玉女心经
轻裘长剑,烈马狂歌。
忠胆义胆壮山河.
好一个风云来去的江湖客,好一个富贵如云你奈我何,剑光闪处如泣如歌。
关注博主不迷路,获取更多干货资源

1 大数据
1.1 Zookeeper
点击前往详细文档。Zookeeper 作为一个分布式的服务框架,主要用来
解决分布式集群中应用系统的一致性问题。
ZooKeeper提供的服务包括:
分布式消息同步和协调机制、服务器节点动态上下线、统一配置管理、负载均衡、集群管理等。
1.1.1 Zookeeper的选举机制
1.1.1.1 全新集群选举
选举状态:
LOOKING,竞选状态。
FOLLOWING,随从状态,同步leader状态,参与投票。
OBSERVING,观察状态,同步leader状态,不参与投票。
LEADING,领导者状态。
OBSERVING的节点不参与leader的选举
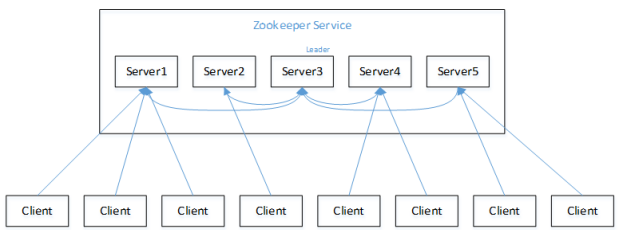
1.服务器1启动自己,给投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
2.服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
3.服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
4.服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
5.服务器5启动,后面的逻辑同服务器4成为小弟。
注意:如果按照5,4,3,2,1的顺序启动,那么5将成为Leader,因为在满足半数条件后,ZooKeeper集群启动,5的Id最大,被选举为Leader。
