,缓冲数据,具有发布订阅功能(类似微信公众号)。
6.4.1 整合说明 6.4.1.1 两种方式 6.4.1.1.1 Receiver-based Approach(Receiver接收器模式–淘汰)
1.KafkaUtils.createDstream基于接收器方式(和Socket使用的模式一样),消费Kafka数据,已淘汰,企业中不再使用;
2.Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦;
3.Receiver那台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低;
4.Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护;offset存储在Zookeeper已经淘汰了!因为Kafka的新版本自己都不用Zookeeper存offset了,而使用默认主题__consumer_offsets
5.Spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致;
6.4.1.1.2 Direct Approach (No Receivers)(Direct直连模式:–开发中使用)
1.KafkaUtils.createDirectStream直连方式,Streaming中每批次的每个job直接调用Simple Consumer API获取对应Topic数据,此种方式使用最多,面试时被问的最多;
2.Direct方式是直接连接kafka的各个分区来获取数据,从每个分区直接读取数据大大提高并行能力
3.Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中并(当然Kafka自己也存一份默认主题,方便外部监控),消除了与zk不一致的情况 ;
4.当然也可以自己手动维护,把offset存在MySQL/Redis中;
6.4.1.2 两个版本API
Spark Streaming与Kafka集成,有两套API,原因在于Kafka Consumer API有两套,文档:
http://spark.apache.org/docs/2.4.5/streaming-kafka-integration.html
1.Kafka 0.8.x版本 -早已淘汰
底层使用老的KafkaAPI:Old Kafka Consumer API
支持Receiver(已淘汰)和Direct模式:
2.Kafka 0.10.x版本-开发中使用
底层使用新的KafkaAPI: New Kafka Consumer API
只支持Direct模式
6.4.2 整合Kafka 0-10 (开发使用) 6.4.2.1 原理
目前企业中基本都使用New Consumer API集成,优势如下:1.Direct方式
直接到Kafka Topic中依据偏移量范围获取数据,进行处理分析;
The Spark Streaming integration for Kafka 0.10 is similar in design to the 0.8 Direct Stream approach;
2.简单的并行度1:1
每批次中RDD的分区与Topic分区一对一关系;
It provides simple parallelism, 1:1 correspondence between Kafka partitions and Spark partitions, and access to offsets and metadata;
获取Topic中数据的同时,还可以获取偏移量和元数据信息;
采用Direct方式消费数据时,可以设置每批次处理数据的最大量,防止【波峰】时数据太多,导致批次数据处理有性能问题:
参数:spark.streaming.kafka.maxRatePerPartition
含义:Topic中每个分区每秒中消费数据的最大值
举例说明:
BatchInterval:5s、Topic-Partition:3、maxRatePerPartition: 10000
最大消费数据量:10000 * 3 * 5 = 150000 条
6.4.2.2 API
http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html#obtaining-offsets
添加相关Maven依赖:
<dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-streaming-kafka-0-10_2.11</artifactId > <version > ${spark.version}</version > </dependency >
注意
6.4.2.3 代码实现:自动提交偏移量到默认主题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 /**2020 /11/ 17 14 :37 0 -10 版本-自动提交offset到Checkpoint和默认主题// 1 .准备环境"wc" ).setMaster("local[*]" )"WARN" )5 ))"./ckp" )// 2 .从Kafka数据// 准备连接参数"bootstrap.servers" -> "node1:9092" ,"key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "sparkstreaming" ,// earliest:表示如果有offset记录从offset记录开始消费,如果没有从最早的消息开始消费// latest:表示如果有offset记录从offset记录开始消费,如果没有从最后/最新的消息开始消费// none:表示如果有offset记录从offset记录开始消费,如果没有就报错"auto.offset.reset" -> "latest" ,"auto.commit.interval.ms" ->"1000" ,// 自动提交的时间间隔"enable.auto.commit" -> (true: java.lang.Boolean)// 是否自动提交偏移量// 准备连接的参数:主题"spark_kafka" )// 使用工具类+参数连接Kafka// ConsumerRecord:表示从Kafka中消费到的一条条的消息// 位置策略,使用源码中推荐的均匀一致的分配策略// 消费策略,使用源码中推荐的订阅模式// 获取记录中的详细信息// 输出// 启动并等待结束// 流程序需要启动// 流程序会一直运行等待数据到来或手动停止// 是否停止sc,是否优雅停机1 .准备主题/export/ servers// kafka/bin/ kafka-topics.sh --list --zookeeper node1:2181 /export/ servers// kafka/bin/ kafka-topics.sh --zookeeper node1:2181 --delete --topic spark_kafka/export/ servers// kafka/bin/ kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic spark_kafka/export/ servers// kafka/bin/ kafka-topics.sh --list --zookeeper node1:2181 2 .启动控制台生产者/export/ servers// kafka/bin/ kafka-console-producer.sh --broker-list node1:9092 --topic spark_kafka3 .启动程序4 .发送消息
6.4.2.4 代码实现:手动提交偏移量到默认主题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 /**2020 /11/ 17 14 :37 0 -10 版本-手动提交offset到Checkpoint和默认主题// 1 .准备环境"wc" ).setMaster("local[*]" )"WARN" )5 ))"./ckp" )// 2 .从Kafka数据// 准备连接参数"bootstrap.servers" -> "node1:9092" ,"key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "sparkstreaming" ,// earliest:表示如果有offset记录从offset记录开始消费,如果没有从最早的消息开始消费// latest:表示如果有offset记录从offset记录开始消费,如果没有从最后/最新的消息开始消费// none:表示如果有offset记录从offset记录开始消费,如果没有就报错"auto.offset.reset" -> "latest" ,"enable.auto.commit" -> (false: java.lang.Boolean)// 是否自动提交偏移量// 准备连接的参数:主题"spark_kafka" )// 使用工具类+参数连接Kafka// ConsumerRecord:表示从Kafka中消费到的一条条的消息// 位置策略,使用源码中推荐的均匀一致的分配策略// 消费策略,使用源码中推荐的订阅模式// 注意:如果要手动提交,需要确定提交的时机// 1 .每隔多久提交一次offset,这个就和自动提交一样了,手动提交没必要这样写// 2 .接收一条提交一次,可以但是太频繁了// 3 .接收一批提交一次,比较合适// 注意:在SparkStreaming中,DStream底层的RDD就是一批批的数据// 所以可以对DStream底层的RDD进行操作,每处理一个RDD就表示处理了一批数据,就可以提交了if (!rdd.isEmpty()){// -1 .处理该批次的数据/该RDD中的数据--我们这里就直接使用输出表示处理完了"主题:${r.topic()},分区:${r.partition()},偏移量:${r.offset()},key:${r.key()},value:${r.value()}" )// val array: Array[ConsumerRecord[String, String]] = rdd.collect()// -2 .处理好之后提交offset// 原本应该将RDD中的主题/分区/ 偏移量等信息提取处理再提交,但是这样做麻烦// 所以官方提供一种方式,直接将RDD转为Array[OffsetRange]就可以直接提交了// offsetRanges里面存放的就是主题/分区/ 偏移量等信息// 提交主题/分区/ 偏移量等信息"主题/分区/偏移量等信息已手动提交到Checkpoint/默认主题中" )// 启动并等待结束// 流程序需要启动// 流程序会一直运行等待数据到来或手动停止// 是否停止sc,是否优雅停机1 .准备主题/export/ servers// kafka/bin/ kafka-topics.sh --list --zookeeper node1:2181 /export/ servers// kafka/bin/ kafka-topics.sh --zookeeper node1:2181 --delete --topic spark_kafka/export/ servers// kafka/bin/ kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic spark_kafka/export/ servers// kafka/bin/ kafka-topics.sh --list --zookeeper node1:2181 2 .启动控制台生产者/export/ servers// kafka/bin/ kafka-console-producer.sh --broker-list node1:9092 --topic spark_kafka3 .启动程序4 .发送消息
6.4.2.5 代码实现:手动提交偏移量到MySQL-扩展 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 /**2020 /11/ 17 14 :37 0 -10 版本-手动提交offset到MySQL/Redis/ HBase/// 1 .准备环境"wc" ).setMaster("local[*]" )"WARN" )5 ))"./ckp" )// 2 .从Kafka数据// 准备连接参数"bootstrap.servers" -> "node1:9092" ,"key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "sparkstreaming" ,// earliest:表示如果有offset记录从offset记录开始消费,如果没有从最早的消息开始消费// latest:表示如果有offset记录从offset记录开始消费,如果没有从最后/最新的消息开始消费// none:表示如果有offset记录从offset记录开始消费,如果没有就报错"auto.offset.reset" -> "latest" ,"enable.auto.commit" -> (false: java.lang.Boolean)// 是否自动提交偏移量// 准备连接的参数:主题"spark_kafka" )// TODO 注意:连接kafka之前应该要先从mysql中获取offset信息// Map[主题分区, offset]"sparkstreaming" ,"spark_kafka" )if (offsetMap.size > 0 ){"MySQL中存储了offset记录,从记录处开始消费" )// 位置策略,使用源码中推荐的均匀一致的分配策略// 消费策略,使用源码中推荐的订阅模式else {"MySQL中没有存储offset记录,从latest处开始消费" )// 位置策略,使用源码中推荐的均匀一致的分配策略// 消费策略,使用源码中推荐的订阅模式// 注意:如果要手动提交,需要确定提交的时机// 1 .每隔多久提交一次offset,这个就和自动提交一样了,手动提交没必要这样写// 2 .接收一条提交一次,可以但是太频繁了// 3 .接收一批提交一次,比较合适// 注意:在SparkStreaming中,DStream底层的RDD就是一批批的数据// 所以可以对DStream底层的RDD进行操作,每处理一个RDD就表示处理了一批数据,就可以提交了if (!rdd.isEmpty()){// -1 .处理该批次的数据/该RDD中的数据--我们这里就直接使用输出表示处理完了"主题:${r.topic()},分区:${r.partition()},偏移量:${r.offset()},key:${r.key()},value:${r.value()}" )// val array: Array[ConsumerRecord[String, String]] = rdd.collect()// -2 .处理好之后提交offset// 原本应该将RDD中的主题/分区/ 偏移量等信息提取处理再提交,但是这样做麻烦// 所以官方提供一种方式,直接将RDD转为Array[OffsetRange]就可以直接提交了// offsetRanges里面存放的就是主题/分区/ 偏移量等信息// 提交主题/分区/ 偏移量等信息// kafkaDS.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)// TODO ok"sparkstreaming" ,offsetRanges)"主题/分区/偏移量等信息已手动提交到MySQL中了" )// 启动并等待结束// 流程序需要启动// 流程序会一直运行等待数据到来或手动停止// 是否停止sc,是否优雅停机255 ) NOT NULL,11 ) NOT NULL,255 ) NOT NULL,20 ) DEFAULT NULL,// 1 .将偏移量保存到数据库"jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8" , "root" , "root" )// replace into表示之前有就替换,没有就插入"replace into t_offset (`topic`, `partition`, `groupid`, `offset`) values(?,?,?,?)" )for (o <- offsetRange) {1 , o.topic)2 , o.partition)3 , groupid)4 , o.untilOffset)// 2 .从数据库读取偏移量Map(主题分区,offset)"jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8" , "root" , "root" )"select * from t_offset where groupid=? and topic=?" )1 , groupid)2 , topic)// Map(主题分区,offset)while (rs.next ()) {"topic" ), rs.getInt("partition" )) -> rs.getLong("offset" )1 .准备主题/export/ servers// kafka/bin/ kafka-topics.sh --list --zookeeper node1:2181 /export/ servers// kafka/bin/ kafka-topics.sh --zookeeper node1:2181 --delete --topic spark_kafka/export/ servers// kafka/bin/ kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic spark_kafka/export/ servers// kafka/bin/ kafka-topics.sh --list --zookeeper node1:2181 2 .启动控制台生产者/export/ servers// kafka/bin/ kafka-console-producer.sh --broker-list node1:9092 --topic spark_kafka3 .启动程序4 .发送消息
注意:
开发时一般情况下使用自动即可
要求较高的话可以使用手动提交到:MySQL/Redis/HBase
面试时直接说:提交到MySQL/Redis/HBase!
6.5 扩展阅读 6.5.1 流式计算框架发展
经过这么多年的发展,大数据已经从大数据1.0的BI/Datawarehouse时代, 经过大数据2.0的Web/APP过渡, 进入到了IOT的大数据3.0时代,而随之而来的是数据架构的变化。
6.5.1.1 Lambda架构
在过去Lambda数据架构成为每一个公司大数据平台必备的架构,它解决了一个公司大数据批量离线处理和实时数据处理的需求。一个典型的Lambda架构如下:
数据从底层的数据源开始,经过各种各样的格式进入大数据平台,在大数据平台中经过Kafka、Flume等数据组件进行收集,然后分成两条线进行计算。
一条线进入流式计算平台(例如 Storm、Flink或者Spark Streaming),去计算实时的一些指标;
一条线进入批量数据处理离线计算平台(例如Mapreduce、Hive,Spark SQL),去计算T+1的相关业务指标,这些指标需要隔日才能看见。
Lambda架构经历多年的发展,其优点是稳定,对于实时计算部分的计算成本可控,批量处理可以用晚上的时间来整体批量计算,这样把实时计算和离线计算高峰分开,这种架构支撑了数据行业的早期发展,但是它也有一些致命缺点,并在大数据3.0时代越来越不适应数据分析业务的需求。缺点如下:
1 实时与批量计算结果不一致引起的数据口径问题:因为批量和实时计算走的是两个计算框架和计算程序,算出的结果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
6.5.1.2 Kappa架构
针对Lambda架构的需要维护两套程序等以上缺点,LinkedIn的Jay Kreps结合实际经验和个人体会提出了Kappa架构。
Kappa架构的核心思想是通过改进流计算系统来解决数据全量处理的问题,使得实时计算和批处理过程使用同一套代码。
此外Kappa架构认为只有在有必要的时候才会对历史数据进行重复计算,而如果需要重复计算时,Kappa架构下可以启动很多个实例进行重复计算。
一个典型的Kappa架构如下图所示:
Kappa架构的核心思想,包括以下三点:
1.用Kafka或者类似MQ队列系统收集各种各样的数据,你需要几天的数据量就保存几天。
2.当需要全量重新计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个新的结果存储中。
3.当新的实例做完后,停止老的流计算实例,并把老的一些结果删除。
Kappa架构的优点在于将实时和离线代码统一起来,方便维护而且统一了数据口径的问题。而Kappa的缺点也很明显:
流式处理对于历史数据的高吞吐量力不从心:所有的数据都通过流式计算,即便通过加大并发实例数亦很难适应IOT时代对数据查询响应的即时性要求。
开发周期长:此外Kappa架构下由于采集的数据格式的不统一,每次都需要开发不同的Streaming程序,导致开发周期长。
服务器成本浪费:Kappa架构的核心原理依赖于外部高性能存储redis,hbase服务。但是这2种系统组件,又并非设计来满足全量数据存储设计,对服务器成本严重浪费。
lambda 架构
kappa 架构
数据处理能力
可处理超大规模的历史数据
历史数据处理能力有限
机器开销
批处理和实时计算需一直运行,机器开销大
必要时进行全量计算,机器开销相对较小
存储开销
只需要保存一份查询结果,存储开销较小
需要存储新老实例结果,存储开销相对较大。但如果是多 Job 共用的集群,则只需要预留出一小部分的存储即可
开发、测试难易程度
实现两套代码,开发、测试难度较大
只需面对一个框架,开发、测试难度相对较小
运维成本
维护两套系统,运维成本大
只需维护一个框架,运维成本小
6.5.1.3 IOTA架构
而在IOT大潮下,智能手机、PC、智能硬件设备的计算能力越来越强,而业务需求要求数据实时响应需求能力也越来越强,过去传统的中心化、非实时化数据处理的思路已经不适应现在的大数据分析需求,提出新一代的大数据IOTA架构来解决上述问题
整体思路是设定标准数据模型,通过边缘计算技术把所有的计算过程分散在数据产生、计算和查询过程当中,以统一的数据模型贯穿始终,从而提高整体的预算效率,同时满足即时计算的需要,可以使用各种Ad-hoc Query(即席查询)来查询底层数据:
IOTA整体技术结构分为几部分:
1 Common Data Model:贯穿整体业务始终的数据模型,这个模型是整个业务的核心,要保持SDK、cache、历史数据、查询引擎保持一致。对于用户数据分析来讲可以定义为“主-谓-宾”或者“对象-事件”这样的抽象模型来满足各种各样的查询。以大家熟悉的APP用户模型为例,用“主-谓-宾”模型描述就是“X用户 – 事件1 – A页面(2018/4/11 20:00) ”。当然,根据业务需求的不同,也可以使用“产品-事件”、“地点-时间”模型等等。模型本身也可以根据协议(例如 protobuf)来实现SDK端定义,中央存储的方式。此处核心是,从SDK到存储到处理是统一的一个Common Data Model。
2 Edge SDKs & Edge Servers:这是数据的采集端,不仅仅是过去的简单的SDK,在复杂的计算情况下,会赋予SDK更复杂的计算,在设备端就转化为形成统一的数据模型来进行传送。例如对于智能Wi-Fi采集的数据,从AC端就变为“X用户的MAC 地址-出现- A楼层(2018/4/11 18:00)”这种主-谓-宾结构,对于摄像头会通过Edge AI Server,转化成为“X的Face特征- 进入- A火车站(2018/4/11 20:00)”。也可以是上面提到的简单的APP或者页面级别的“X用户 – 事件1 – A页面(2018/4/11 20:00) ”,对于APP和H5页面来讲,没有计算工作量,只要求埋点格式即可。
3 RealTime Data:实时数据缓存区,这部分是为了达到实时计算的目的,海量数据接收不可能海量实时入历史数据库,那样会出现建立索引延迟、历史数据碎片文件等问题。因此,有一个实时数据缓存区来存储最近几分钟或者几秒钟的数据。这块可以使用Kudu或者Hbase等组件来实现。这部分数据会通过Dumper来合并到历史数据当中。此处的数据模型和SDK端数据模型是保持一致的,都是Common Data Model,例如“主-谓-宾”模型。
4 Historical Data:历史数据沉浸区,这部分是保存了大量的历史数据,为了实现Ad-hoc查询,将自动建立相关索引提高整体历史数据查询效率,从而实现秒级复杂查询百亿条数据的反馈。例如可以使用HDFS存储历史数据,此处的数据模型依然SDK端数据模型是保持一致的Common Data Model。
5 Dumper:Dumper的主要工作就是把最近几秒或者几分钟的实时数据,根据汇聚规则、建立索引,存储到历史存储结构当中,可以使用map-reduce、C、Scala来撰写,把相关的数据从Realtime Data区写入Historical Data区。
6 Query Engine:查询引擎,提供统一的对外查询接口和协议(例如SQL JDBC),把Realtime Data和Historical Data合并到一起查询,从而实现对于数据实时的Ad-hoc查询。例如常见的计算引擎可以使用presto、impala、clickhouse等。
7 Realtime model feedback:通过Edge computing技术,在边缘端有更多的交互可以做,可以通过在Realtime Data去设定规则来对Edge SDK端进行控制,例如,数据上传的频次降低、语音控制的迅速反馈,某些条件和规则的触发等等。简单的事件处理,将通过本地的IOT端完成,例如,嫌疑犯的识别现在已经有很多摄像头本身带有此功能。
IOTA大数据架构,主要有如下几个特点:
1 去ETL化:ETL和相关开发一直是大数据处理的痛点,IOTA架构通过Common Data Model的设计,专注在某一个具体领域的数据计算,从而可以从SDK端开始计算,中央端只做采集、建立索引和查询,提高整体数据分析的效率。
2 Ad-hoc即时查询:鉴于整体的计算流程机制,在手机端、智能IOT事件发生之时,就可以直接传送到云端进入realtime data区,可以被前端的Query Engine来查询。此时用户可以使用各种各样的查询,直接查到前几秒发生的事件,而不用在等待ETL或者Streaming的数据研发和处理。
3 边缘计算(Edge-Computing):将过去统一到中央进行整体计算,分散到数据产生、存储和查询端,数据产生既符合Common Data Model。同时,也给与Realtime model feedback,让客户端传送数据的同时马上进行反馈,而不需要所有事件都要到中央端处理之后再进行下发。
如上图,IOTA架构有各种各样的实现方法,为了验证IOTA架构,很多公司也自主设计并实现了“秒算”引擎
在大数据3.0时代,Lambda大数据架构已经无法满足企业用户日常大数据分析和精益运营的需要,去ETL化的IOTA大数据架构也许才是未来。
6.5.2 SparkStreaming 原理深入
SparkStreaming处理流式数据时,按照时间间隔划分数据为微批次(Micro-Batch),每批次数据当做RDD,再进行处理分析。
以WordCount程序为例,讲解Streaming工作原理。
