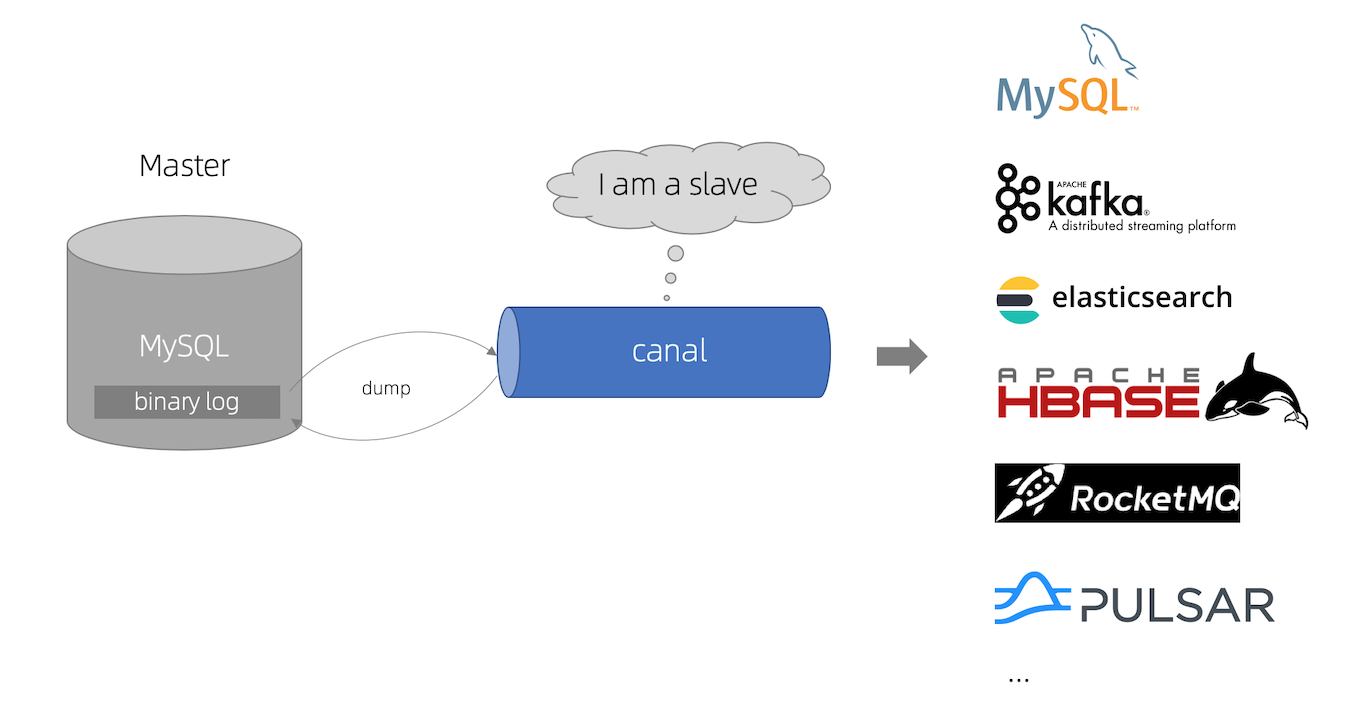
canal [kə’næl],译意为水道/管道/沟渠。
主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费.
canal 作为 MySQL binlog 增量获取和解析工具,可将变更记录投递到 MQ 系统中,比如 Kafka/RocketMQ,可以借助于 MQ 的多语言能力。
关注博主不迷路,获取更多干货资源
1 MySQL 1.1 Mysql部署
Docker hub上查找mysql镜像
从docker hub上(阿里云加速器)拉取mysql镜像到本地标签为5.7
创建容器
docker run -di --name =mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD =123456 mysql:5.7
进入MySQL容器
使用mysql客户端连接
docker exec -it mysql bash
1.2 Mysql开启binlog日志
用来记录mysql中的增加、删除、修改、清空操作select操作 不会 保存到binlog中
必须要 打开 mysql中的binlog功能,才会生成binlog日志
binlog日志就是一系列的二进制文件
-rw-rw---- 1 mysql mysql 669 11⽉月 10 21:29 mysql-bin.000001 1 mysql mysql 126 11⽉月 10 22:06 mysql-bin.000002 1 mysql mysql 11799 11⽉月 15 18:17 mysql-bin.00000
配置my.cnf
root@dfbf3fdefbdf:/# vim / etc/mysql/my .cnf
[mysqld] log-bin =mysql-bin binlog-format =ROW server_id =1 expire_logs_days =7 max_binlog_size = 500 m
重启mysql容器(dfbf3fdefbdf是容器id)
docker restart dfbf3 fdefbdf
进入sql命令行
docker exec -it mysql bashmysql -uroot -p123456
验证 my.cnf 配置是否生效:
show variables like 'binlog_format' ;show variables like 'log_bin' ;show master status;
1.3 可能遇到的问题
创建容器时报错:
WARNING: IPv4 forwarding is disabled. Networking will not work.