1.1.1.2 非全新集群选举
对于运行正常的zookeeper集群,中途有机器down掉,需要重新选举时,选举过程就需要加入
逻辑时钟、数据ID和服务器ID。
数据ID:数据新的version就大,数据每次更新都会更新version,在选举算法中数据越新权重越大。
服务器ID:就是我们配置的myid中的值,每个机器一个,比如1、2、3,编号越大在选择算法中的权重越大。
逻辑时钟:这个值从0开始递增,每次选举对应一个值。如果在同一次选举中,这个值是一致的。
这样选举的标准就变成:
1、逻辑时钟小的选举结果被忽略,重新投票;
2、统一逻辑时钟后,数据id大的胜出;
3、数据id相同的情况下,服务器id大的胜出;
根据这个规则选出leader。
1.1.2 ZooKeeper使用到的各个端口的作用
2888:Follower与Leader交换信息的端口。
3888:万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
1.2 HDFS
点击前往详细文档。
shell操作地址
1.2.1 HDFS读写数据流程
1.2.1.1 HDFS写数据流程
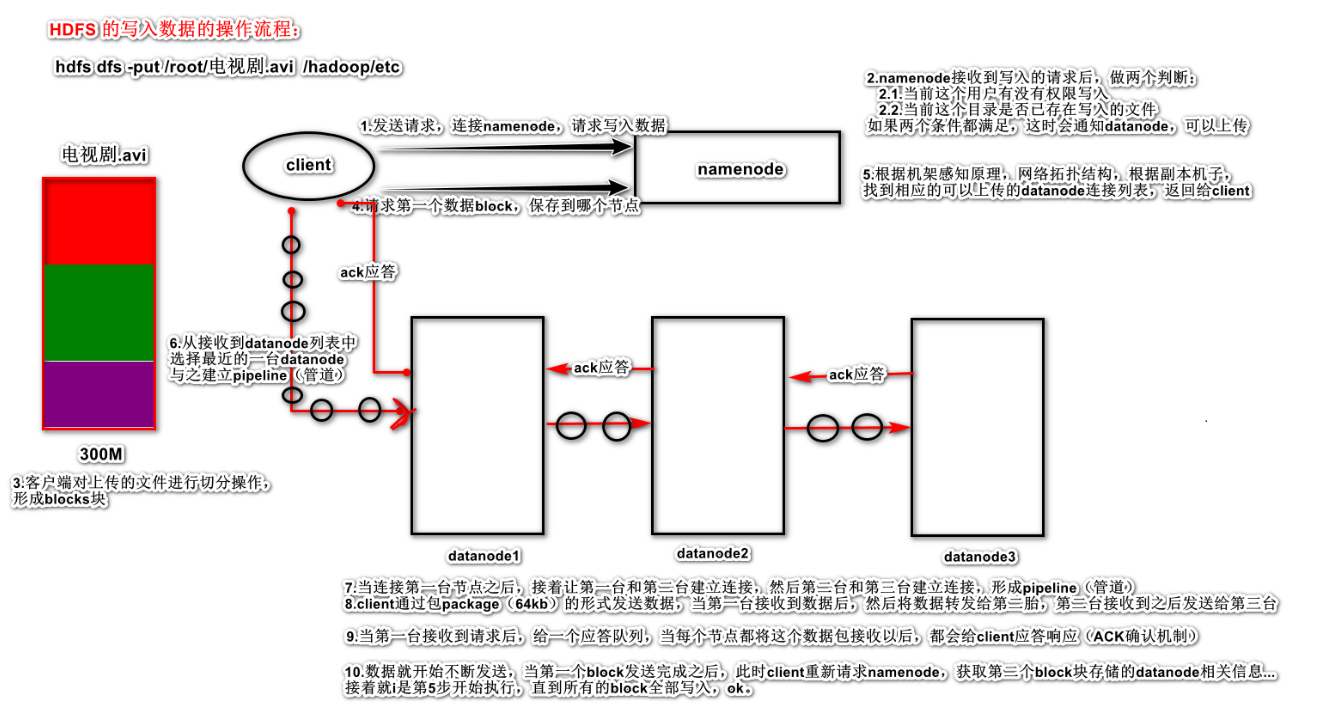
1.2.1.2 HDFS读数据流程
1.2.2 HDFS NameNode原理
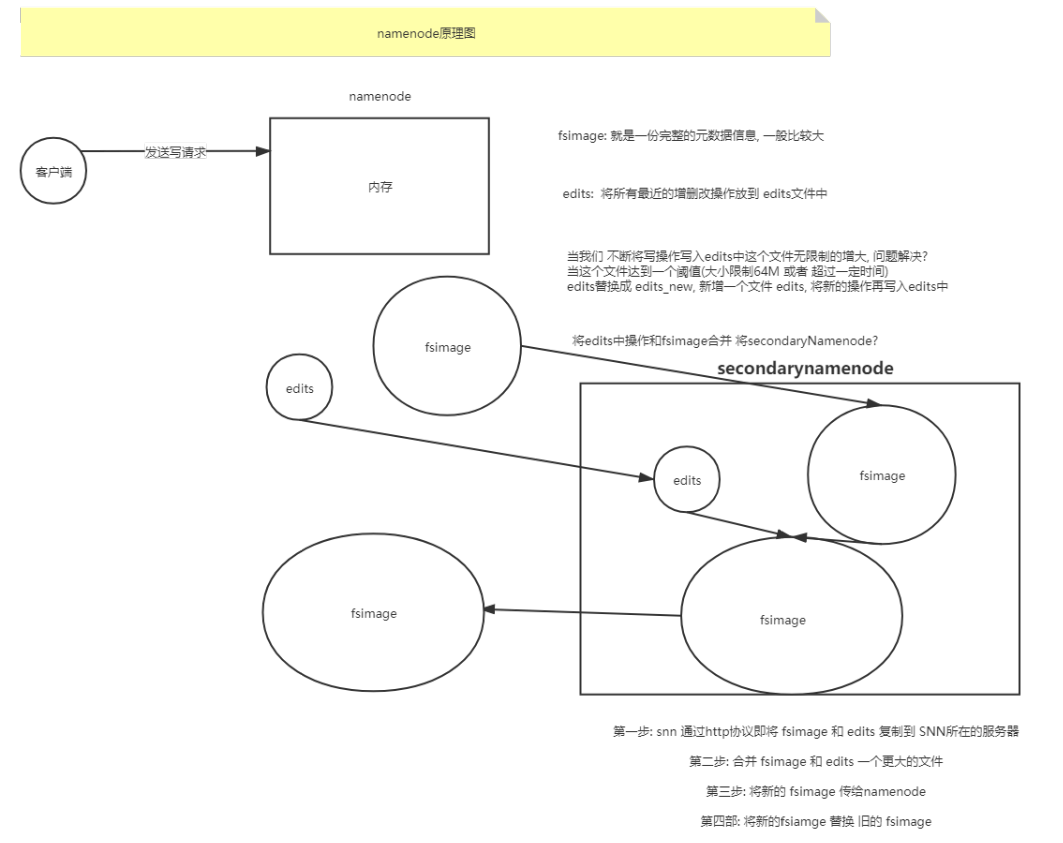
1.2.3 SecondaryNameNode
1.2.3.1 SecondaryNameNode的作用
1 | |
1.2.3.2 SecondaryNameNode出现的原因