6.5.2.1 创建StreamingContext
当SparkStreaming流式应用启动(streamingContext.start)时,首先创建StreamingContext流式上下文实例对象,整个流式应用环境构建,底层还是SparkContext。
当StreamingContext对象构建以后,启动接收器Receiver,专门从数据源端接收数据,此接收器作为Task任务运行在Executor中,一直运行(Long Runing),一直接收数据。
从WEB UI界面【Jobs Tab】可以看到【Job-0】是一个Receiver接收器,一直在运行,以Task方式运行,需要1Core CPU。
可以从多个数据源端实时消费数据进行处理,例如从多个TCP Socket接收数据,对每批次数据进行词频统计,使用DStream#union函数合并接收数据流
val inputDStream01: DStream[String] = ssc.socketTextStream ("node1" , 9999 )[String] = ssc.socketTextStream ("node1" , 9988 )[String] = inputDStream01.union (inputDStream02)
6.5.2.2 接收器接收数据
启动每个接收器Receiver以后,实时从数据源端接收数据(比如TCP Socket),也是按照时间间隔将接收的流式数据划分为很多Block(块)。
接收器Receiver划分流式数据的时间间隔BlockInterval,默认值为200ms,通过属性【spark.streaming.blockInterval】设置。
接收器将接收的数据划分为Block以后,按照设置的存储级别对Block进行存储,从TCP Socket中接收数据默认的存储级别为:MEMORY_AND_DISK_SER_2,先存储内存,不足再存储磁盘,存储2副本。
从TCP Socket消费数据时可以设置Block存储级别,如下:
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream ("node1" , 9999 ,
6.5.2.3 汇报接收Block报告
接收器Receiver将实时汇报接收的数据对应的Block信息,当BatchInterval时间达到以后,StreamingContext将对应时间范围内数据block当做RDD,加载SparkContextt处理数据。
以此循环处理流式的数据,如下图所示:
6.5.2.4 Streaming 工作原理总述
整个Streaming运行过程中,涉及到两个时间间隔:
批次时间间隔:BatchInterval
每批次数据的时间间隔,每隔多久加载一个Job;
Block时间间隔:BlockInterval
接收器划分流式数据的时间间隔,默认值为200ms,可以调整通过spark.streaming.blockInterval进行调整,官方建议最小值不能小于50ms;
官方案例:
BatchInterval: 1 s = 1000 ms = 5 * BlockInterval5 个Block ,每个Block 就是RDD一个分区数据
从代码层面结合实际数据处理层面来看,Streaming处理原理如下,左边为代码逻辑,右边为实际每批次数据处理过程。
具体运行数据时,每批次数据依据代码逻辑执行。
流式数据流图如下:
6.5.3 流式应用状态处理
使用SparkStreaming处理实际实时应用业务时,针对不同业务需求,需要使用不同的函数。SparkStreaming流式计算框架,针对具体业务主要分为三类,使用不同函数进行处理:
6.5.3.1 无状态Stateless
使用transform和foreacRDD函数
比如实时增量数据ETL:实时从Kafka Topic中获取数据,经过初步转换操作,存储到HBase等大数据组件中。
6.5.3.2 有状态State
双十一大屏幕所有实时累加统计数字(比如销售额和销售量等),比如销售额、网站PV、UV等等;
函数:updateStateByKey、mapWithState
6.5.3.3 窗口统计
每隔多久时间统计最近一段时间内数据,比如饿了么后台报表,每隔5分钟统计最近20分钟订单数。
苏宁搜索推荐时:
数据分析:统计搜索行为时间跨度,86%的搜索行为在5分钟内完成、90%的在10分钟内完成(从搜索开始到最后一次点击结果列表时间间隔);
NDCG实时计算时间范围设定在15分钟,时间窗口为 15 分钟,步进 5 分钟,意味着每 5 分钟计算一次。每次计算,只对在区间[15 分钟前, 10 分钟前]发起的搜索行为进行 NDCG 计算,这样就不会造成重复计算。
Normalized Discounted Cumulative Gain,即 NDCG,常用作搜索排序的评价指标,理想情况下排序越靠前的搜索结果,点击概率越大,即得分越高 (gain)。CG = 排序结果的得分求和, discounted 是根据排名,对每个结果得分 * 排名权重,权重 = 1 / log(1 + 排名) , 排名越靠前的权重越高。首先我们计算理想 DCG(称之为 IDCG), 再根据用户点击结果, 计算真实的 DCG, NDCG = DCG / IDCG,值越接近 1 , 则代表搜索结果越好。
7 Structured Streaming
Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。
Structured Streaming并不是对Spark Streaming的简单改进,而是吸取了在开发Spark SQL和Spark Streaming过程中的经验教训,以及Spark社区和Databricks众多客户的反馈,重新开发的全新流式引擎,致力于为批处理和流处理提供统一的高性能API。同时,在这个新的引擎中,也很容易实现之前在Spark Streaming中很难实现的一些功能,比如Event Time(事件时间)的支持,Stream-Stream Join(2.3.0 新增的功能),毫秒级延迟(2.3.0 即将加入的 Continuous Processing)。
7.1 Structured Streaming概述
Spark Streaming是Apache Spark早期基于RDD开发的流式系统,用户使用DStream API来编写代码,支持高吞吐和良好的容错。其背后的主要模型是Micro Batch(微批处理),也就是将数据流切成等时间间隔(BatchInterval)的小批量任务来执行。
Structured Streaming则是在Spark 2.0加入的,经过重新设计的全新流式引擎。它的模型十分简洁,易于理解。一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾,用户可以使用Dataset/DataFrame 或者 SQL 来对这个动态数据源进行实时查询。
官网文档:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html
7.1.1 Spark Streaming不足
Spark Streaming 会接收实时数据源的数据,并切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。
本质上,这是一种micro-batch(微批处理)的方式处理,用批的思想去处理流数据。这种设计让Spark Streaming面对复杂的流式处理场景时捉襟见肘。
Spark Streaming 存在哪些不足,总结一下主要有下面几点:
1:使用 Processing Time 而不是 Event Time
Processing Time 是数据到达 Spark 被处理的时间,而 Event Time 是数据自带的属性,一般表示数据产生于数据源的时间。
比如 IoT 中,传感器在 12:00:00 产生一条数据,然后在 12:00:05 数据传送到 Spark,那么 Event Time 就是 12:00:00,而 Processing Time 就是 12:00:05。
Spark Streaming是基于DStream模型的micro-batch模式,简单来说就是将一个微小时间段(比如说 1s)的流数据当前批数据来处理。如果要统计某个时间段的一些数据统计,毫无疑问应该使用 Event Time,但是因为 Spark Streaming 的数据切割是基于Processing Time,这样就导致使用 Event Time 特别的困难。
2:Complex, low-level api
DStream(Spark Streaming 的数据模型)提供的API类似RDD的API,非常的low level;
当编写Spark Streaming程序的时候,本质上就是要去构造RDD的DAG执行图,然后通过Spark Engine运行。这样导致一个问题是,DAG 可能会因为开发者的水平参差不齐而导致执行效率上的天壤之别;
3:reason about end-to-end application
end-to-end指的是直接input到out,如Kafka接入Spark Streaming然后再导出到HDFS中;
DStream 只能保证自己的一致性语义是 exactly-once 的,而 input 接入 Spark Streaming 和 Spark Straming 输出到外部存储的语义往往需要用户自己来保证;
4:批流代码不统一
尽管批流本是两套系统,但是这两套系统统一起来确实很有必要,有时候确实需要将的流处理逻辑运行到批数据上面;
Streaming尽管是对RDD的封装,但是要将DStream代码完全转换成RDD还是有一点工作量的,更何况现在Spark的批处理都用DataSet/DataFrameAPI;
总结
流式计算一直没有一套标准化、能应对各种场景的模型,直到2015年Google发表了The Dataflow Model的论文( https://yq.aliyun.com/articles/73255 )
Google开源Apache Beam项目,基本上就是对Dataflow模型的实现,目前已经成为Apache的顶级项目,但是在国内使用不多。
国内使用的更多的是Apache Flink,因为阿里大力推广Flink,甚至把花7亿元把Flink母公司收购。
使用Yahoo的流基准平台,要求系统读取广告点击事件,并按照活动ID加入到一个广告活动的静态表中,并在10秒的event-time窗口中输出活动计数。
比较了Kafka Streams 0.10.2、Apache Flink 1.2.1和Spark 2.3.0,在一个拥有5个c3.2*2大型Amazon EC2 工作节点和一个master节点的集群上(硬件条件为8个虚拟核心和15GB的内存)。
上图(a)展示了每个系统最大稳定吞吐量(积压前的吞吐量),Flink可以达到3300万,而Structured Streaming可以达到6500万,近乎两倍于Flink。这个性能完全来自于Spark SQL的内置执行优化,包括将数据存储在紧凑的二进制文件格式以及代码生成。
附录:【Streaming System系统】设计文章:
Streaming System 第一章【Streaming 101】
网址:https://blog.csdn.net/xxscj/article/details/84990301
Streaming System 第二章【The What- Where- When- and How of Data Processing】
网址:https://blog.csdn.net/xxscj/article/details/84989879
7.1.2 Structured Streaming介绍
或许是对Dataflow模型的借鉴,也许是英雄所见略同,Spark在2.0版本中发布了新的流计算的API:Structured Streaming结构化流。Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎。
Structured Streaming统一了流、批的编程模型,可以使用静态数据批处理一样的方式来编写流式计算操作,并且支持基于event_time的时间窗口的处理逻辑。随着数据不断地到达,Spark 引擎会以一种增量的方式来执行这些操作,并且持续更新结算结果。
7.1.2.1 模块介绍
Structured Streaming 在 Spark 2.0 版本于 2016 年引入,设计思想参考很多其他系统的思想,比如区分 processing time 和 event time,使用 relational 执行引擎提高性能等。同时也考虑了和 Spark 其他组件更好的集成。
Structured Streaming 和其他系统的显著区别主要如下:
1:Incremental query model(增量查询模型)
Structured Streaming 将会在新增的流式数据上不断执行增量查询,同时代码的写法和批处理 API(基于Dataframe和Dataset API)完全一样,而且这些API非常的简单。
2:Support for end-to-end application(支持端到端应用)
Structured Streaming 和内置的 connector 使的 end-to-end 程序写起来非常的简单,而且 “correct by default”。数据源和sink满足 “exactly-once” 语义,这样我们就可以在此基础上更好地和外部系统集成。
3:复用 Spark SQL 执行引擎
Spark SQL 执行引擎做了非常多的优化工作,比如执行计划优化、codegen、内存管理等。这也是Structured Streaming取得高性能和高吞吐的一个原因。
7.1.2.2 核心设计
2016年,Spark在2.0版本中推出了结构化流处理的模块Structured Streaming,核心设计如下:
1:Input and Output(输入和输出)
Structured Streaming 内置了很多 connector 来保证 input 数据源和 output sink 保证 exactly-once 语义。
实现 exactly-once 语义的前提:
Input 数据源必须是可以replay的,比如Kafka,这样节点crash的时候就可以重新读取input数据,常见的数据源包括 Amazon Kinesis, Apache Kafka 和文件系统。
Output sink 必须要支持写入是幂等的,这个很好理解,如果 output 不支持幂等写入,那么一致性语义就是 at-least-once 了。另外对于某些 sink, Structured Streaming 还提供了原子写入来保证 exactly-once 语义。
补充:幂等性:在HTTP/1.1中对幂等性的定义:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。幂等性是系统服务对外一种承诺(而不是实现),承诺只要调用接口成功,外部多次调用对系统的影响是一致的。声明为幂等的服务会认为外部调用失败是常态,并且失败之后必然会有重试。
2:Program API(编程 API)
Structured Streaming 代码编写完全复用 Spark SQL 的 batch API,也就是对一个或者多个 stream 或者 table 进行 query。
query 的结果是 result table,可以以多种不同的模式(追加:append, 更新:update, 完全:complete)输出到外部存储中。
另外,Structured Streaming 还提供了一些 Streaming 处理特有的 API:Trigger, watermark, stateful operator。
3:Execution Engine(执行引擎)
复用 Spark SQL 的执行引擎;
Structured Streaming 默认使用类似 Spark Streaming 的 micro-batch 模式,有很多好处,比如动态负载均衡、再扩展、错误恢复以及 straggler (straggler 指的是哪些执行明显慢于其他 task 的 task)重试;
提供了基于传统的 long-running operator 的 continuous(持续) 处理模式;
4:Operational Features(操作特性)
利用 wal 和状态State存储,开发者可以做到集中形式的 rollback 和错误恢复FailOver。
7.1.2.3 编程模型
Structured Streaming将流式数据当成一个不断增长的table,然后使用和批处理同一套API,都是基于DataSet/DataFrame的。如下图所示,通过将流式数据理解成一张不断增长的表,从而就可以像操作批的静态数据一样来操作流数据了。
在这个模型中,主要存在下面几个组成部分:
1:Input Table(Unbounded Table),流式数据的抽象表示,没有限制边界的,表的数据源源不断增加;
2:Query(查询),对 Input Table 的增量式查询,只要Input Table中有数据,立即(默认情况)执行查询分析操作,然后进行输出(类似SparkStreaming中微批处理);
3:Result Table,Query 产生的结果表;
4:Output,Result Table 的输出,依据设置的输出模式OutputMode输出结果;
核心思想
Structured Streaming最核心的思想就是将实时到达的数据看作是一个不断追加的unbound table无界表,到达流的每个数据项就像是表中的一个新行被附加到无边界的表中,用静态结构化数据的批处理查询方式进行流计算。
以词频统计WordCount案例,Structured Streaming实时处理数据的示意图如下,各行含义:
第一行、表示从TCP Socket不断接收数据,使用【nc -lk 9999】;
第二行、表示时间轴,每隔1秒进行一次数据处理;
第三行、可以看成是“input unbound table”,当有新数据到达时追加到表中;
第四行、最终的wordCounts是结果表,新数据到达后触发查询Query,输出的结果;
第五行、当有新的数据到达时,Spark会执行“增量”查询,并更新结果集;该示例设置为Complete Mode,因此每次都将所有数据输出到控制台;
上图中数据实时处理说明:
第一、在第1秒时,此时到达的数据为”cat dog”和”dog dog”,因此可以得到第1秒时的结果集cat=1 dog=3,并输出到控制台;
第二、当第2秒时,到达的数据为”owl cat”,此时”unbound table”增加了一行数据”owl cat”,执行word count查询并更新结果集,可得第2秒时的结果集为cat=2 dog=3 owl=1,并输出到控制台;
第三、当第3秒时,到达的数据为”dog”和”owl”,此时”unbound table”增加两行数据”dog”和”owl”,执行word count查询并更新结果集,可得第3秒时的结果集为cat=2 dog=4 owl=2;
使用Structured Streaming处理实时数据时,会负责将新到达的数据与历史数据进行整合,并完成正确的计算操作,同时更新Result Table。
7.1.2.4 数据抽象
StructuredStreaming底层基于SparkSQL
数据抽象使用的也是DataFrame和DataSet
注意:
如下是Spark的数据抽象, 可以看出,Spark是推荐使用DataFrame/DataSet的,因为:
1.API更加友好支持SQL也支持代码,门槛更低 (RDD灵活/底层,但是门槛高)
2.DataFrame/DataSet能够处理批,也能够处理流,可以做的流批一体/统一
3.DataFrame/DataSet底层使用SparkSQL执行引擎(可以理解为一个性能强大的发动机,官方做了很多优化)
4.DataFrame兼容其他编程语言(没有泛型,支持Python)
DataFrame > DataSet > RDD(官方其实透露过,后续可能不在更新维护RDD)
7.1.2.5 注意
尽管Spark在2.0就推出了StructuredStreaming ,在2.3也给StructuredStreaming增加了连续处理模式,号称毫秒级
但是在国内实时流处理领域的王者还是Flink,这是国情决定的!,StructuredStreaming在国外是可以满足需求的,在国内满足不了类似于阿里这样的实时要求
注意:StructuredStreaming在国内也有应用:之前是SparkSQL的离线项目很容易用StructuredStreaming做实时.除非实时要求较高,选用Flink
所以在国内:
老项目/老项目升级: Spark > Flink
新项目/实时要求高: Flink > Spark
在北京: Spark > Flink ,但是面试问Flink也越来越多
在上海/杭州: Flink>Spark ,那边有很多阿里系的创业公司/外包公司
在全球: Spark > Flink
7.2 Sources 输入源
从Spark 2.0至Spark 2.4版本,目前支持数据源有4种,其中Kafka 数据源使用作为广泛,其他数据源主要用于开发测试程序。
文档:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#input-sources
可以认为Structured Streaming = SparkStreaming + SparkSQL,对流式数据处理使用SparkSQL数据结构,应用入口为SparkSession,对比SparkSQL与SparkStreaming编程:Spark Streaming:将流式数据按照时间间隔(BatchInterval)划分为很多Batch,每批次数据封装在RDD中,底层RDD数据,构建StreamingContext实时消费数据;
Structured Streaming属于SparkSQL模块中一部分,对流式数据处理,构建SparkSession对象,指定读取Stream数据和保存Streamn数据,具体语法格式:
静态数据
读取spark.read
保存ds/df.write
流式数据
读取spark.readStream
保存ds/df.writeStrem
7.2.1 Socket Source
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 object StructuredStreamingDemo01_Source {[String ] ): Unit = {val spark: SparkSession = SparkSession .() .appName("wc" ) .master("local[*]" )"spark.sql.shuffle.partitions" , "4" ) OrCreate() val sc: SparkContext = spark.sparkContextLogLevel("WARN" ) val linesDF: DataFrame = spark.readStream"socket" )"host" , "node1" )"port" , 9999 )() Schema() val resultDS: Dataset[Row ] = linesDF.as [String ] Map(_ .split (" " ) )By("value" ) () Mode("complete" ) "console" ) () Termination()
7.2.2 Rate Source 了解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 /**2020 /11/ 18 14 :39 // 1 .创建环境"wc" ).master("local[*]" )"spark.sql.shuffle.partitions" , "4" ) // 默认是200 ,本地测试给少一点// 还有很多其他的参数设置项目中进行设置,这里简单一点"WARN" )// 2 .source// 使用RateSource每秒生成10 条测试数据--学习测试时使用"rate" )"rowsPerSecond" , "10" ) // 每秒生成数据条数"rampUpTime" , "0s" ) // 每条数据生成间隔时间"numPartitions" , "2" ) // 分区数目// 3 .输出// append:只输出无界表中的新的数据,只适用于简单查询// complete:输出无界表中所有数据,必须包含聚合才可以用//u pdate:只输出无界表中有更新的数据,不能带有排序"append" )// 输出模式"truncate" ,false)"console" ) // 往控制台输出// 5 .启动并等待停止4 2021 -02 -19 13 :10 :17.52 |30 |2021 -02 -19 13 :10 :17.72 |32 |2021 -02 -19 13 :10 :17.92 |34 |2021 -02 -19 13 :10 :18.12 |36 |2021 -02 -19 13 :10 :18.32 |38 |2021 -02 -19 13 :10 :17.62 |31 |2021 -02 -19 13 :10 :17.82 |33 |2021 -02 -19 13 :10 :18.02 |35 |2021 -02 -19 13 :10 :18.22 |37 |2021 -02 -19 13 :10 :18.42 |39 |exit code -1
7.2.3 File Source 了解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 /* * * Author xiaoma* Date 2020/11/18 14:39* Desc 演示 StructuredStreaming入门案例-从FileSource* /"wc" ).master("local[*]" )"spark.sql.shuffle.partitions" , "4" ) //默认是200,本地测试给少一点"WARN" )"name" , StringType, nullable = true)"age" , IntegerType, nullable = true)"hobby" , StringType, nullable = true)"sep" , ";" )"data/input/persons" )// Equivalent to format("csv" ).load("/path/to/directory" )"append" )//输出模式"truncate" ,false)"console" ) //往控制台输出* * name |age |hobby |2jack1 |23 |running |2jack2 |23 |running |2jack3 |23 |running |2bob1 |20 |swimming |2bob2 |20 |swimming |2tom1 |28 |football |2tom2 |28 |football |2tom3 |28 |football |2tom4 |28 |football |jack1 |23 |running |jack2 |23 |running |jack3 |23 |running |bob1 |20 |swimming |bob2 |20 |swimming |tom1 |28 |football |tom2 |28 |football |tom3 |28 |football |tom4 |28 |football |* /
7.3 Operations 操作
基础操作和之前的DataFrame/DataSet一样!