解决方式:
vim /usr/ lib/sysctl.d/ 00 -system.conf1
2 Canal介绍 2.1 Canal简介
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
数据库镜像
数据库实时备份
索引构建和实时维护(拆分异构索引、倒排索引等)
业务 cache 刷新
带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
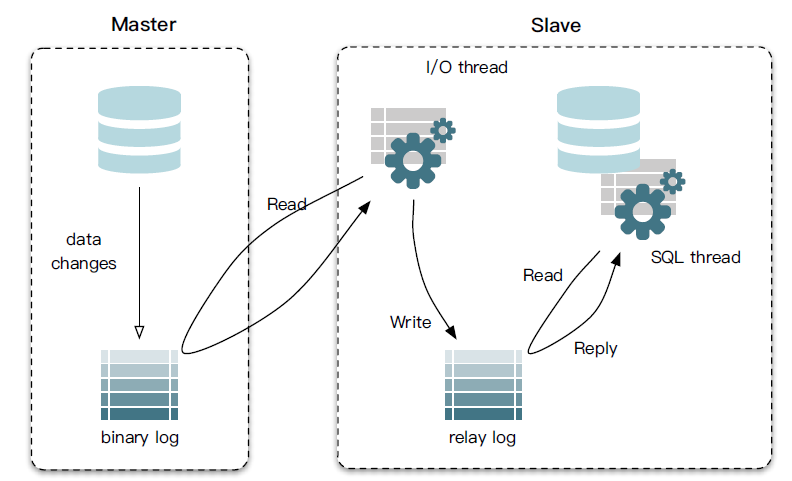
2.2 Mysql的主备复制原理
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
2.3 Canal的工作原理
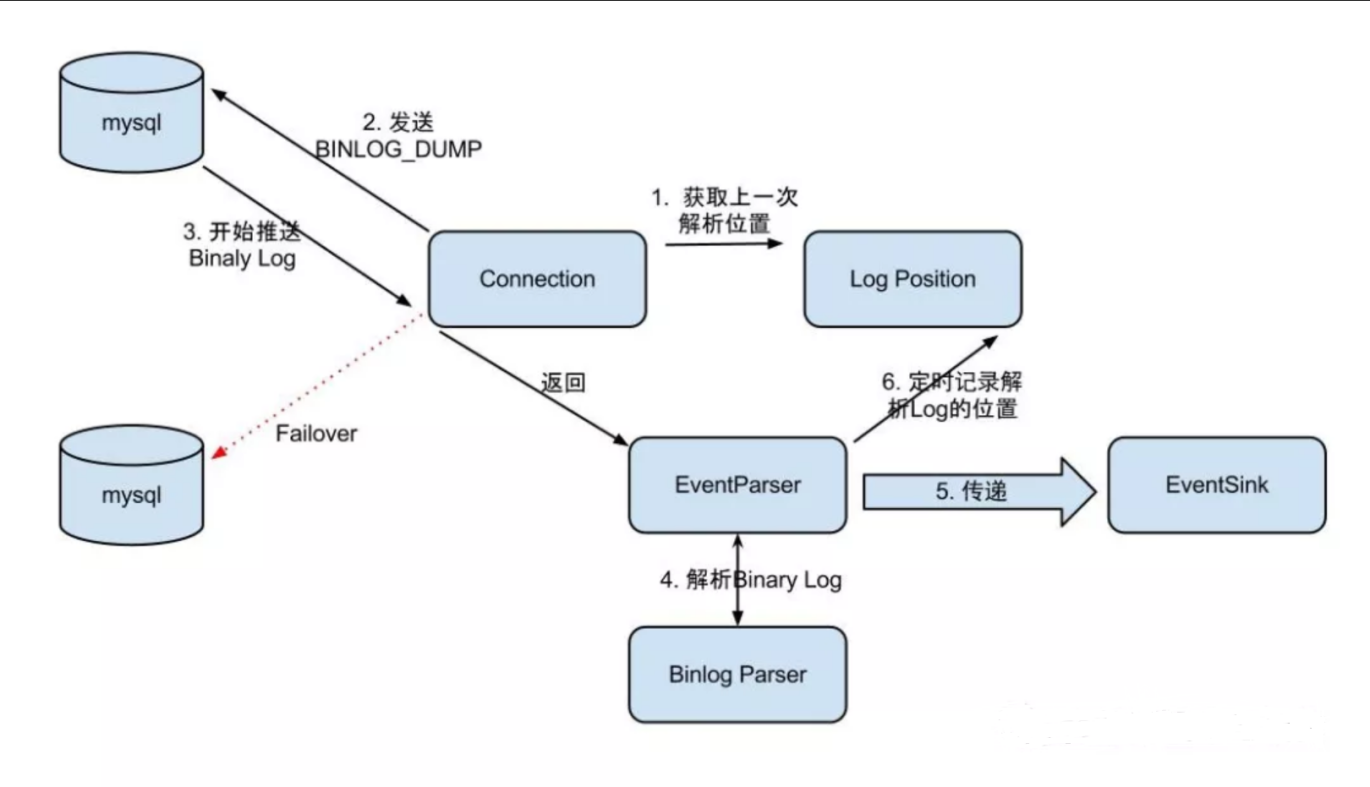
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
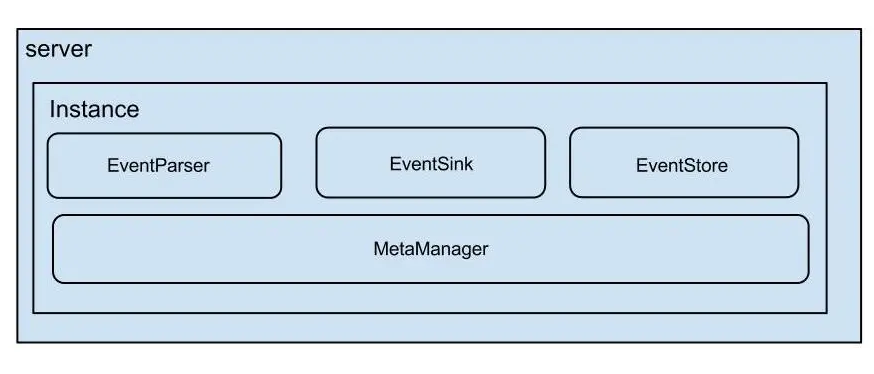
2.4 Canal的架构
server 代表一个 canal 运行实例,对应于一个 jvm
instance 对应于一个数据队列 (1个 canal server 对应 1..n 个 instance )
instance 下的子模块
eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作
eventStore: 数据存储
metaManager: 增量订阅 & 消费信息管理器
EventParser在向mysql发送dump命令之前会先从Log Position中获取上次解析成功的位置(如果是第一次启动,则获取初始指定位置或者当前数据段binlog位点)。mysql接受到dump命令后,由EventParser从mysql上pull binlog数据进行解析并传递给EventSink(传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功 ),传送成功之后更新Log Position。流程图如下:
EventSink起到一个类似channel的功能,可以对数据进行过滤、分发/路由(1:n)、归并(n:1)和加工。EventSink是连接EventParser和EventStore的桥梁。
EventStore实现模式是内存模式,内存结构为环形队列,由三个指针(Put、Get和Ack)标识数据存储和读取的位置。
MetaManager是增量订阅&消费信息管理器,增量订阅和消费之间的协议包括get/ack/rollback,分别为:
Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:batch id[唯一标识]和entries[具体的数据对象]
void rollback(long batchId),顾名思义,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
void ack(long batchId),顾名思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
3 Canal安装部署 3.1 Canal部署
操作步骤
说明
1
安装canalserver镜像
2
通过镜像生成canal-server容器
3
进入canal-server容器
4
执行/export/servers/canal/bin目录中的 startup.sh 启动canal
5
进入example日志文件查看是否有报错
3.2 Canal测试 3.2.1 创建测试数据库
操作步骤
说明
1
进入sql命令行
2
创建mysql数据库
3
切换到test数据库
4
在test数据库创建表userinfo;userinfo (id int(11) NOT NULL AUTO_INCREMENT,name varchar(255) DEFAULT NULL,age int(11) DEFAULT NULL,id)
3.2.2 配置canalserver端
1 进入canal-server容器
docker exec -it canal-server bash
2 修改 canal/conf目录中的 canal.properties 文件
vi /home/ admin/canal-server/ conf/canal.properties