1 | |
1.2.3.3 SecondaryNameNode唤醒合并的规则
1 | |
1.2.3.4 SecondaryNameNode工作过程
1 | |
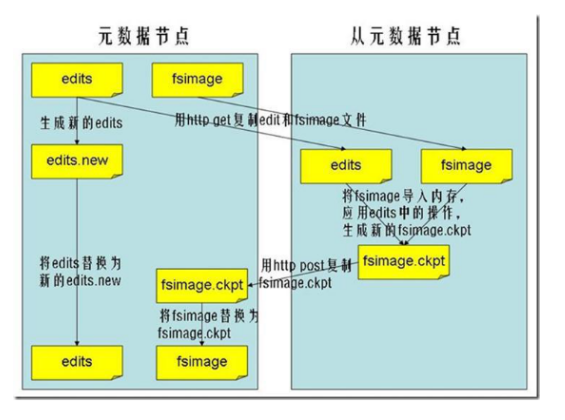
注意:SecondaryNameNode 在合并 edits 和 fsimage 时需要消耗的内存和 NameNode 差不多, 所以一般
SNN服务器内存一般要>=NameNode内存
SNN和NameNode放在不同的机器上
1.2.4 NameNode元数据恢复
当NameNode发生故障时,我们可以通过将SecondaryNameNode中数据拷贝到NameNode存储数据的目录的方式来恢复NameNode的数据
操作步骤:
1 杀死NameNode进程
1 | |
2 删除NameNode存储的数据
1 | |
3 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
1 | |
1 | |
4 重新启动NameNode
1 | |
1.3 MapperReduce
点击前往详细文档。1.3.1 MapperReduce底层运行机制
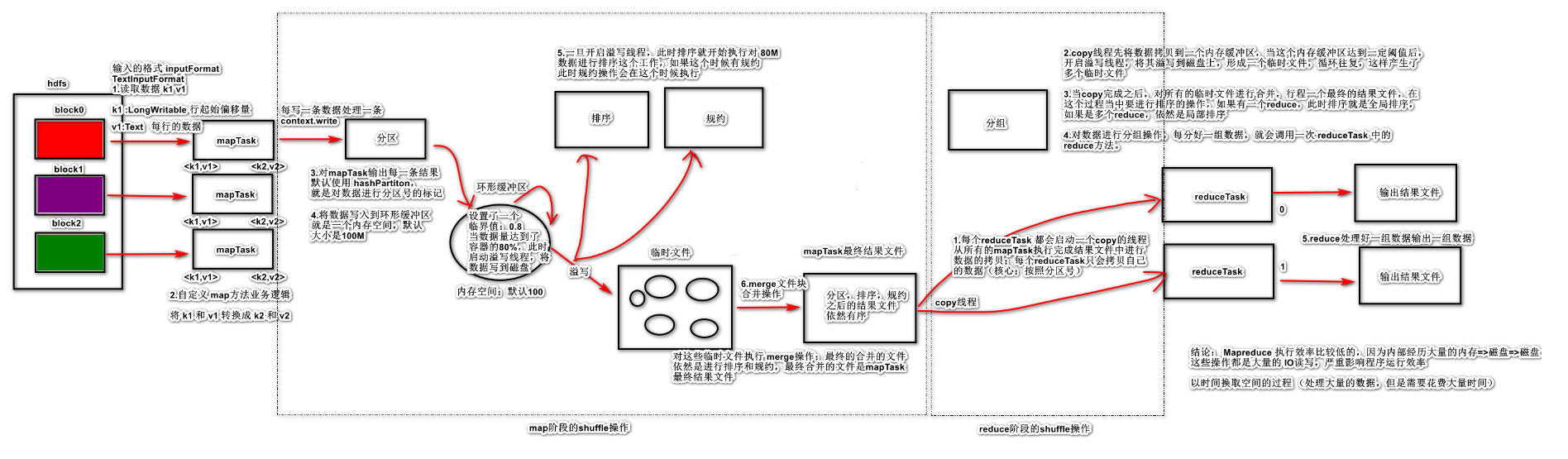
1.4 Yarn
点击前往详细文档。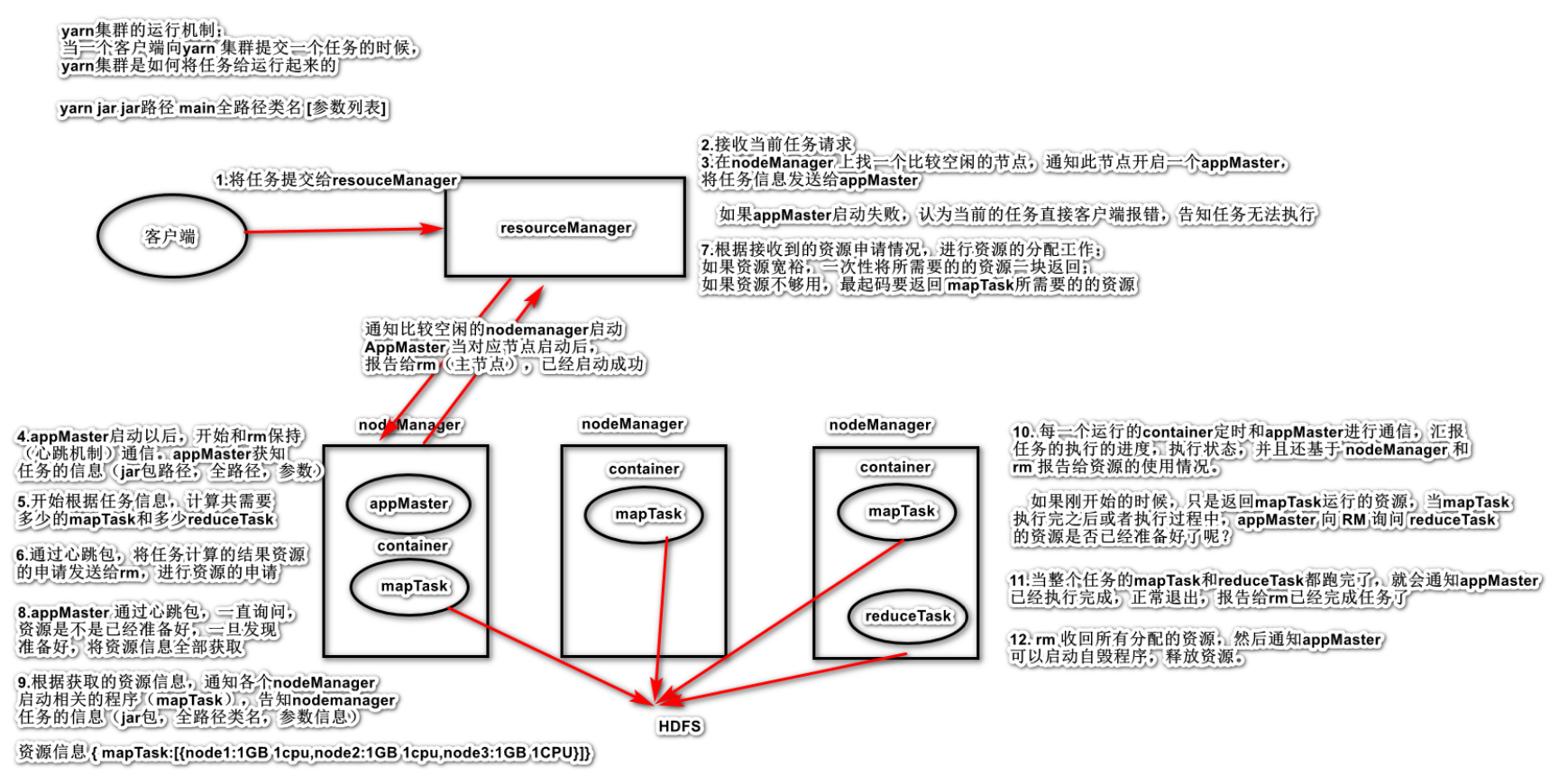
1.5 Hive
点击前往详细文档。hive 是基于 Hadoop的数据仓库的工具,依赖于hadoop
hive 本质上来说就是SQL翻译成MR的工具,甚至更进一步可以说hive就是一个MapReduce的客户端
hive 的数据保存在 HDFS 上
hive 可以使用类 SQL 查询功能
依赖mysql,mysql存储元数据
1.5.1 内部表和外部表
1.5.1.1 内部表
未被
external修饰的是内部表(managed table),内部表又称管理表,内部表数据存储的位置由hive.metastore.warehouse.dir参数决定(默认:/user/hive/warehouse),删除内部表会直接删除元数据(metadata)及存储数据,因此内部表不适合和其他工具共享数据。
1.5.1.2 外部表
在创建表的时候可以指定external关键字创建外部表,外部表对应的文件存储在location指定的hdfs目录下,向该目录添加新文件的同时,该表也会读取到该文件(当然文件格式必须跟表定义的一致)。
外部表因为是指定其他的hdfs路径的数据加载到表当中来,所以hive表会认为自己不完全独占这份数据,所以
删除hive外部表的时候,数据仍然存放在hdfs当中,不会删掉。
1.5.2 分区表和分桶表
1.5.2.1 分区表
分文件夹。在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了。
1.5.2.2 分桶表
分文件将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。
Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
1.5.2.3 好处
指定了分区分桶后,可以大幅度提升查询效率。
1 | |
1.5.2.4 注意
分区容易造成数据倾斜
1.5.3 四个By
1.