后续再讲一些流式特有的操作,如EventTime/Watermaker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 args : Array[String]): Unit = {"wc" ).master("local[*]" )"spark.sql.shuffle.partitions" , "4" ) sc : SparkContext = spark.sparkContextsc .setLogLevel("WARN" )format ("socket" )"host" , "node1" )"port" , 9999)as [String]split (" " ))"value" )count ()sort ('count .desc )"t_words" )"" "as word,count (*) as countsby wordorder by counts desc "" ".stripMargin"complete" )format ("console" ) "complete" )format ("console" )
7.4 Sink 输出
在StructuredStreaming中定义好Result DataFrame/Dataset后,调用writeStream()返回DataStreamWriter对象,设置查询Query输出相关属性,启动流式应用运行,相关属性如下:
文档:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#starting-streaming-queries
7.4.1 输出模式
“Output”是用来定义写入外部存储器的内容,输出可以被定义为不同模式:
追加模式(Append mode),默认模式,其中只有自从上一次触发以来,添加到 Result Table 的新行将会是outputted to the sink。只有添加到Result Table的行将永远不会改变那些查询才支持这一点。这种模式保证每行只能输出一次(假设 fault-tolerant sink )。例如,只有select, where, map, flatMap, filter, join等查询支持 Append mode 。只输出那些将来永远不可能再更新的数据,然后数据从内存移除 。没有聚合的时候,append和update一致;有聚合的时候,一定要有水印,才能使用。
完全模式(Complete mode),每次触发后,整个Result Table将被输出到sink,aggregation queries(聚合查询)支持。全部输出,必须有聚合。
更新模式(Update mode),只有 Result Table rows 自上次触发后更新将被输出到 sink。与Complete模式不同,因为该模式只输出自上次触发器以来已经改变的行。如果查询不包含聚合,那么等同于Append模式。只输出更新数据(更新和新增)。
注意,不同查询Query,支持对应的输出模式,如下表所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 /** * Author xiaoma * Date 2020/11/18 14:39 * Desc 演示 StructuredStreaming入门案例-从SocketSource接收数据并做WordCount */ def main(args: Array[String]): Unit = { //1.创建环境 val spark: SparkSession = SparkSession.builder().appName("wc").master("local[*]") .config("spark.sql.shuffle.partitions", "4") //默认是200,本地测试给少一点 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ //2.source //注意:读取流式数据时用spark.readStream val linesDF: DataFrame = spark.readStream .format("socket") .option("host", "node1") .option("port", 9999) .load() linesDF.printSchema() /* root |-- value: string (nullable = true) */ //注意:流模式下,不能直接show,会报如下错误 //Queries with streaming sources must be executed with writeStream.start(); //linesDF.show(false) //3.transformation-做WordCount val resultDS: Dataset[Row] = linesDF.as[String] .flatMap(_.split(" ")) .groupBy("value") .count() //.sort('count.desc) //4.输出 resultDS .writeStream //append:只输出无界表中的新的数据,只适用于简单查询 //complete:输出无界表中所有数据,必须包含聚合才可以用 //update:只输出无界表中有更新的数据,不支持排序 //.outputMode(OutputMode.Complete()) //.outputMode(OutputMode.Append())//Append output mode not supported when there are streaming aggregations .outputMode(OutputMode.Update())//Sorting is not supported //0, the query will run as fast as possible. .trigger(Trigger.ProcessingTime("0 seconds")) .format("console") //往控制台输出 .option("checkpointLocation", "./ckp"+System.currentTimeMillis()) //5.启动并等待停止 .start() .awaitTermination() } +-----+ -----++-----+ -----++-----+ -----++-----+ -----++-----+ -----++-----+ -----+ +-----+ -----++-----+ -----++-----+ -----+ */
7.4.2 触发间隔-了解
触发器Trigger决定了多久执行一次查询并输出结果
当不设置时,默认只要有新数据,就立即执行查询Query,再进行输出。
目前来说,支持三种触发间隔设置:
其中Trigger.Processing表示每隔多少时间触发执行一次,此时流式处理依然属于微批处理;从Spark 2.3以后,支持Continue Processing流式处理,设置触发间隔为Trigger.Continuous但不成熟,使用默认的尽可能快的执行即可。
官网代码示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import org.apache.spark.sql .streaming.Trigger Default trigger (runs micro-batch as soon as it can)trigger (Trigger .ProcessingTime("0 seconds"))start ()trigger with two-seconds micro-batch interval trigger (Trigger .ProcessingTime("2 seconds"))start ()time trigger trigger (Trigger .Once())start ()trigger with one-second checkpointing interval trigger (Trigger .Continuous("1 second"))start ()
7.4.3 查询名称
可以给每个查询Query设置名称Name,必须是唯一的,直接调用DataFrameWriter中queryName方法即可,实际生产开发建议设置名称,API说明如下:
后面和内存输出一起讲
7.4.4 检查点位置 resultDS.format ("console" ) .option ("checkpointLocation" , "./ckp" +System.currentTimeMillis ()).start ().awaitTermination ()
7.4.5 输出终端/位置 7.4.5.1 文件接收器
将输出存储到目录文件中,支持文件格式:parquet、orc、json、csv等,示例如下:
相关注意事项如下:
支持OutputMode为:Append追加模式;
必须指定输出目录参数【path】,必选参数,其中格式有parquet、orc、json、csv等等;
容灾恢复支持精确一次性语义exactly-once;
此外支持写入分区表,实际项目中常常按时间划分;
7.4.5.2 Memory Sink
此种接收器作为调试使用,输出作为内存表存储在内存中, 支持Append和Complete输出模式。这应该用于低数据量的调试目的,因为整个输出被收集并存储在驱动程序的内存中,因此,请谨慎使用,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 object StructuredStreamingDemo03_Output2_QueryName_MemorySink{[String ] ): Unit = {val spark: SparkSession = SparkSession .() .appName("wc" ) .master("local[*]" )"spark.sql.shuffle.partitions" , "4" )OrCreate() val sc: SparkContext = spark.sparkContextLogLevel("WARN" ) val linesDF: DataFrame = spark.readStream"socket" )"host" , "node1" )"port" , 9999 )() Schema() val resultDS: Dataset[Row ] = linesDF.as [String ] Map(_ .split (" " ) )By("value" ) () Mode(OutputMode.Complete() )"memory" )Name("t_result" ) () while (true ){Thread .3000 )"select * from t_result" ).show(false )
7.4.5.3 Foreach和ForeachBatch Sink
注意:
foreachBatch是2.4.0新推出的API,性能比foreach要好
所以接下来直接演示foreachBatch
7.4.5.3.1 Foreach
Structured Streaming提供接口foreach和foreachBatch,允许用户在流式查询的输出上应用任意操作和编写逻辑,比如输出到MySQL表、Redis数据库等外部存系统。其中foreach允许每行自定义写入逻辑,foreachBatch允许在每个微批量的输出上进行任意操作和自定义逻辑,建议使用foreachBatch操作。
foreach表达自定义编写器逻辑具体来说,需要编写类class继承ForeachWriter,其中包含三个方法来表达数据写入逻辑:打开,处理和关闭。
https://databricks.com/blog/2017/04/04/real-time-end-to-end-integration-with-apache-kafka-in-apache-sparks-structured-streaming.html
streamingDatasetOfString.writeStream.foreach (new ForeachWriter[String] {open (partitionId: Long, version : Long): Boolean = {Open connection record : String): Unit = {Write string to connection close (errorOrNull: Throwable): Unit = {Close the connection start ()
7.4.5.3.2 ForeachBatch
方法foreachBatch允许指定在流式查询的每个微批次的输出数据上执行的函数,需要两个参数:微批次的输出数据DataFrame或Dataset、微批次的唯一ID。
使用foreachBatch函数输出时,以下几个注意事项:
1.重用现有的批处理数据源,可以在每个微批次的输出上使用批处理数据输出Output;
2.写入多个位置,如果要将流式查询的输出写入多个位置,则可以简单地多次写入输出 DataFrame/Dataset 。但是,每次写入尝试都会导致重新计算输出数据(包括可能重新读取输入数据)。要避免重新计算,您应该缓存cache输出 DataFrame/Dataset,将其写入多个位置,然后 uncache 。
3.应用其他DataFrame操作,流式DataFrame中不支持许多DataFrame和Dataset操作,使用foreachBatch可以在每个微批输出上应用其中一些操作,但是,必须自己解释执行该操作的端到端语义。
4.默认情况下,foreachBatch仅提供至少一次写保证。 但是,可以使用提供给该函数的batchId作为重复数据删除输出并获得一次性保证的方法。
5.foreachBatch不适用于连续处理模式,因为它从根本上依赖于流式查询的微批量执行。 如果以连续模式写入数据,请改用foreach。
7.4.5.3.3 代码演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 object StructuredStreamingDemo03_Output3_ForeachBatch {[String ] ): Unit = {val spark: SparkSession = SparkSession .() .appName("wc" ) .master("local[*]" )"spark.sql.shuffle.partitions" , "4" )OrCreate() val sc: SparkContext = spark.sparkContextLogLevel("WARN" ) val linesDF: DataFrame = spark.readStream"socket" )"host" , "node1" )"port" , 9999 )() Schema() val resultDS: Dataset[Row ] = linesDF.as [String ] Map(_ .split (" " ) )By("value" ) () Mode(OutputMode.Complete() )Batch((batchDS : Dataset[Row], batchId : Long) => {"-------------" )"batchId:${batchId}" )"-------------" )false )1 )"jdbc" )"url" , "jdbc:mysql://192.168.88.161:3306/bigdata?characterEncoding=UTF-8" )"user" , "root" )"password" , "123456" )"dbtable" , "bigdata.t_struct_words" )() () Termination()
7.4.6 扩展阅读:容错语义
针对任何流式应用处理框架(Storm、SparkStreaming、StructuredStreaming和Flink等)处理数据时,都要考虑语义,任意流式系统处理流式数据三个步骤:
1)、Receiving the data:接收数据源端的数据
采用接收器或其他方式从数据源接收数据(The data is received from sources using Receivers or otherwise)。
2)、Transforming the data:转换数据,进行处理分析
针对StructuredStreaming来说就是Stream DataFrame(The received data is transformed using DStream and RDD transformations)。
3)、Pushing out the data:将结果数据输出
最终分析结果数据推送到外部存储系统,比如文件系统HDFS、数据库等(The final transformed data is pushed out to external systems like file systems, databases, dashboards, etc)。
在处理数据时,往往需要保证数据处理一致性语义:从数据源端接收数据,经过数据处理分析,到最终数据输出仅被处理一次,是最理想最好的状态。在Streaming数据处理分析中,需要考虑数据是否被处理及被处理次数,称为消费语义,
三种语义:
At most once:最多一次,可能出现不消费,数据丢失;
At least once:至少一次,数据至少消费一次,可能出现多次消费数据;
Exactly once:精确一次,数据当且仅当消费一次,不多不少。
Structured Streaming的核心设计理念和目标之一:支持一次且仅一次Extracly-Once的语义。
为了实现这个目标,Structured Streaming设计source、sink和execution engine来追踪计算处理的进度,这样就可以在任何一个步骤出现失败时自动重试。
1、每个Streaming source都被设计成支持offset,进而可以让Spark来追踪读取的位置;
2、Spark基于checkpoint和wal来持久化保存每个trigger interval内处理的offset的范围;
3、sink被设计成可以支持在多次计算处理时保持幂等性,就是说,用同样的一批数据,无论多少次去更新sink,都会保持一致和相同的状态。
综合利用基于offset的source,基于checkpoint和wal的execution engine,以及基于幂等性的sink,可以支持完整的一次且仅一次的语义。
7.5 整合Kafka 7.5.1 说明
http://spark.apache.org/docs/2.4.5/structured-streaming-kafka-integration.html
Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。
Structured Streaming很好的集成Kafka,可以从Kafka拉取消息,然后就可以把流数据看做一个DataFrame, 一张无限增长的大表,在这个大表上做查询,Structured Streaming保证了端到端的 exactly-once,用户只需要关心业务即可,不用费心去关心底层是怎么做的StructuredStreaming既可以从Kafka读取数据,又可以向Kafka 写入数据
添加Maven依赖:
<dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-sql-kafka-0-10_2.11</artifactId > <version > $ {spark.version} </version > </dependency >
注意:
目前仅支持Kafka 0.10.+版本及以上,底层使用Kafka New Consumer API拉取数据
消费位置
Kafka把生产者发送的数据放在不同的分区里面,这样就可以并行进行消费了。每个分区里面的数据都是递增有序的,跟structured commit log类似,生产者和消费者使用Kafka 进行解耦,消费者不管你生产者发送的速率如何,只要按照一定的节奏进行消费就可以了。每条消息在一个分区里面都有一个唯一的序列号offset(偏移量),Kafka 会对内部存储的消息设置一个过期时间,如果过期了,就会标记删除,不管这条消息有没有被消费。
Kafka 可以被看成一个无限的流,里面的流数据是短暂存在的,如果不消费,消息就过期滚动没了。如果开始消费,就要定一下从什么位置开始。
1.earliest:从最起始位置开始消费,当然不一定是从0开始,因为如果数据过期就清掉了,所以可以理解为从现存的数据里最小位置开始消费;
2.latest:从最末位置开始消费;
3.per-partition assignment:对每个分区都指定一个offset,然后从offset位置开始消费;
当第一次开始消费一个Kafka 流的时候,上述策略任选其一,如果之前已经消费了,而且做了 checkpoint ,这时候就会从上次结束的位置开始继续消费。目前StructuredStreaming和Flink框架从Kafka消费数据时,都支持上述的策略。
7.5.2 Kafka特定配置
从Kafka消费数据时,相关配置属性可以通过带有kafka.prefix的DataStreamReader.option进行设置,例如前面设置Kafka Brokers地址属性:stream.option(“kafka.bootstrap.servers”, “host:port”),更多关于Kafka 生产者Producer Config配置属和消费者Consumer Config配置属性,参考文档:
生产者配置(Producer Configs):
http://kafka.apache.org/20/documentation.html#producerconfigs
消费者配置(New Consumer Configs):
http://kafka.apache.org/20/documentation.html#newconsumerconfigs
注意以下Kafka参数属性可以不设置,如果设置的话,Kafka source或者sink可能会抛出错误:
1):group.id:Kafka source将会自动为每次查询创建唯一的分组ID;
2):auto.offset.reset:在将source选项startingOffsets设置为指定从哪里开始。结构化流管理内部消费的偏移量,而不是依赖Kafka消费者来完成。这将确保在topic/partitons动态订阅时不会遗漏任何数据。注意,只有在启动新的流式查询时才会应用startingOffsets,并且恢复操作始终会从查询停止的位置启动;
3):key.deserializer/value.deserializer:Keys/Values总是被反序列化为ByteArrayDeserializer的字节数组,使用DataFrame操作显式反序列化keys/values;
4):key.serializer/value.serializer:keys/values总是使用ByteArraySerializer或StringSerializer进行序列化,使用DataFrame操作将keysvalues/显示序列化为字符串或字节数组;
5):enable.auto.commit:Kafka source不提交任何offset;
6):interceptor.classes:Kafka source总是以字节数组的形式读取key和value。使用ConsumerInterceptor是不安全的,因为它可能会打断查询;
7.5.3 KafkaSource
Structured Streaming消费Kafka数据,采用的是poll方式拉取数据,与Spark Streaming中New Consumer API集成方式一致。从Kafka Topics中读取消息,需要指定数据源(kafka)、Kafka集群的连接地址(kafka.bootstrap.servers)、消费的topic(subscribe或subscribePattern), 指定topic 的时候,可以使用正则来指定,也可以指定一个 topic 的集合。
官方提供三种方式从Kafka topic中消费数据,主要区别在于每次消费Topic名称指定,
1.消费一个Topic数据
2.消费多个Topic数据
3.消费通配符匹配Topic数据
从Kafka 获取数据后Schema字段信息如下,既包含数据信息有包含元数据信息:
在实际开发时,往往需要获取每条数据的消息,存储在value字段中,由于是binary类型,需要转换为字符串String类型;此外了方便数据操作,通常将获取的key和value的DataFrame转换为Dataset强类型,伪代码如下:
从Kafka数据源读取数据时,可以设置相关参数,包含必须参数和可选参数:
1:必须参数:kafka.bootstrap.servers和subscribe,可以指定开始消费偏移量assign。
2:可选参数:
7.5.4 KafkaSink
往Kafka里面写数据类似读取数据,可以在DataFrame上调用writeStream来写入Kafka,设置参数指定value,其中key是可选的,如果不指定就是null。
配置说明
将DataFrame写入Kafka时,Schema信息中所需的字段:
需要写入哪个topic,可以像上述所示在操作DataFrame 的时候在每条record上加一列topic字段指定,也可以在DataStreamWriter上指定option配置。
写入数据至Kafka,需要设置Kafka Brokers地址信息及可选配置:
1.kafka.bootstrap.servers,使用逗号隔开【host:port】字符;
2.topic,如果DataFrame中没有topic列,此处指定topic表示写入Kafka Topic。
官方提供示例代码如下:
7.5.5 案例:实时数据ETL架构
在实际实时流式项目中,无论使用Storm、SparkStreaming、Flink及Structured Streaming处理流式数据时,往往先从Kafka 消费原始的流式数据,经过ETL后将其存储到Kafka Topic中,以便其他业务相关应用消费数据,实时处理分析,技术架构流程图如下所示:
1.使用代码发送数据到Kafka的主题1: stationTopic
2.使用StructuredStreaming从主题1: stationTopic中消费消息,并过滤出合法数据(实时ETL)
3.将ETL的结果发送到Kafka的主题2: etlTopic
4.能够使用控制台消费者从主题2: etlTopic中消费出ETL之后的数据
7.5.5.1 准备主题 /export/servers/kafka/bin/kafka-topics.sh --list --zookeeper node1:2181 /export/servers/kafka/bin/kafka-topics.sh --delete --zookeeper node1:2181 --topic stationTopic/export/servers/kafka/bin/kafka-topics.sh --delete --zookeeper node1:2181 --topic etlTopic/export/servers/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic stationTopic/export/servers/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic etlTopic/export/servers/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic stationTopic --from-beginning /export/servers/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic etlTopic --from-beginning