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 #################################################1 11111 #canal-server监听的端口(TCP模式下,非TCP模式不监听1111 端口)11112 #canal-server metrics.pull监听的端口1000 1000 2 ,n)instance .memory.buffer.size = 16384 1 kbinstance .memory.buffer.memunit = 1024 instance .memory.batch.mode = MEMSIZEinstance .memory.rawEntry = trueinstance .detecting.enable = falseinstance .detecting.sql = insert into retl.xdual values(1 ,now()) on duplicate key update x=now()instance .detecting.sql = select 1 instance .detecting.interval.time = 3 instance .detecting.retry.threshold = 3 instance .detecting.heartbeatHaEnable = falseof the transaction will be cut into multiple transactions deliveryinstance .transaction.size = 1024 instance .fallbackIntervalInSeconds = 60 instance .network.receiveBufferSize = 16384 instance .network.sendBufferSize = 16384 instance .network.soTimeout = 30 instance .filter.druid.ddl = trueinstance .filter.query.dcl = falseinstance .filter.query.dml = falseinstance .filter.query.ddl = falseinstance .filter.table.error = falseinstance .filter.rows = falseinstance .filter.transaction.entry = falseinstance .binlog.format = ROW,STATEMENT,MIXED instance .binlog.image = FULL,MINIMAL,NOBLOBinstance .get.ddl.isolation = falseinstance .parser.parallel = true60 % available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()instance .parser.parallelThreadSize = 16 of 2 instance .parser.parallelBufferSize = 256 instance .tsdb.enable = trueinstance .tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance .destination:}instance .tsdb.url = jdbc:h2:${canal.instance .tsdb.dir}/h2;CACHE_SIZE=1000 ;MODE=MYSQL;instance .tsdb.dbUsername = canalinstance .tsdb.dbPassword = canal24 hourinstance .tsdb.snapshot.interval = 24 360 hour(15 days)instance .tsdb.snapshot.expire = 360 instance dir add/remove and start/stop instance 5 instance .tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xmlinstance .tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xmlinstance .global.mode = springinstance .global.lazy = falseinstance .global.manager.address = 127.0 .0 .1 :1099 instance .global.spring.xml = classpath:spring/memory-instance .xmlinstance .global.spring.xml = classpath:spring/file-instance .xmlinstance .global.spring.xml = classpath:spring/default-instance .xml192.168 .88 .20 :9092 0 16384 1048576 200 rocketMQ无意义1 33554432 50 100
修改内容如下
canal.serverMode = kafkacanal.destinations = examplecanal.mq.servers = 192.168 .88.20 :9092