ORDER BY用于全局排序,就是对指定的所有排序键进行全局排序,使用ORDER BY的查询语句,最后会用一个Reduce Task来完成全局排序。
2.
sort by用于分区内排序,即每个Reduce任务内排序。,则sort by只保证每个reducer的输出有序,不保证全局有序。局部排序,但是reduce只有一个话和order by功能一样,做全局排序
3.
distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。类似MR的k2进行分区
4.
cluster by(字段) 除了具有Distribute by的功能外,还兼具sort by的排序功能。。
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by。
如果distribute by字段和sort by字段等价于cluster by字段 ,只能升序排列,不能降序排列
生产一般不做全局排序,都是先用sort by查出每个分区的top几个字段,再对这些字段做order by排序。
1.5.4 静态分区和动态分区
静态分区
1 | |
动态分区
1 | |
静态分区和动态分区
1 | |
注意:hive的动态分区只能放在静态分区后面。因为hive解析SQL的时候,是先去创建静态分区文件夹,再解析SQL,再根据解析的结果去创建动态文件夹,再去插入。
之所以产生这个,因该是hive的设计缺陷,如果改成先解析SQL,再去创建文件夹的话,那么动态分区和静态分区混用的时候,顺序就没关系了。
1.6 Redis
点击前往详细文档。1.6.1 缓存穿透
缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。
一言以蔽之:查询Key,缓存和数据源都没有,频繁查询数据源
比如用一个不存在的用户id获取用户信息,无论论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
如何解决缓存穿透:当查询不存在时,也将结果保存在缓存中。[PS:布隆过滤器虽快,但不能准确判断key值是否已存在,不推荐]
1.6.2 缓存击穿
缓存击穿:key对应的数据库存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
一言以蔽之:查询Key,缓存过期,大量并发,频繁查询数据源
业界比较常用的做法:
使用互斥锁。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db(查询数据库),而是先使用Redis的SETNX操作去set一个mutex key【此key作为互斥锁,在指定的 key 不存在时,为key设置指定的值,返回1;key存在时返回0】,只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据。
1 | |
1.6.3 缓存雪崩
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
一言以蔽之:缓存不可用(服务器重启或缓存失效),频繁查询数据源
与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key。
缓存正常从Redis中获取,示意图如下:
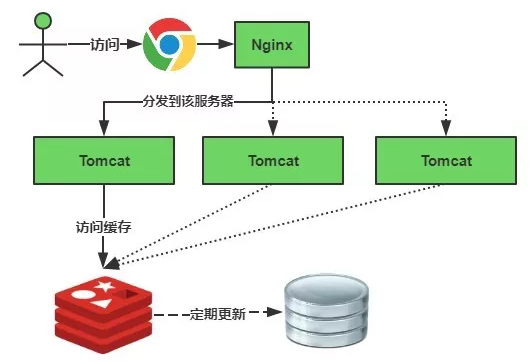
缓存失效瞬间示意图如下:
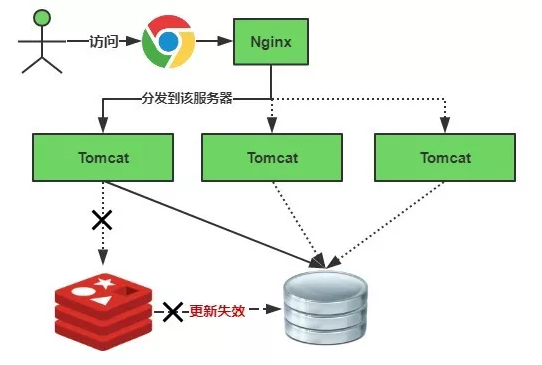
缓存失效时的雪崩效应对底层系统的冲击非常可怕!