7.5.5.2 代码实现
7.5.5.2.1 生产者:模拟基站日志数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 def main (args: Array[String ]) : Unit = {new Properties ()put ("bootstrap.servers" , "node1:9092" )put ("acks" , "1" )put ("retries" , "3" )put ("key.serializer" , classOf[StringSerializer].getName)put ("value.serializer" , classOf[StringSerializer].getName)new KafkaProducer[String , String ](props)new Random ()Array ("fail" , "busy" , "barring" , "success" , "success" , "success" ,"success" , "success" , "success" , "success" , "success" , "success" while (true ) {String = "1860000%04d" .format(random.nextInt (10000 ))String = "1890000%04d" .format(random.nextInt (10000 ))String = allStatus (random.nextInt (allStatus.length))if ("success" .equals (callStatus)) (1 + random.nextInt (10 )) * 1000L else 0L StationLog ("station_" + random.nextInt (10 ),currentTimeMillis (),println (stationLog.toString)sleep (100 + random.nextInt (100 ))new ProducerRecord[String , String ]("stationTopic" , stationLog.toString)send (record)close () case class StationLog (String , String , String , String , override def toString: String = {"$stationId,$callOut,$callIn,$callStatus,$callTime,$duration"
7.5.5.2.2 实时增量ETL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 object StructuredStreamingDemo04_Kafka {[String ] ): Unit = {val spark: SparkSession = SparkSession .() .appName("wc" ) .master("local[*]" )"spark.sql.shuffle.partitions" , "4" )OrCreate() val sc: SparkContext = spark.sparkContextLogLevel("WARN" ) val kafkaRecordDF: DataFrame = spark"kafka" )"kafka.bootstrap.servers" , "node1:9092" )"subscribe" , "stationTopic" )() val valueStrDS: Dataset[String ] = kafkaRecordDF.selectExpr("CAST(value AS STRING)" ) .as [String ] val etlResult: Dataset[String ] = valueStrDS.filter(_ ."success" ))"kafka" )"kafka.bootstrap.servers" , "node1:9092" )"topic" , "etlTopic" )"checkpointLocation" , "./ckp" + System .TimeMillis() )() Termination()
7.6 物联网设备数据分析
在物联网时代,大量的感知器每天都在收集并产生着涉及各个领域的数据。物联网提供源源不断的数据流,使实时数据分析成为分析数据的理想工具。
演示物联网设备数据分析:
设备名称 设备类型 信号强度 时间戳
{“device”:”device_10”,”deviceType”:”db”,”signal”:79.0,”time”:196519}
….
1)、信号强度大于30的设备;
2)、各种设备类型的数量;
3)、各种设备类型的平均信号强度;
求: 各种信号强度>30的设备的各个类型的数量和平均信号强度,先过滤再聚合
7.6.1 创建Topic /export/ servers/kafka/ bin/kafka-topics.sh --list --zookeeper node1:2181 /export/ servers/kafka/ bin/kafka-topics.sh --delete --zookeeper node1:2181 --topic iotTopic/export/ servers/kafka/ bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic iotTopic/export/ servers/kafka/ bin/kafka-console-producer.sh --broker-list node1:9092 --topic iotTopic/export/ servers/kafka/ bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic iotTopic --from-beginning
7.6.2 模拟数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 object MockIotDatas {def main (args: Array[String ]) : Unit = {new Properties ()put ("bootstrap.servers" , "node1:9092" )put ("acks" , "1" )put ("retries" , "3" )put ("key.serializer" , classOf[StringSerializer].getName)put ("value.serializer" , classOf[StringSerializer].getName)new KafkaProducer[String , String ](props)Array ("db" , "bigdata" , "kafka" , "route" , "bigdata" , "db" , "bigdata" , "bigdata" , "bigdata" new Random ()while (true ) {nextInt (deviceTypes.length)String = s"device_${(index + 1) * 10 + random.nextInt(index + 1)}" String = deviceTypes (index)10 + random.nextInt (90 )DeviceData (deviceId, deviceType, deviceSignal, System.currentTimeMillis ())String = new Json (org.json4s.DefaultFormats).write (deviceData)println (deviceJson)sleep (1000 + random.nextInt (500 ))new ProducerRecord[String , String ]("iotTopic" , deviceJson)send (record)close ()case class DeviceData (String , String ,
7.6.3 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 /**2020 /11 /18 14 :39 "device" :"device_10" ,"deviceType" :"db" ,"signal" :79.0 ,"time" :196519 }1 )、信号强度大于30 的设备;2 )、各种设备类型的数量;3 )、各种设备类型的平均信号强度;30 的设备的各个类型的数量和平均信号强度,先过滤再聚合Array [String ]): Unit = {1. 创建环境"wc" ).master("local[*]" )"spark.sql.shuffle.partitions" , "4" )"spark.sql.streaming.checkpointLocation" ,"./ckp" + System.currentTimeMillis())"WARN" )import spark.implicits._import org.apache.spark.sql.functions._2. source-从Kafka的stationTopic消费数据"kafka" )"kafka.bootstrap.servers" , "node1:9092" )"subscribe" , "iotTopic" )"device" :"device_10" ,"deviceType" :"db" ,"signal" :79.0 ,"time" :196519 }String ] = kafkaRecordDF.selectExpr("CAST(value AS STRING)" ).as[String ]true )"device" :"device_41" ,"deviceType" :"route" ,"signal" :85.0 ,"time" :1605836867321 } |3. transformation-将json字符串解析处理--增加Schema约束:字段名称和字段类型"value" , "$.device" ).as("device_id" ),"value" , "$.deviceType" ).as("device_type" ),"value" , "$.signal" ).cast(DoubleType).as("signal" ),"value" , "$.time" ).cast(LongType).as("time" )4. 业务统计30 的设备的各个类型的数量和平均信号强度,先过滤再聚合"t_iot" )""" |select device_type, count(*) counts,avg(signal) avg_signal |from t_iot |where signal > 30 |group by device_type |""" .stripMargin)30 )"*" ).as("counts" ),"avg_singal" )5. sink-结果输出到Kafka的etlTopic"console" )"truncate" ,false )"console" )"truncate" ,false )1. 准备好主题2. 启动生产者3. 启动控制台消费者4. 启动该StructuredStreaming程序
7.7 事件时间窗口分析 7.7.1 时间概念
在Streaming流式数据处理中,按照时间处理数据,其中时间有三种概念:
1)、事件时间EventTime,表示数据本身产生的时间,该字段在数据本身中;
2)、注入时间IngestionTime,表示数据到达流式系统时间,简而言之就是流式处理系统接收到数据的时间;
3)、处理时间ProcessingTime,表示数据被流式系统真正开始计算操作的时间。
不同流式计算框架支持时间不一样,
SparkStreaming框架仅仅支持处理时间ProcessTime,
StructuredStreaming支持事件时间和处理时间,
Flink框架支持三种时间数据操作,
实际项目中往往针对【事件时间EventTime】进行数据处理操作,更加合理化。
7.7.2 event-time
基于事件时间窗口聚合操作:基于窗口的聚合(例如每分钟事件数)只是事件时间列上特殊类型的分组和聚合,其中每个时间窗口都是一个组,并且每一行可以属于多个窗口/组。
事件时间EventTime是嵌入到数据本身中的时间,数据实际真实产生的时间。例如,如果希望获得每分钟由物联网设备生成的事件数,那么可能希望使用生成数据的时间(即数据中的事件时间event time),而不是Spark接收数据的时间(receive time/archive time)。
这个事件时间很自然地用这个模型表示,设备中的每个事件(Event)都是表中的一行(Row),而事件时间(Event Time)是行中的一列值(Column Value)。
因此,这种基于事件时间窗口的聚合查询既可以在静态数据集(例如,从收集的设备事件日志中)上定义,也可以在数据流上定义,从而使用户的使用更加容易。
修改词频统计程序,数据流包含每行数据以及生成每行行的时间。希望在10分钟的窗口内对单词进行计数,每5分钟更新一次,如下图所示:
单词在10分钟窗口【12:00-12:10、12:05-12:15、12:10-12:20】等之间接收的单词中计数。注意,【12:00-12:10】表示处理数据的事件时间为12:00之后但12:10之前的数据。思考一下,12:07的一条数据,应该增加对应于两个窗口12:00-12:10和12:05-12:15的计数。
基于事件时间窗口统计有两个参数索引:分组键(如单词)和窗口(事件时间字段)。
event-time 窗口生成
Structured Streaming中如何依据EventTime事件时间生成窗口的呢?查看类TimeWindowing源码中生成窗口规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 org.apache.spark.sql.catalyst.analysis.TimeWindowing0 until maxNumOverlapping)
将【(event-time向上取 能整除 滑动步长的时间) - (最大窗口数×滑动步长)】作为”初始窗口“的开始时间,然后按照窗口滑动宽度逐渐向时间轴前方推进,直到某个窗口不再包含该event-time 为止,最终以”初始窗口"与"结束窗口"之间的若干个窗口作为最终生成的 event-time 的时间窗口。
每个窗口的起始时间start与结束时间end都是前闭后开(左闭右开)的区间,因此初始窗口和结束窗口都不会包含 event-time,最终不会被使用。假设数据为【2019-08-14 10:50:00, dog】,按照上述规则计算窗口示意图如下:
得到窗口如下:
7.7.3 延迟数据处理
Structed Streaming与Spark Streaming相比一大特性就是支持基于数据中的时间戳的数据处理。也就是在处理数据时,可以对记录中的eventTime事件时间字段进行考虑。因为eventTime更好的代表数据本身的信息,且可以借助eventTime处理比预期晚到达的数据,但是需要有一个限度(阈值),不能一直等,应该要设定最多等多久。
7.7.3.1 延迟数据
在很多流计算系统中,数据延迟到达(the events arrives late to the application)的情况很常见,并且很多时候是不可控的,因为很多时候是外围系统自身问题造成的。Structured Streaming可以保证一条旧的数据进入到流上时,依然可以基于这些“迟到”的数据重新计算并更新计算结果。
上图中在12:04(即事件时间)生成的单词可能在12:11被应用程序接收,此时,应用程序应使用时间12:04而不是12:11更新窗口12:00-12:10的旧计数。但是会出现如下两个问题:
问题一:延迟数据计算是否有价值
如果某些数据,延迟很长时间(如30分钟)才到达流式处理系统,数据还需要再次计算吗?计算的结果还有价值吗?原因在于流式处理系统处理数据关键核心在于实时性;近期数据,更新一个很早之前的状态往往已经不再具有很大的业务价值;
问题二:以前状态保存浪费资源
实时统计来说,如果保存很久以前的数据状态,很多时候没有作用的,反而浪费大量资源;
Spark 2.1引入的watermarking允许用户指定延迟数据的阈值,也允许引擎清除掉旧的状态。即根据watermark机制来设置和判断消息的有效性,如可以获取消息本身的时间戳,然后根据该时间戳来判断消息的到达是否延迟(乱序)以及延迟的时间是否在容忍的范围内(延迟的数据是否处理)。
7.7.3.2 Watermarking水位
水位watermarking官方定义:
lets the engine automatically track the current event time in the data and attempt to clean up old state accordingly.
翻译:让Spark SQL引擎自动追踪数据中当前事件时间EventTime,依据规则清除旧的状态数据。
通过指定event-time列(上一批次数据中EventTime最大值)和预估事件的延迟时间上限(Threshold)来定义一个查询的水位线watermark。
Watermark = MaxEventTime - Threshod
1:执行第一批次数据时,Watermarker为0,所以此批次中所有数据都参与计算;
2:Watermarker值只能逐渐增加,不能减少;
3:Watermark机制主要解决处理聚合延迟数据和减少内存中维护的聚合状态;
4:设置Watermark以后,输出模式OutputMode只能是Append和Update;
如下方式设置阈值Threshold,计算每批次数据执行时的水位Watermark:
看一下官方案例:词频统计WordCount,设置阈值Threshold为10分钟,每5分钟触发执行一次。
延迟到达但没有超过watermark:(12:08, dog)
在12:20触发执行窗口(12:10-12:20)数据中,(12:08, dog) 数据是延迟数据,阈值Threshold设定为10分钟,此时水位线【Watermark = 12:14 - 10m = 12:04】,因为12:14是上个窗口(12:05-12:15)中接收到的最大的事件时间,代表目标系统最后时刻的状态,由于12:08在12:04之后,因此被视为“虽然迟到但尚且可以接收”的数据而被更新到了结果表中,也就是(12:00 - 12:10, dog, 2)和(12:05 - 12:11, dog, 3)。
超出watermark:(12:04, donkey)
在12:25触发执行窗口(12:15-12:25)数据中,(12:04, donkey)数据是延迟数据,上个窗口中接收到最大的事件时间为12:21,此时水位线【Watermark = 12:21 - 10m = 12:11】,而(12:04, donkey)比这个值还要早,说明它”太旧了”,所以不会被更新到结果表中了。
设置水位线Watermark以后,不同输出模式OutputMode,结果输出不一样:
Update模式:总是倾向于“尽可能早”的将处理结果更新到sink,当出现迟到数据时,早期的某个计算结果将会被更新;Append模式:推迟计算结果的输出到一个相对较晚的时刻,确保结果是稳定的,不会再被更新,比如:12:00 - 12:10窗口的处理结果会等到watermark更新到12:11之后才会写入到sink。
如果用于接收处理结果的sink不支持更新操作,则只能选择Append模式。
7.7.4 代码演示
API
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 /* * * 演示StructuredStreaming中的EventTime和Watermaker* 示例数据如下* 2019-10-10 12:00:07,dog* 2019-10-10 12:00:08,owl* * 2019-10-10 12:00:14,dog* 2019-10-10 12:00:09,cat* * 2019-10-10 12:00:15,cat* 2019-10-10 12:00:08,dog* 2019-10-10 12:00:13,owl* 2019-10-10 12:00:21,owl* * 2019-10-10 12:00:04,donkey --延迟了17s,延迟很严重会丢失* 2019-10-10 12:00:17,owl --延迟了4s,延迟不严重不丢失* /"$" ))"local[*]" )"spark.sql.shuffle.partitions" , "3" )"WARN" )"socket" )"host" , "node1" )"port" , 9999)"," )"\\s+" )"timestamp" , "word" )"timestamp" ,"10 seconds" )"10 seconds" ,"5 seconds" ),"console" )"truncate" , "false" )"5 seconds" ))* * window |word |count |[2019-10-10 12:00:10, 2019-10-10 12:00:20] |dog |2 |[2019-10-10 12:00:15, 2019-10-10 12:00:25] |cat |2 |[2019-10-10 12:00:10, 2019-10-10 12:00:20] |cat |2 |[2019-10-10 12:00:15, 2019-10-10 12:00:25] |owl |3 |[2019-10-10 12:00:20, 2019-10-10 12:00:30] |owl |2 |[2019-10-10 12:00:05, 2019-10-10 12:00:15] |dog |6 |[2019-10-10 12:00:05, 2019-10-10 12:00:15] |owl |4 |[2019-10-10 12:00:05, 2019-10-10 12:00:15] |cat |2 |[2019-10-10 12:00:10, 2019-10-10 12:00:20] |owl |3 |window |word |count |[2019-10-10 12:00:15, 2019-10-10 12:00:25] |owl |4 |[2019-10-10 12:00:10, 2019-10-10 12:00:20] |owl |4 |* /
7.8 Streaming Deduplication 7.8.1 介绍
对实时流数据中的数据进行去重
方案0:使用内存hashSet去重(但是不是分布式的)--单机可用,分布式情况下淘汰
方案1:使用利用BitMap进行大数据排序去重 / 使用布隆过滤器去重 ----底层使用的是位数组
https://blog.csdn.net/m0_37264516/article/details/87025711
https://www.cnblogs.com/z-sm/p/6238977.html
https://blog.csdn.net/zuochao_2013/article/details/81807997
方案2:搞个外部存储如Redis对实时流数据进行存储,进来一条数据就去Redis中查看,如果存在说明重复吗,就不再处理,如果不在说明不重复,需要进行业务处理,处理完之后放入Redis---分布式情况下可用! 但是得自己写代码,麻烦
方案3:使用流处理框架支持的State进行去重,直接打点调方法即可
Flink中:
distinct(字段名称s)
Spark中:
distinct(没有参数)底层dropDuplicates(没有参数),没有参数按照key(第一个字段去)
dropDuplicates(字段名称s)
7.8.2 代码演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 object StructuredStreamingDemo06_Deduplication {[String ] ): Unit = {val spark: SparkSession = SparkSession .() Name(this .getClass .getSimpleName .stripSuffix ("$" ) )"local[*]" )"spark.sql.shuffle.partitions" , "3" )OrCreate() val sc: SparkContext = spark.sparkContextLogLevel("WARN" ) val inputTable: DataFrame = spark.readStream"socket" )"host" , "node1" )"port" , 9999 )() val resultTable: DataFrame = inputTableas [String ] StringUtils .NotBlank(_ ) )_json_object($"value" , "$.eventTime" ) .as ("event_time" ),_json_object($"value" , "$.eventType" ) .as ("event_type" ),_json_object($"value" , "$.userID" ) .as ("user_id" )Duplicates("user_id" , "event_type" ) By($"user_id" ) () val query: StreamingQuery = resultTable.writeStreamMode(OutputMode.Complete() )"console" )"numRows" , "10" )"truncate" , "false" )() Termination() ()
7.9 Continuous Processing
连续处理(Continuous Processing)是Spark 2.3中引入的一种新的实验性流执行模式,可实现毫秒级端到端延迟(类似Storm、Flink),但只能保证At-Least-Once 最少一次:即不会丢失数据,但可能会有重复结果。
默认的微批处理(micro-batch processing)引擎,可以实现Exactly-Once 精确一次保证,但最多可实现100ms的延迟。
注意:目前StructuredStreaming的Continuous processing属于实验开发阶段
在Spark的后续版本中没有太多更新升级,因为Spark认为Spark已经可以搞定90%的大数据应用场景,剩下的10%的极端的实时流处理场景的投入产出比不高,所以把时间精力投入到SparkSQL、数据湖、Spark+AI等方向去了
关注博主不迷路