3 修改 canal/conf/example目录中的 instance.properties 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 vi /home/admin/canal-server/conf/example/instance .properties.0 .26 + will autoGen instance .mysql.slaveId=0 instance .gtidon=falseinstance .master.address=192.168 .88 .10 :3306 instance .master.journal.name=instance .master.position=instance .master.timestamp=instance .master.gtid=instance .rds.accesskey=instance .rds.secretkey=instance .rds.instanceId=instance .tsdb.enable=trueinstance .tsdb.url=jdbc:mysql:instance .tsdb.dbUsername=canalinstance .tsdb.dbPassword=canalinstance .standby.address =instance .standby.journal.name =instance .standby.position =instance .standby.timestamp =instance .standby.gtid=instance .dbUsername=rootinstance .dbPassword=123456 instance .connectionCharset = UTF-8 instance .defaultDatabaseName =testinstance .enableDruid=falseinstance .pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==instance .filter.regex=test\\..*instance .filter.black.regex=0 3 1.1 .3 版本支持新语法
修改内容如下
canal.instance.master.address =192.168 .88.10 :3306 canal.instance.dbUsername =rootcanal.instance.dbPassword =123456 canal.instance.filter.regex =test\\..*canal.mq.topic =example
4 重启canal-server
5 启动大数据服务器的kafka集群
bin/kafka-server-start.sh config/ server.properties > /dev/ null 2 >&1 &
6 启动kafka的消费者命令行
cd /export/services/kafka ./kafka-simple-consumer-shell.sh --broker-list node2.itcast.cn:9092 --topic example./kafka-console-consumer.sh --bootstrap-server node2.itcast.cn:9092 --topic example --from-beginning
7 在mysql数据库中插入一条sql语句
8 观察kafka消费者命令行的输出
3.3 常见错误
启动canal-server后,example.log日志错误如下
错误原因:
启动docker时,docker进程会创建一个名为docker0的虚拟网桥,用于宿主机与容器之间的通信。当启动一个docker容器时,docker容器将会附加到虚拟网桥上,容器内的报文通过docker0向外转发。
解决方式:
确认下防火墙是否关闭,如果没有关闭需要关掉
查看防火墙状态:firewall-cmd --statestop firewalld.servicedisable firewalld.service
4 Canal采集业务数据到Kafka 4.1 配置Canal-Server
1进入canal-server容器
docker exec -it canal-server bash
2 修改 canal/conf目录中的 canal.properties 文件
vi canal-server/conf/canal.properties.mq .servers = 192.168 .88.20 :9092
3 修改 canal/conf/example目录中的 instance.properties 文件
canal.instance.master.address =192.168 .88.20 :3306 canal.instance.dbUsername =rootcanal.instance.dbPassword =123456 canal.instance.defaultDatabaseName =itcast_crmcanal.instance.filter.regex =itcast_crm\\..*
4 重启canal-server
/home/ admin/canal-server/ bin/restart.sh
4.2 导入业务数据到Mysql
导入数据后查看kafka有没有摄取到数据
关注博主不迷路