大多数系统设计者考虑用
加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。
还有一个简单方案就时
将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
1.6.4 过期策略
当
Redis中缓存的key过期了,Redis什么时间清理。
定时过期每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
惰性过期只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
定期过期每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
1.6.5 内存淘汰策略
在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据
实际项目中设置内存淘汰策略:maxmemory-policy
allkeys-lru,移除最近最少使用的key。
1 | |
1.6.6 Redis的持久化
1.6.6.1 RDB持久化方案
1 | |
1.6.6.2 AOF持久化方案
采用AOF持久方式时,Redis会把每一个写请求都记录在一个日志文件里。在Redis重启时,会把AOF文件中记录的所有写操作顺序执行一遍,确保数据恢复到最新。
AOF默认是关闭的,如要开启,进行如下配置:
1 | |
AOF提供了三种fsync配置:
always/everysec/no,通过配置项[appendfsync]指定:
1 | |
1.6.7 Redis的命名规范
使用统一的命名规范
一般使用业务名(或数据库名)为前缀,
用冒号分隔,例如,业务名:表名:id。例如:
shop:usr:msg_code(电商:用户:验证码)
控制key名称的长度,不要使用过长的key在保证语义清晰的情况下,尽量减少Key的长度。有些常用单词可使用缩写,例如,user缩写为u,messages缩写为msg。
名称中不要包含特殊字符包含空格、单双引号以及其他转义字符
1.6.8 集群
问题一:
Redis的多数据库机制,了解多少

问题二:
懂Redis的批量操作么?

问题三:
Redis集群机制中,你觉得有什么不足的地方吗?

问题四:
在Redis集群模式下,如何进行批量操作?

问题五:
懂Redis事务么?

1.7 HBase
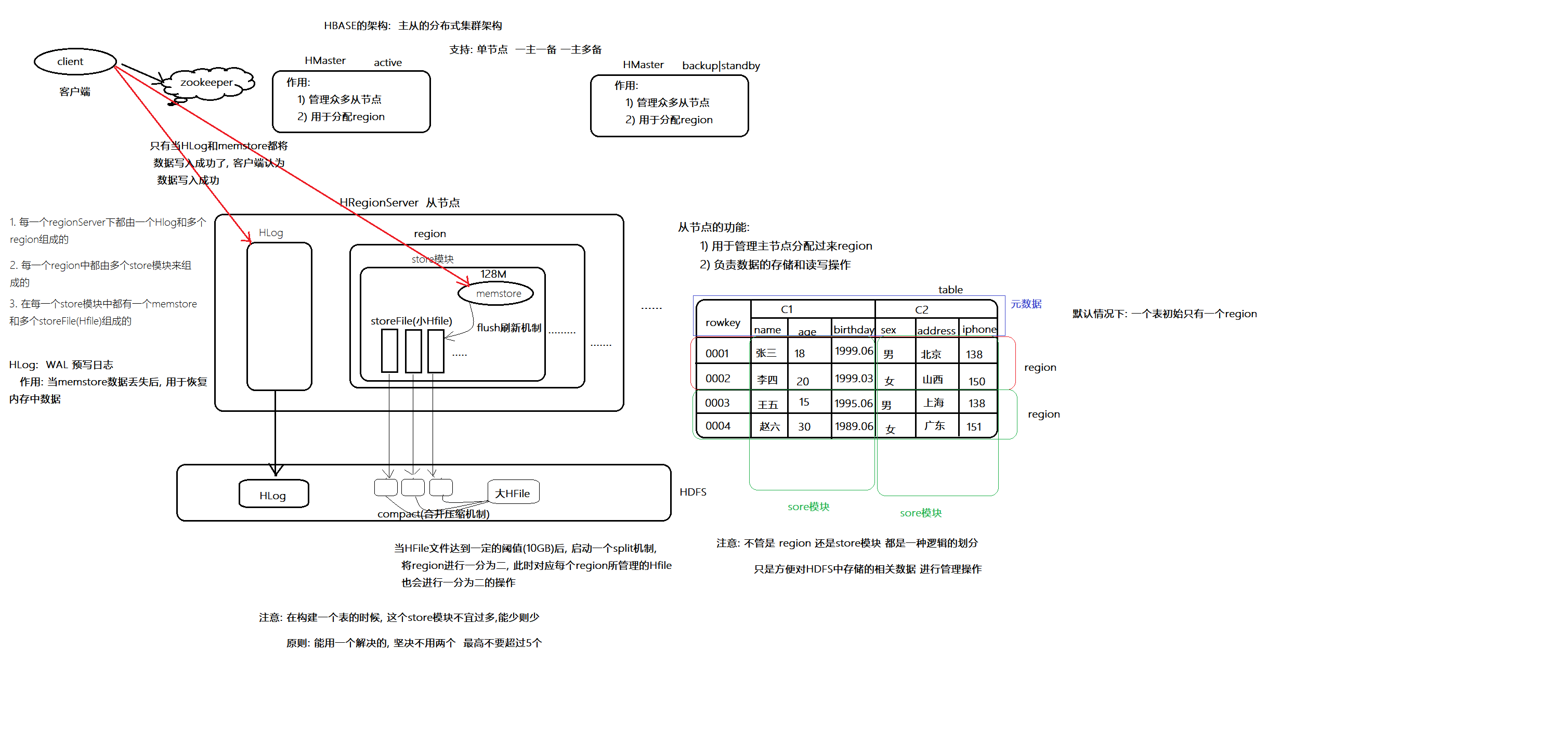
点击前往详细文档。1.7.1 架构
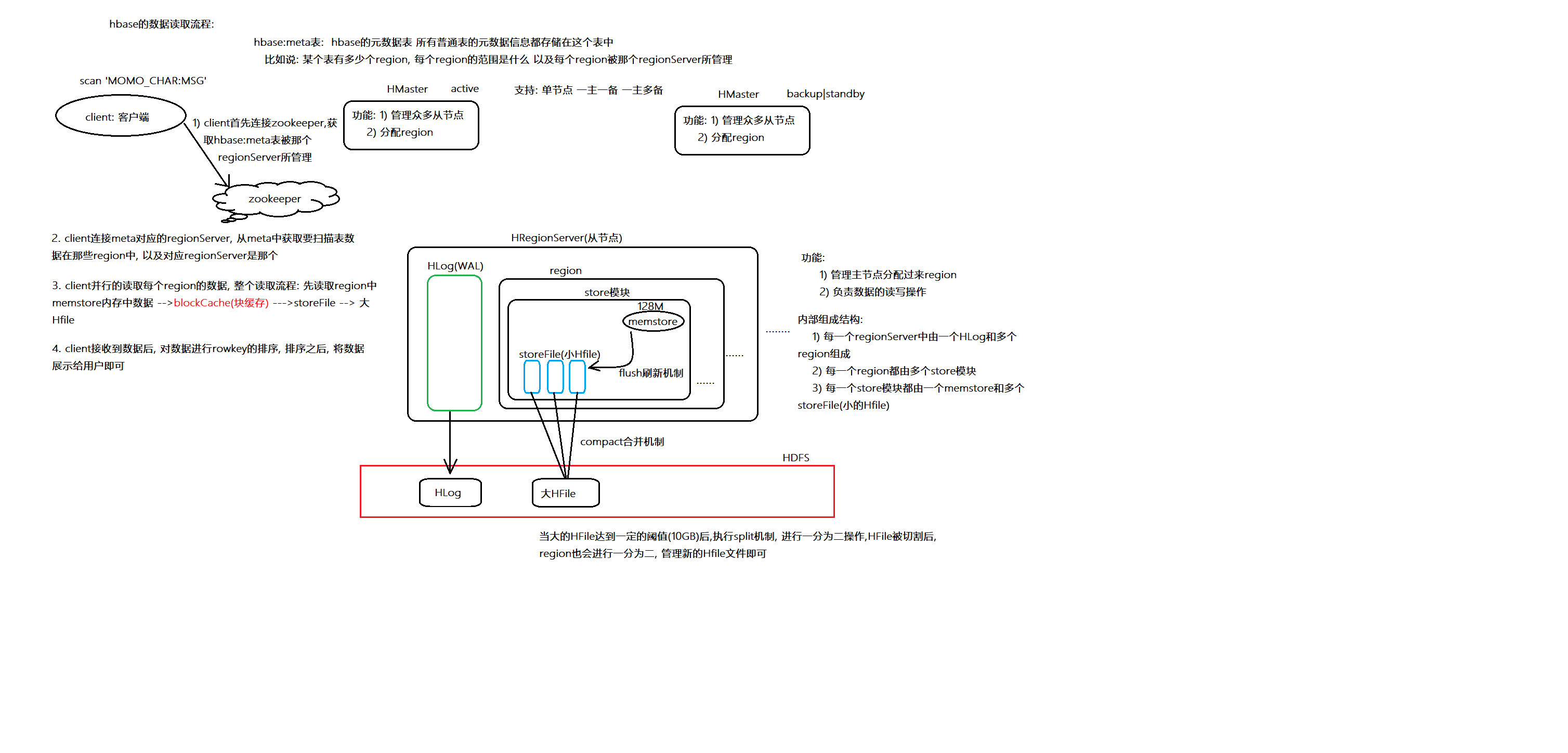
1.7.2 读取数据流程
第一步: client首先连接zookeeper, 获取hbase:meta表对应的region被那个regionServer所管理了
第二步: client连接meta表对应的regionServer, 在mata表获取要查询的表有那些region, 以及这些 region被那个regionServer所管理, 将对应regionServer列表返回客户端