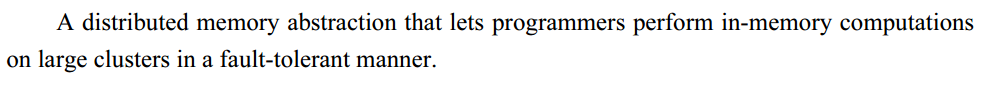
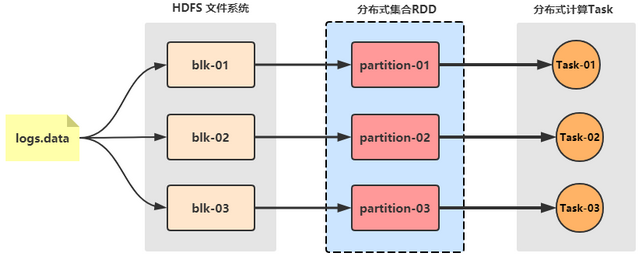

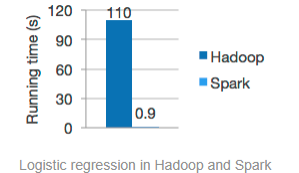
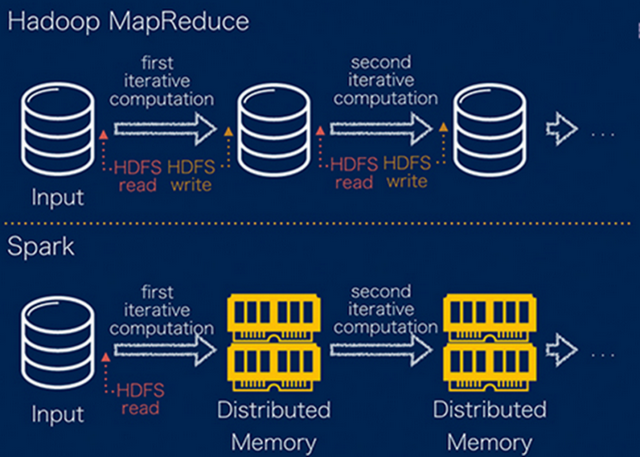

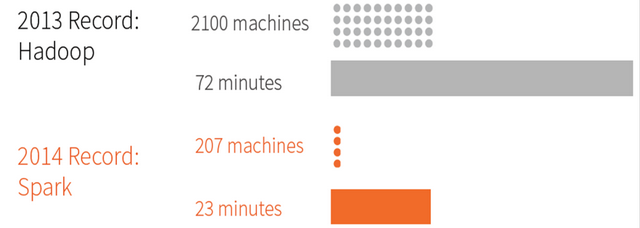




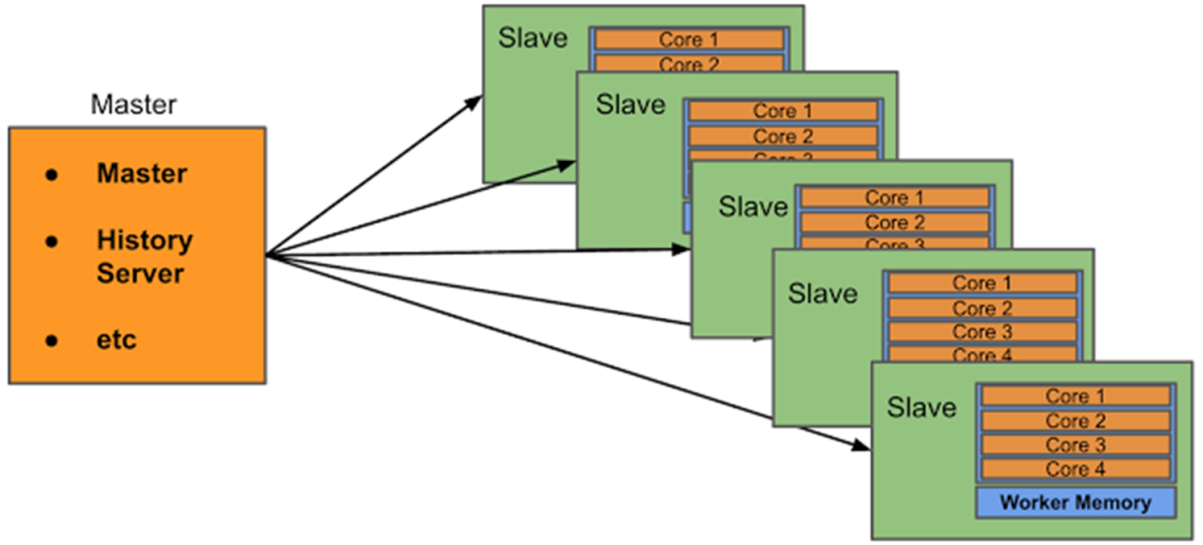


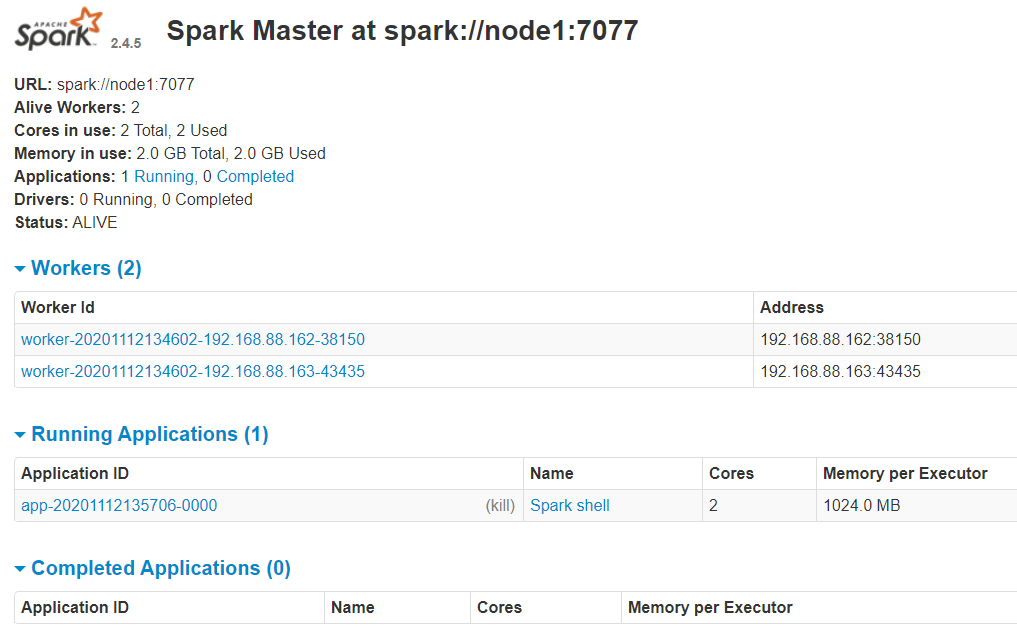




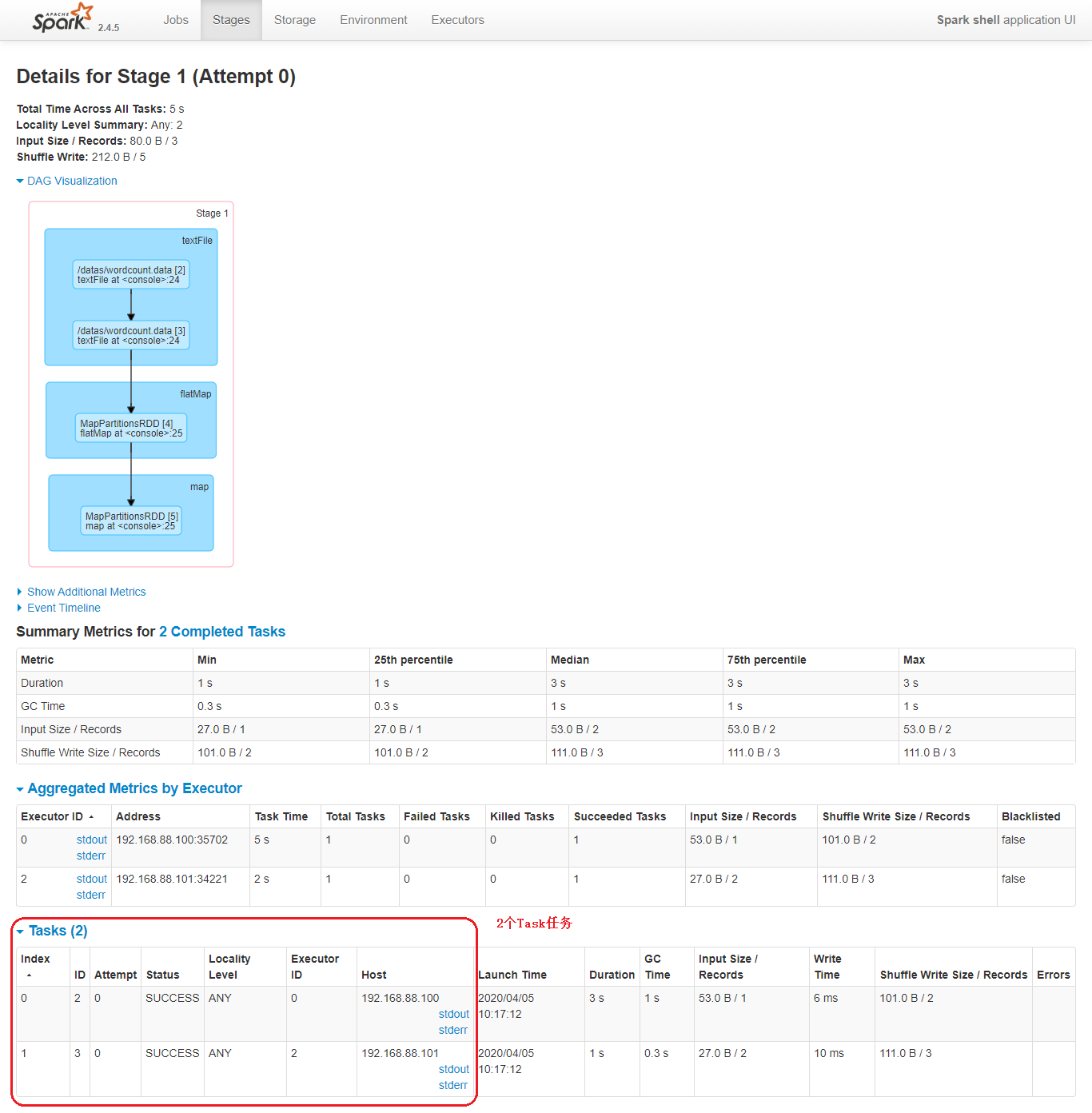
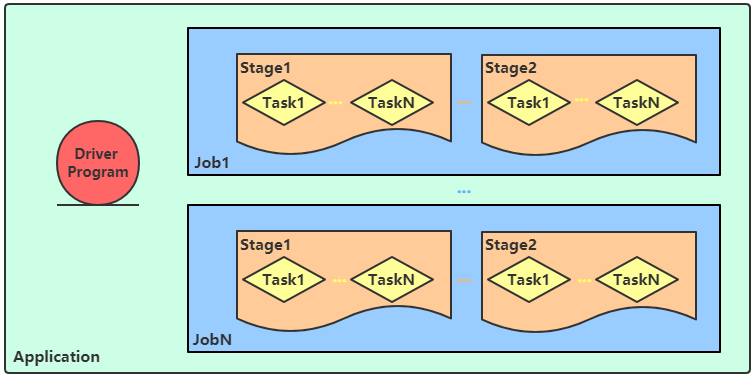
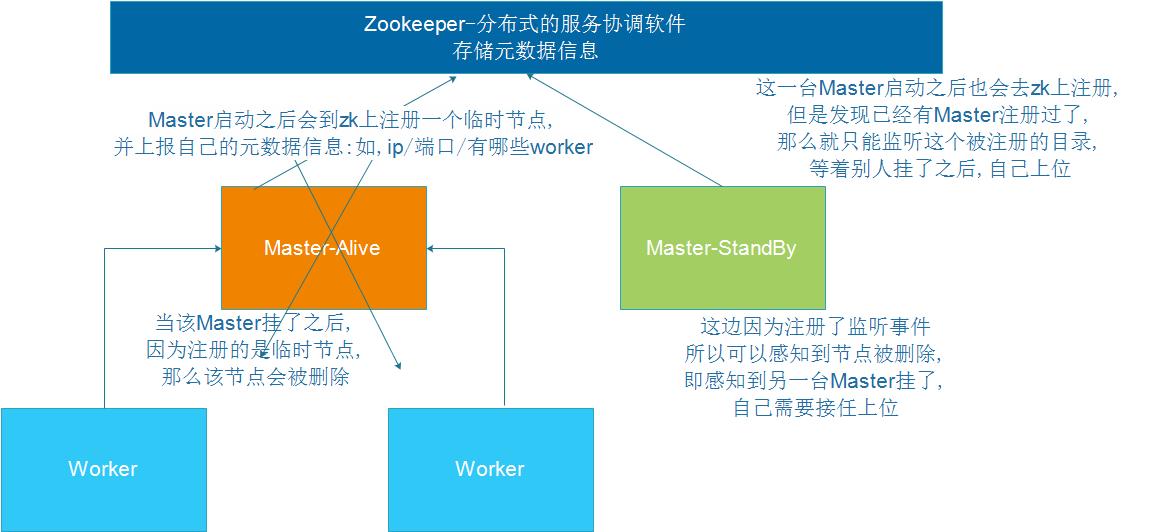
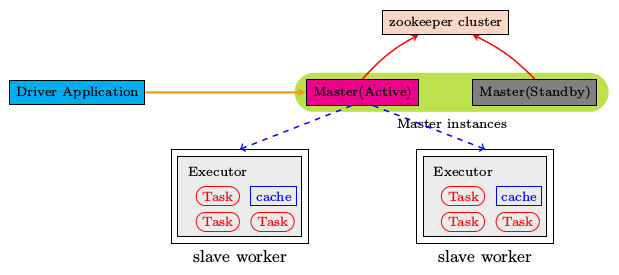
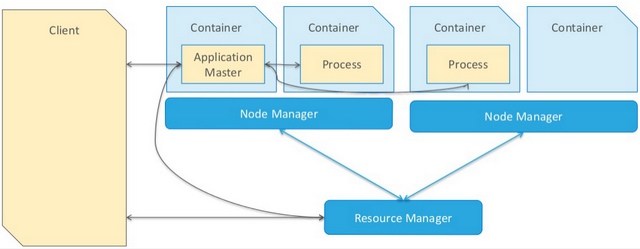
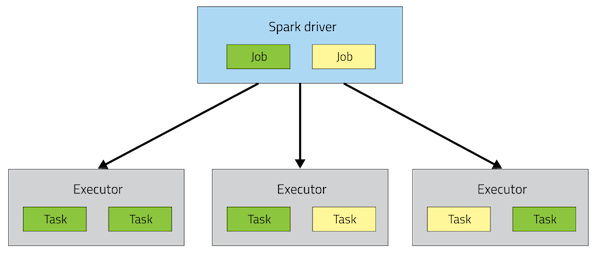
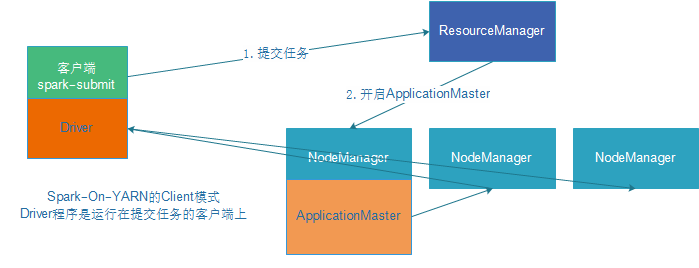
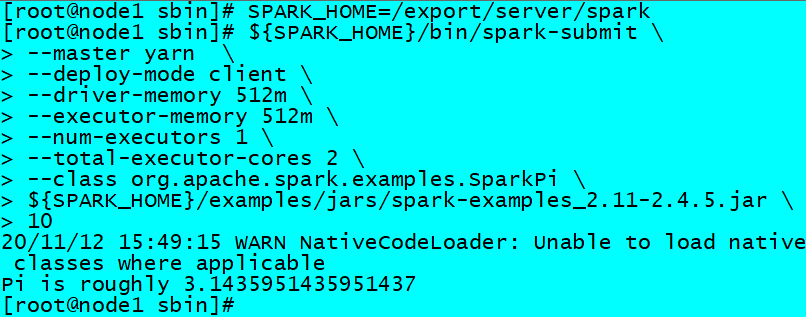
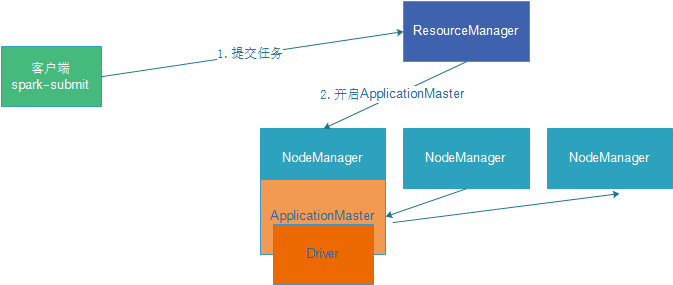





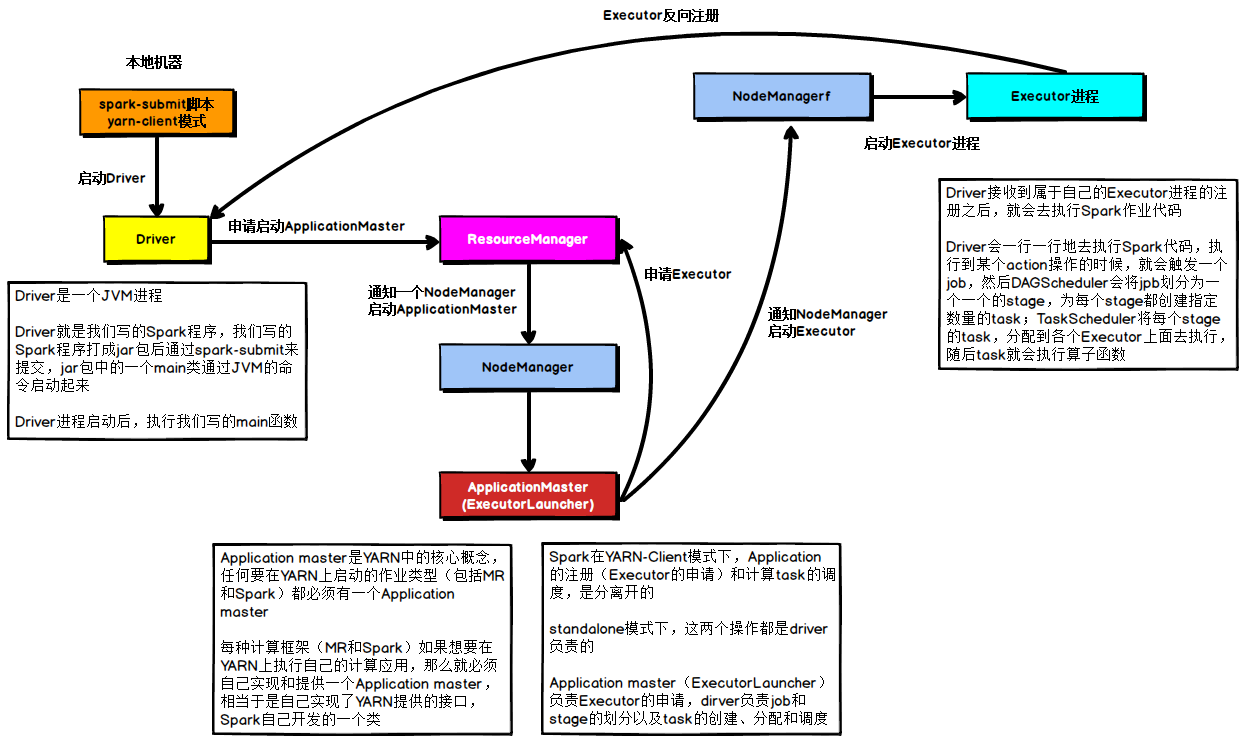


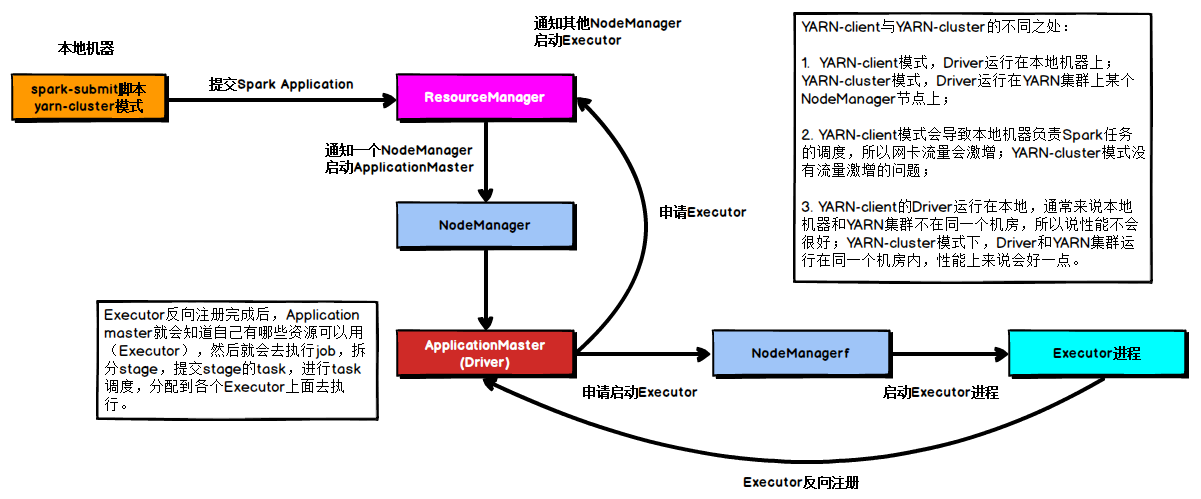

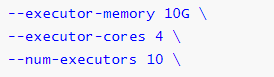

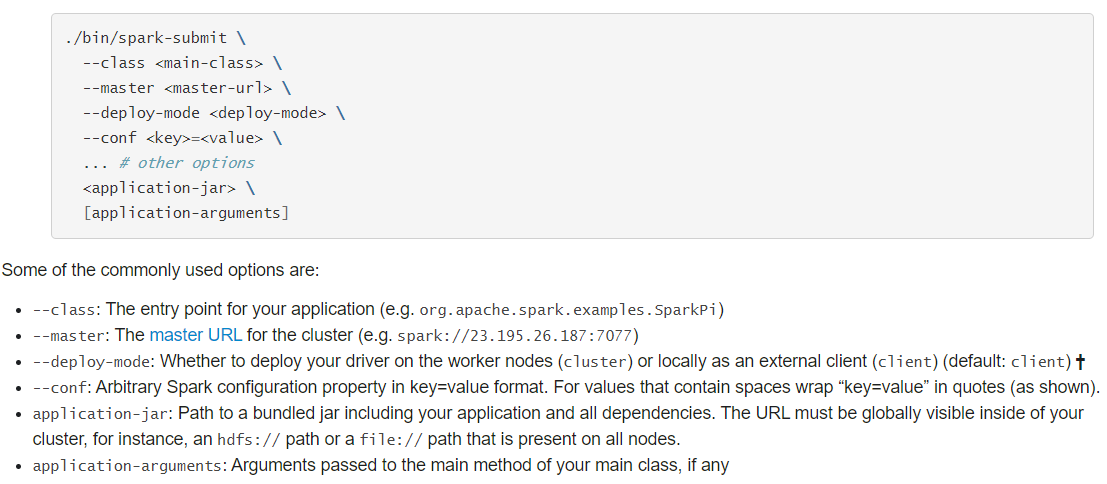







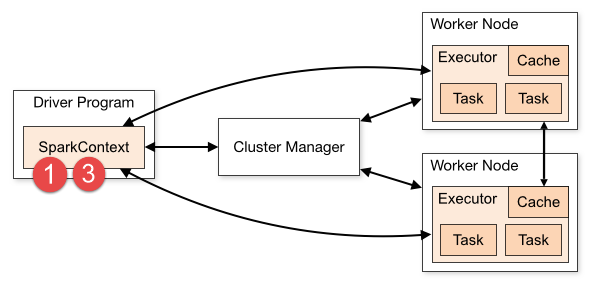
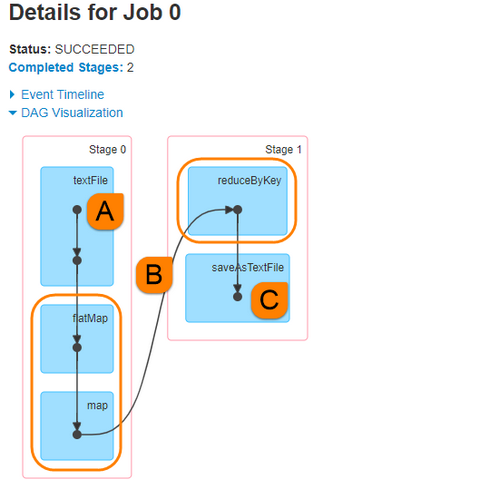





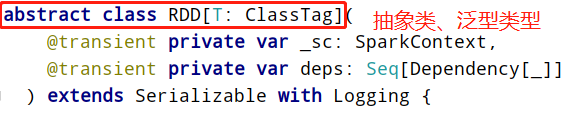
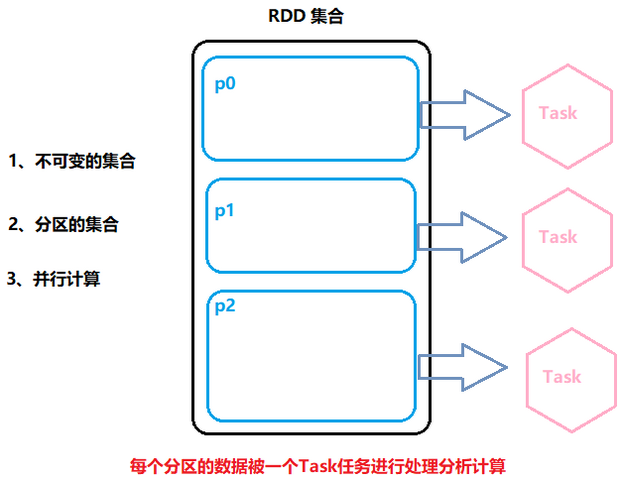
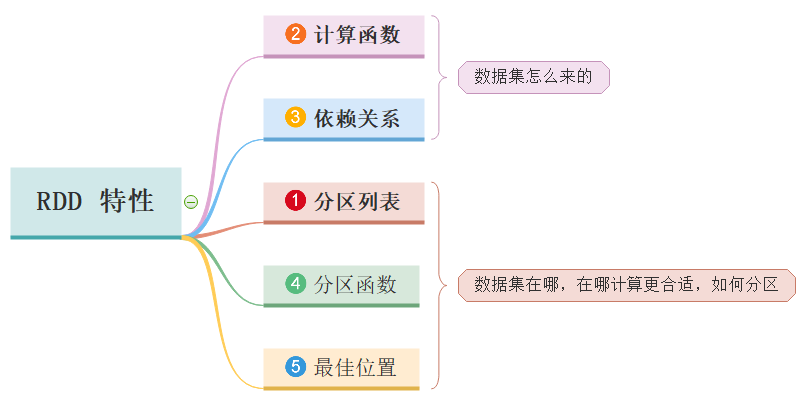




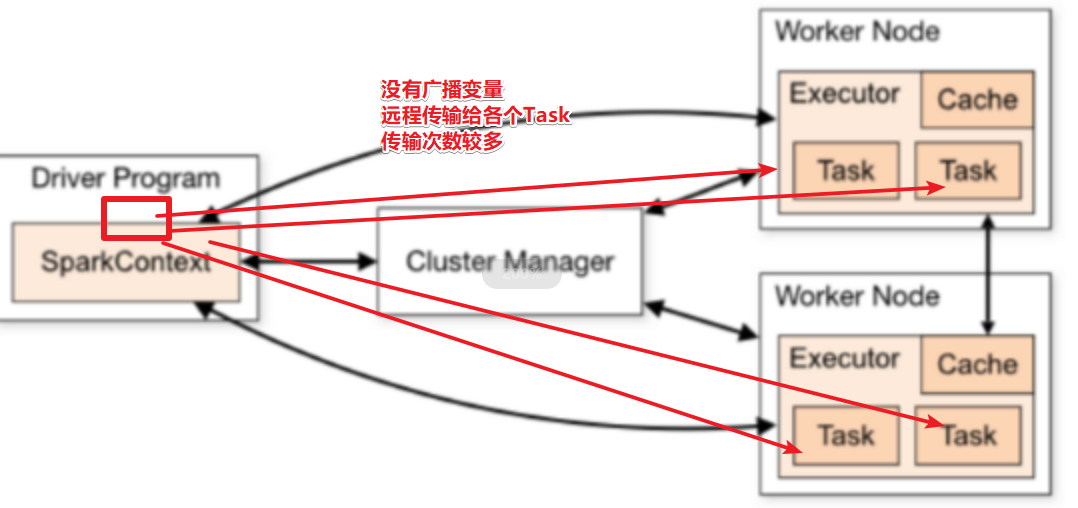
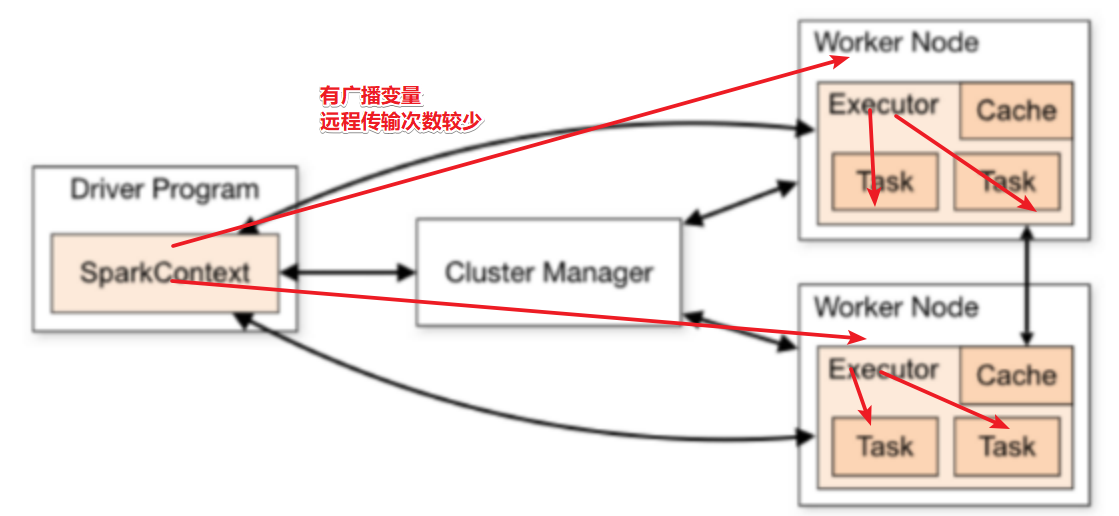
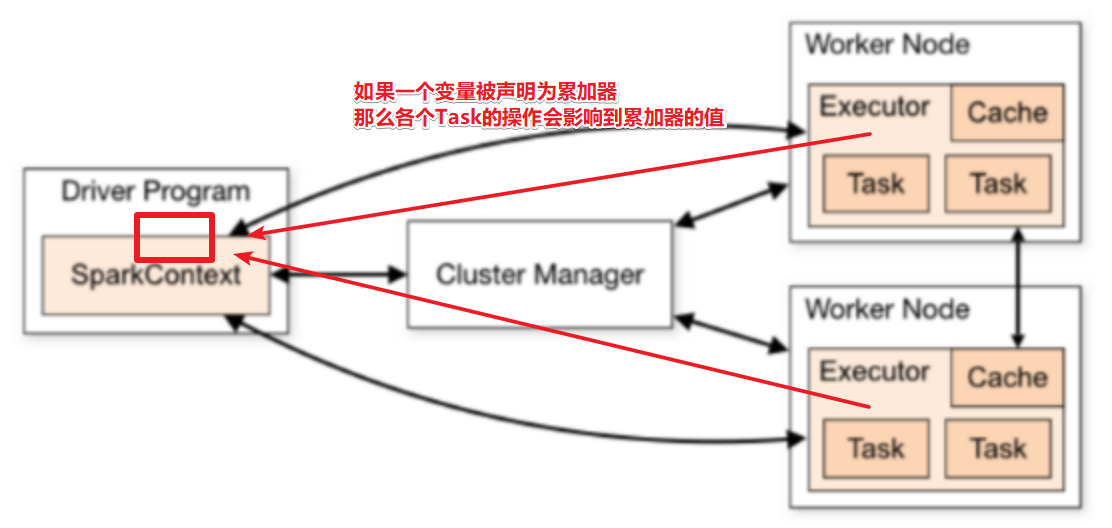



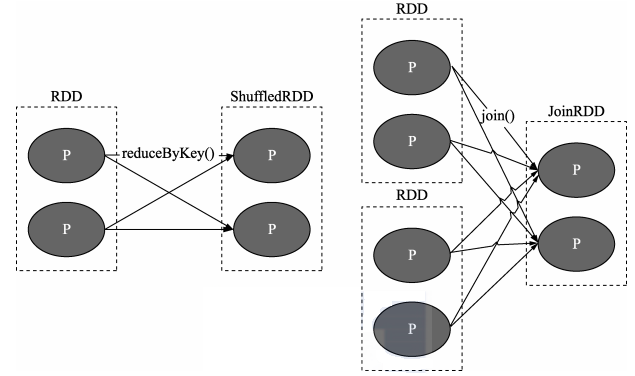
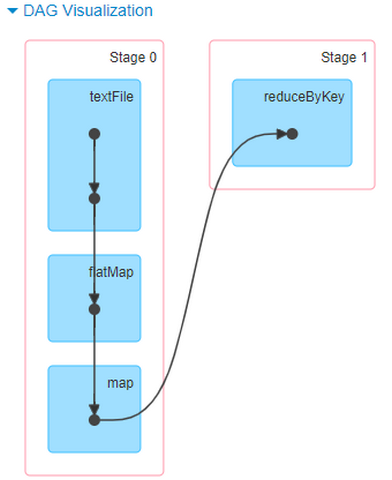

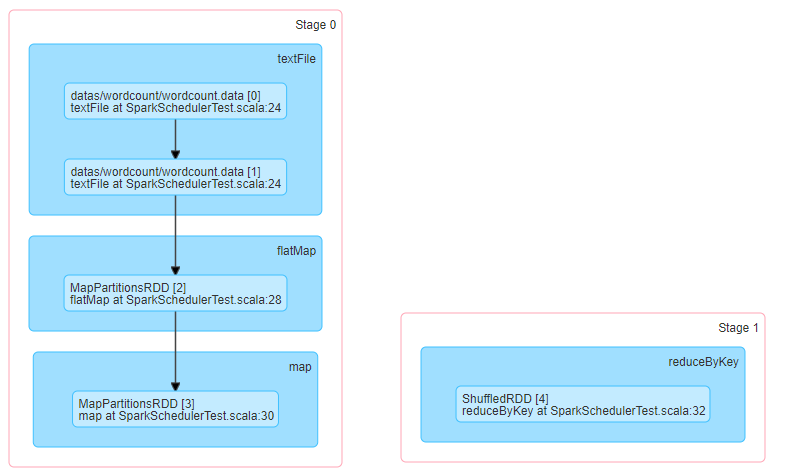
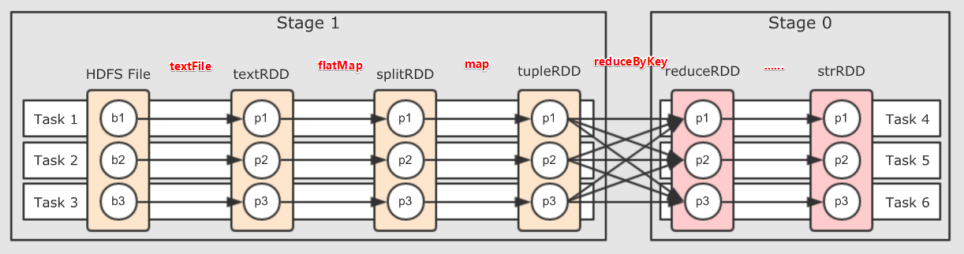

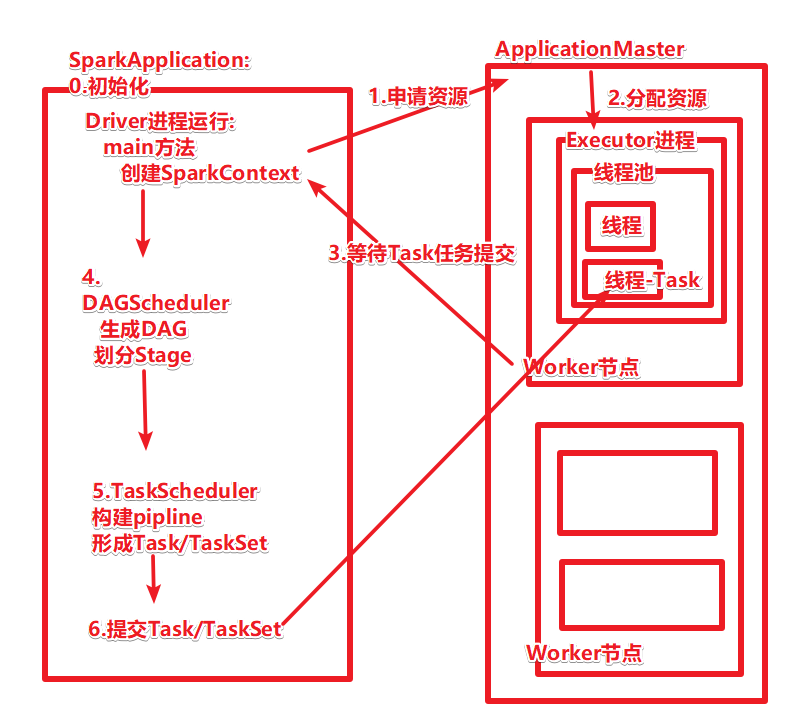
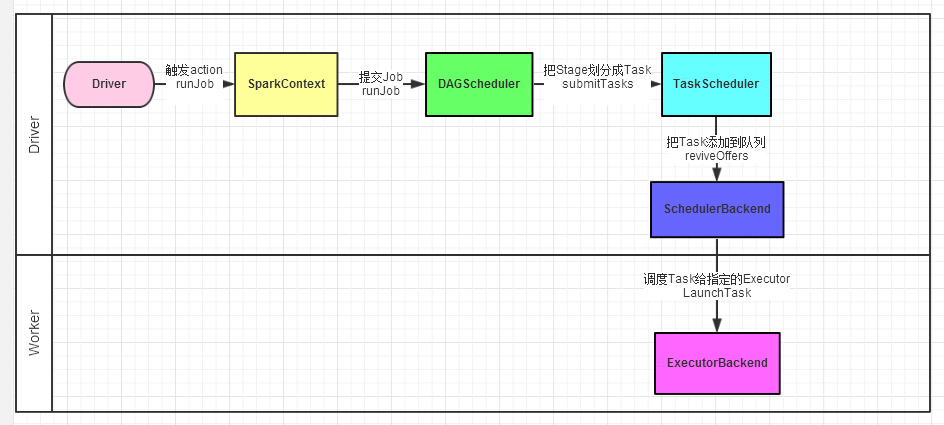

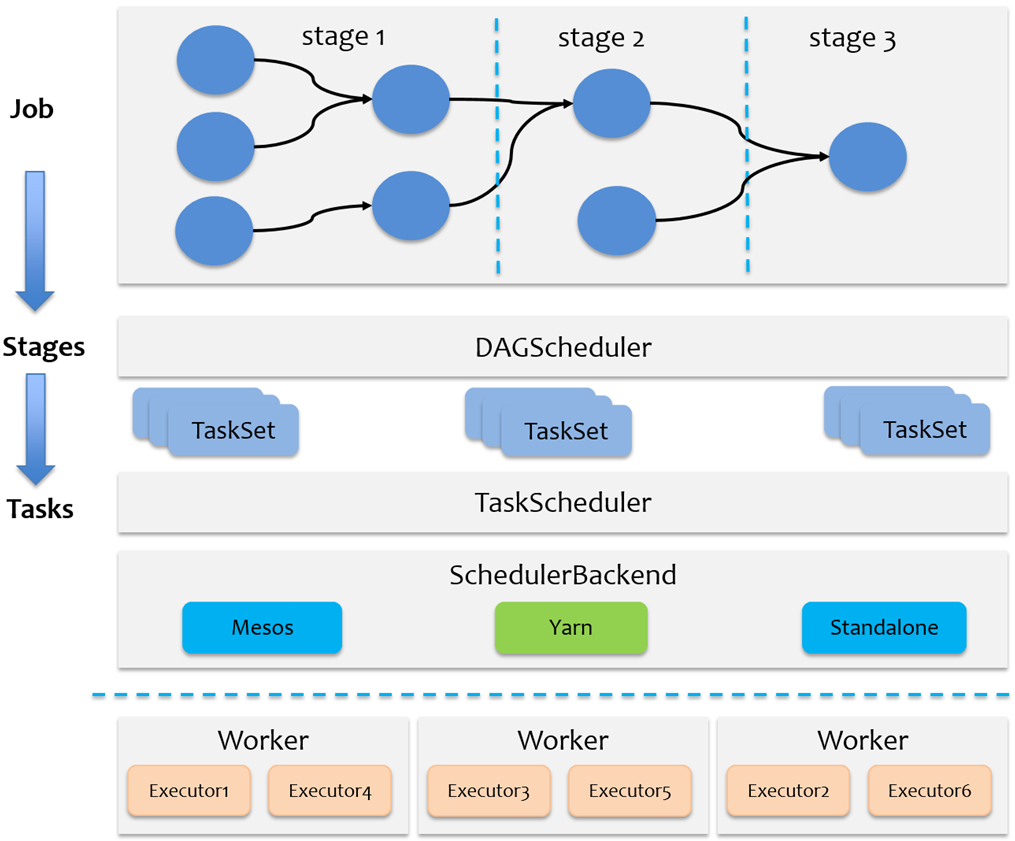

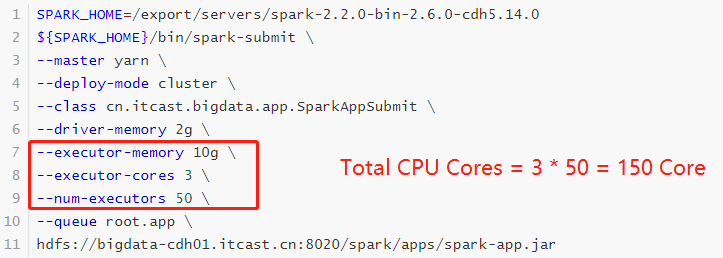


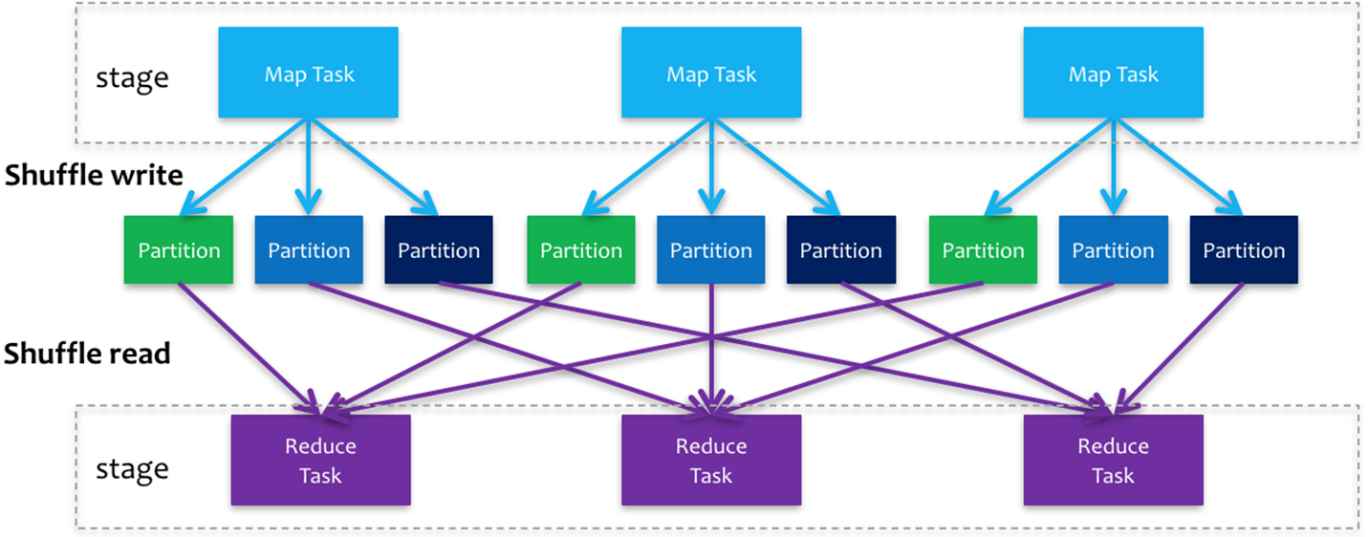
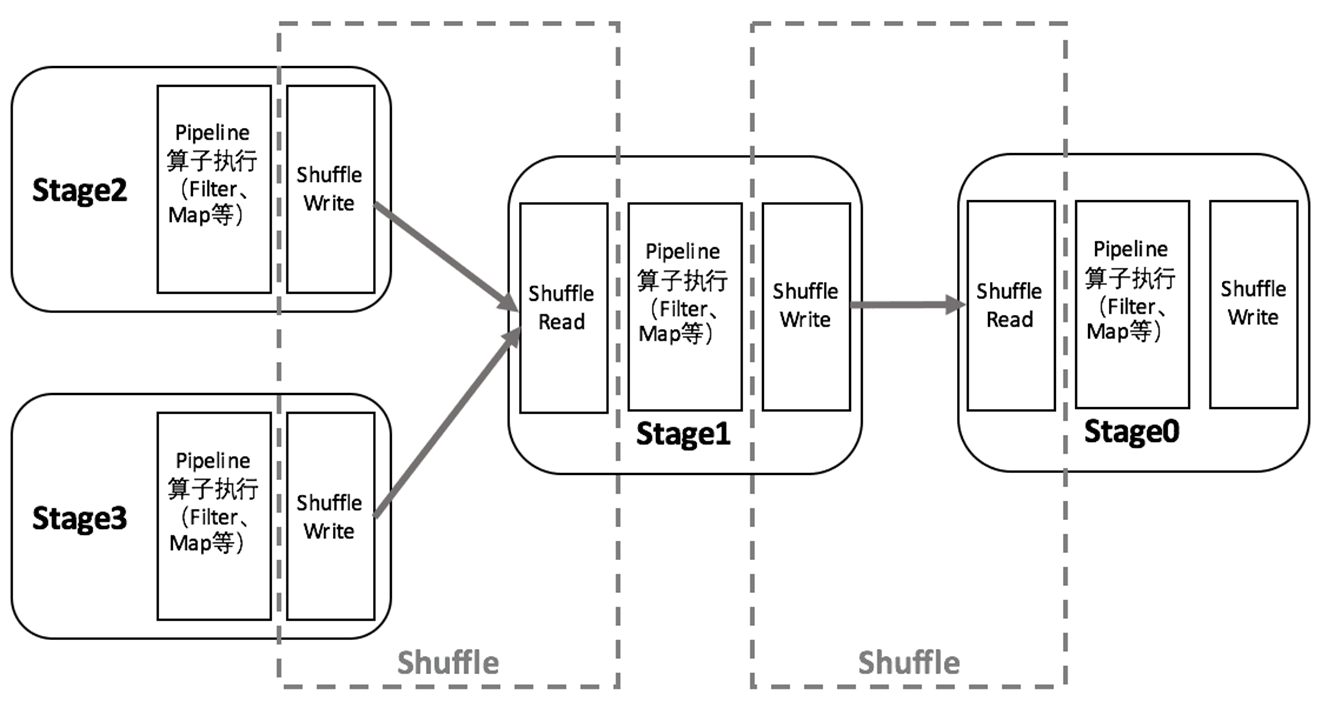
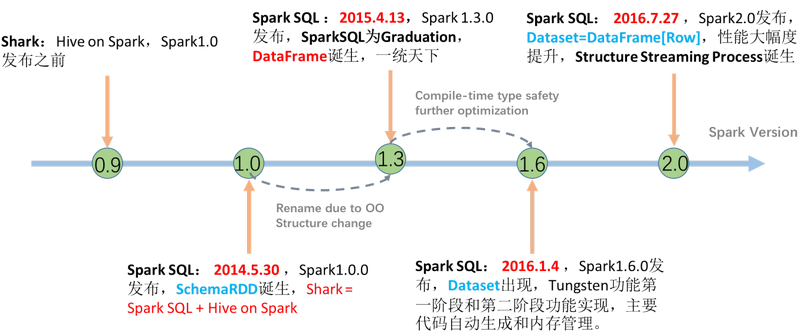

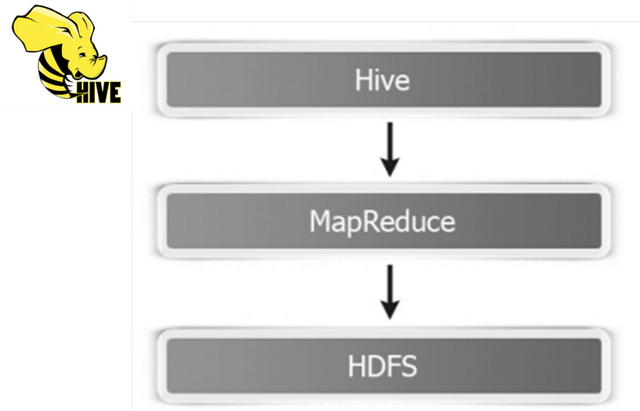
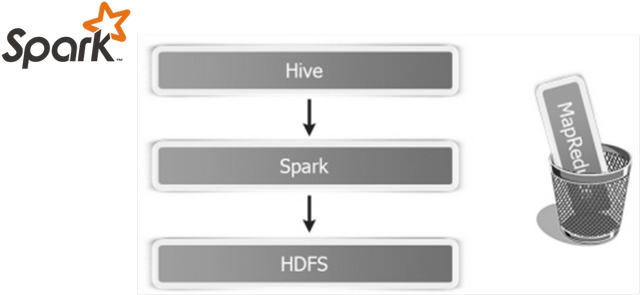

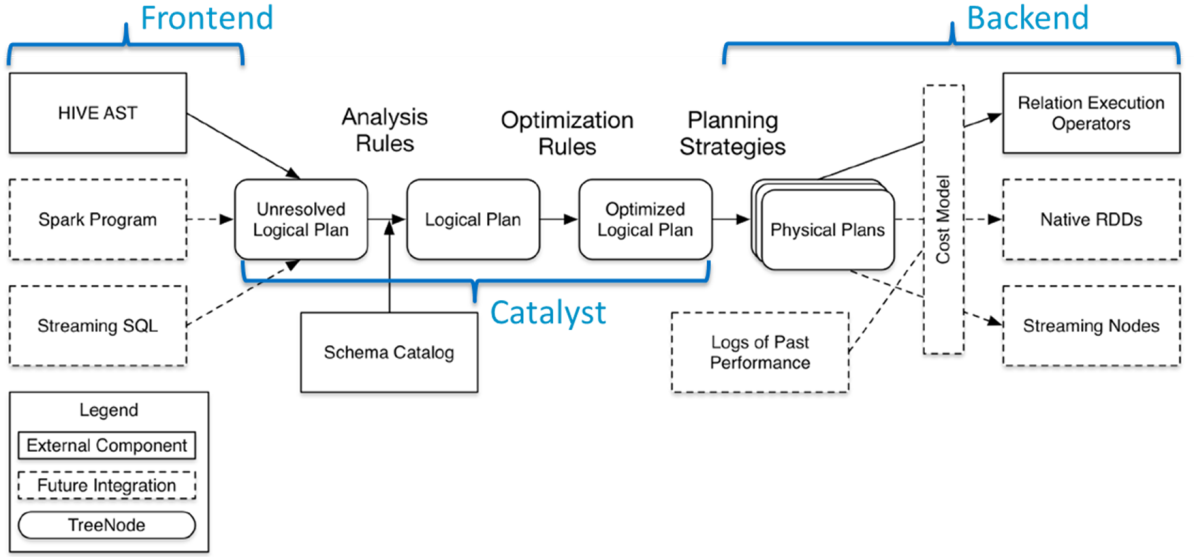
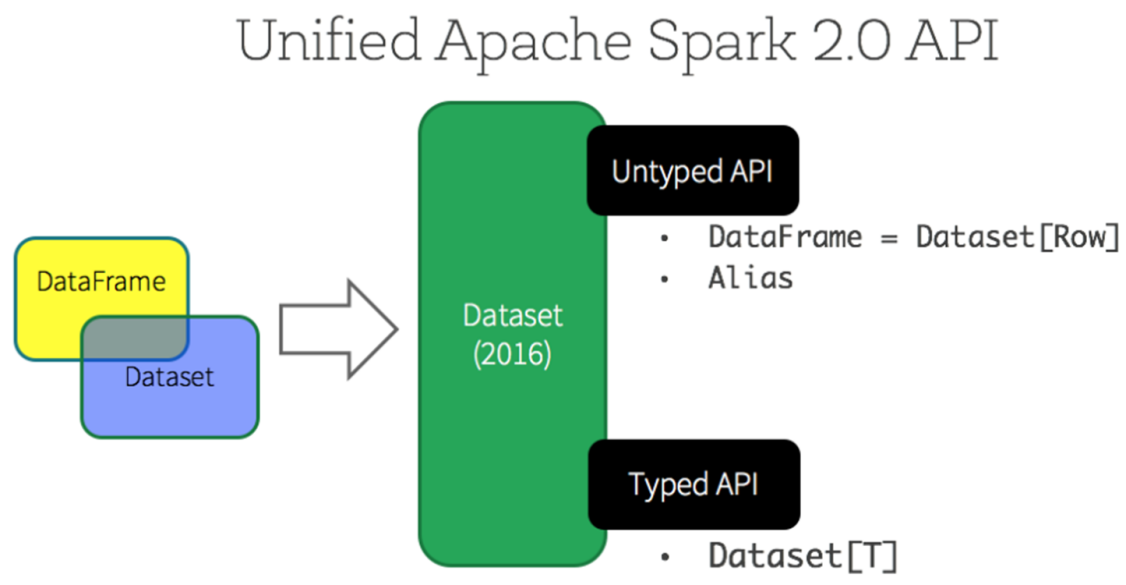


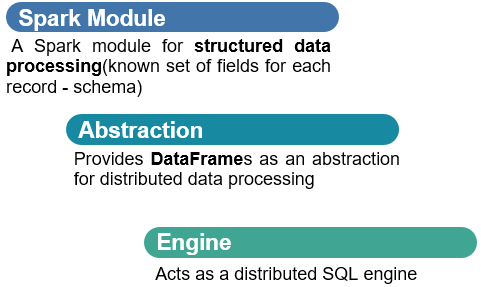

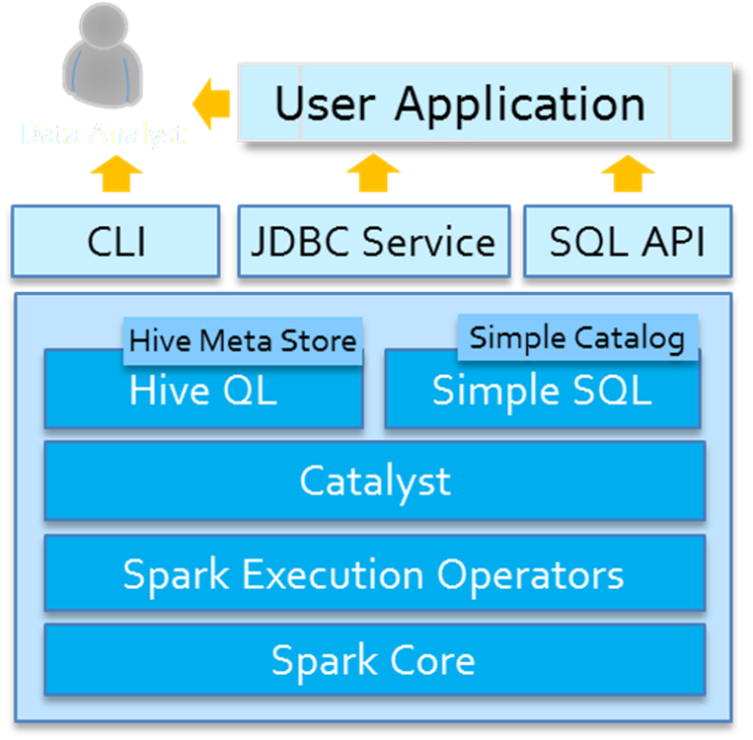
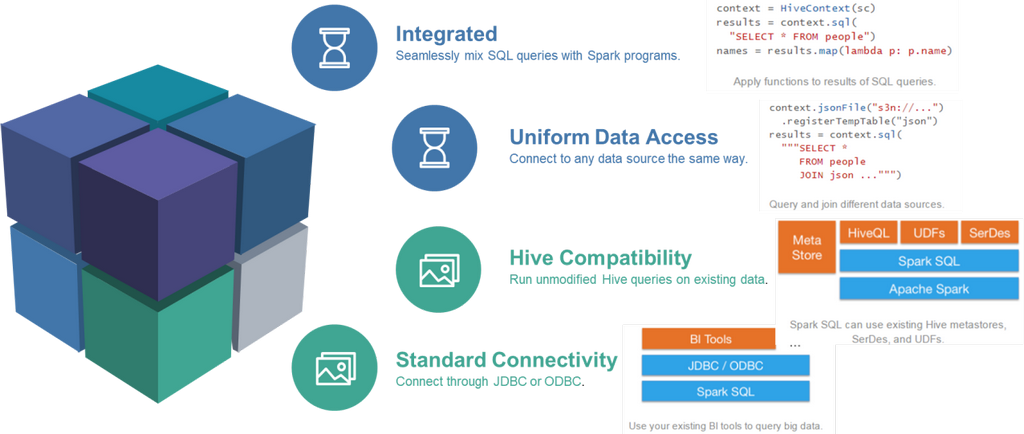

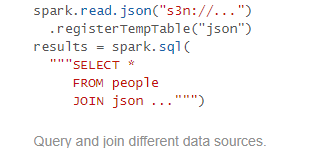



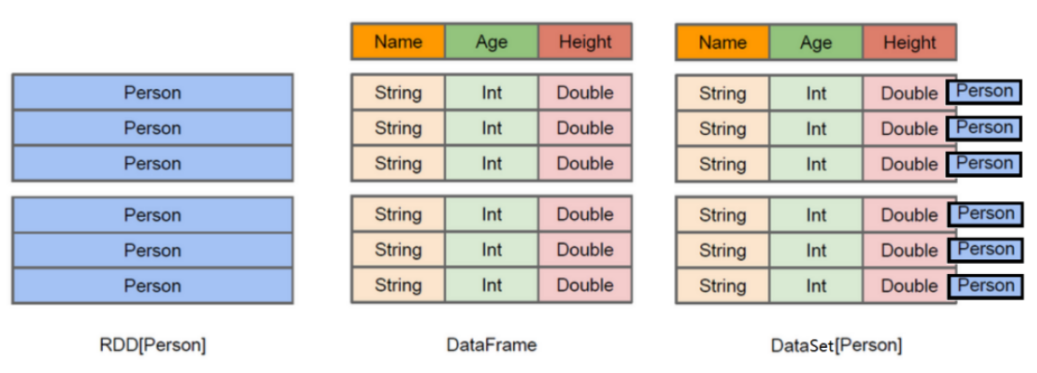
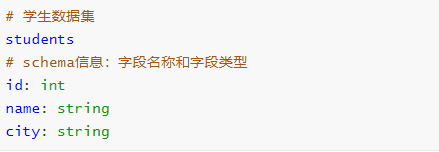







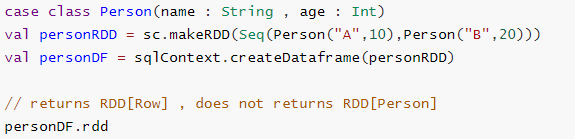

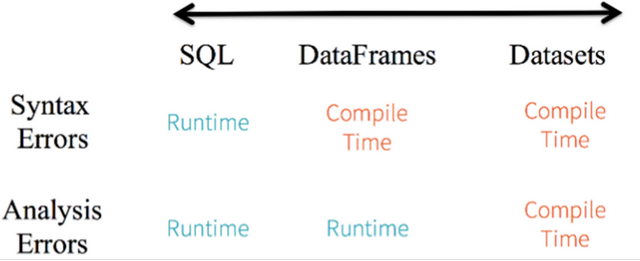


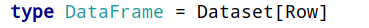

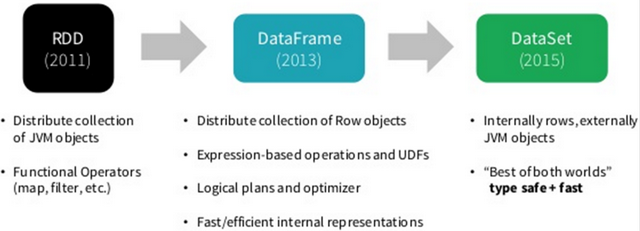

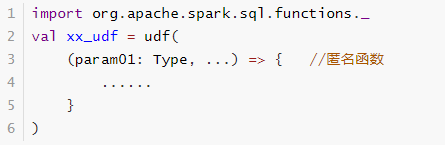

.png)