第三步: client连接对应的regionServer, 开始进行并行的读取数据: 先到memstore –> blockCache –> storeFile –> 大Hfile
第四步: client接收到各个region返回来的数据后, 对数据进行排序操作, 将排序后的数据展示给用户即可
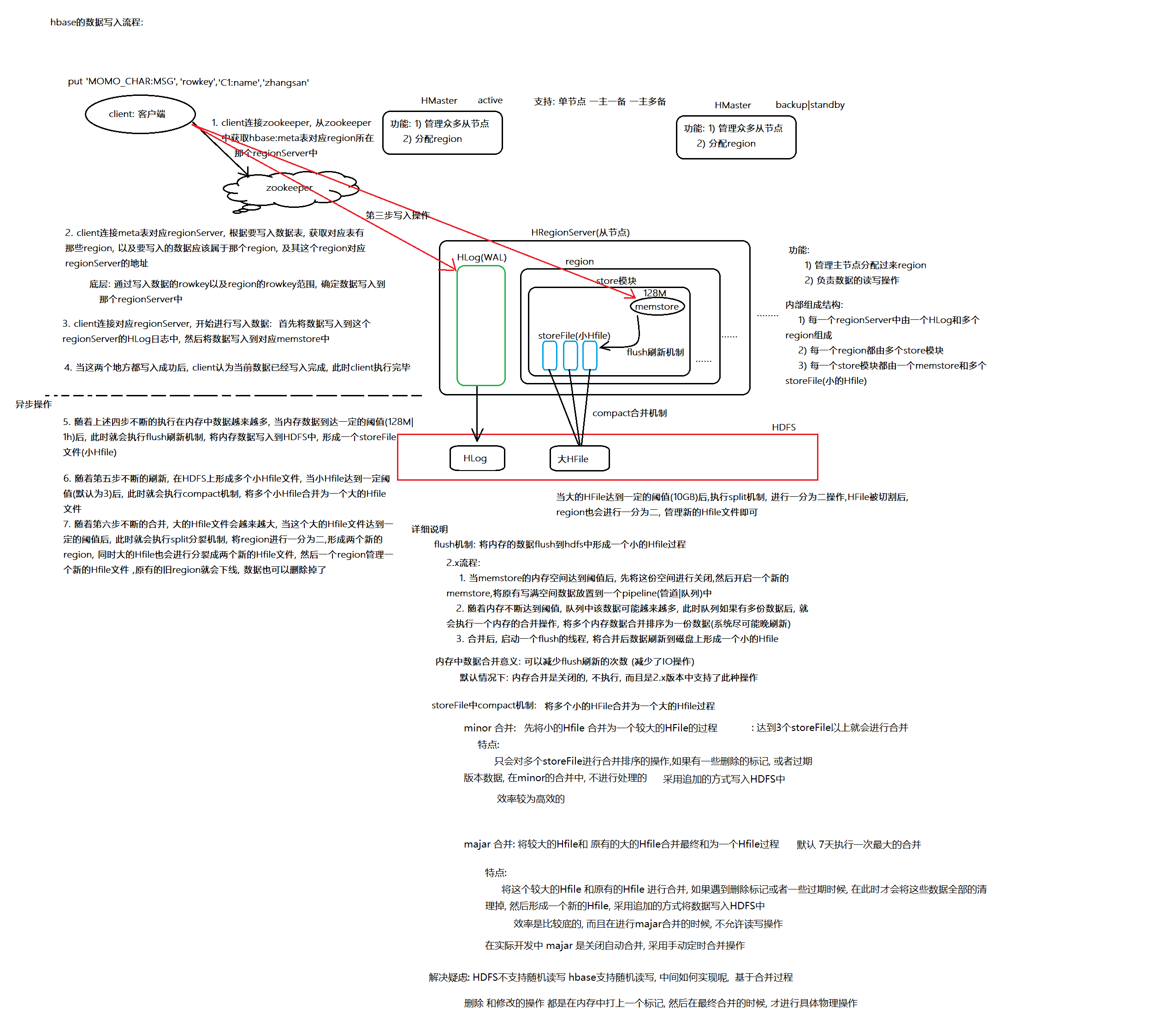
1.7.3 存储数据流程
客户端的流程:第一步: client首先连接zookeeper, 获取hbase:meta表对应的region被那个regionServer所管理了
第二步: client连接meta表对应的regionServer,在meta表获取要写入表有那些region, 以及根据rowkey
以及每一个region的范围确定要写入到那个region中, 将这个region对应的regionServer返回给客户端第三步: client连接对应的regionServer, 开始进行写入数据: 首先将数据写regionServer的HLog中, 然后
将数据写入到对应的region的memstore中第四步: 当这两个地方都写入成功后, 客户端认为数据已经写入成功, 此时客户端写入操作执行完成
服务端内部流程:第五步: 随着上述四步不断写入, 在memstore中也会越来越多, 当memstore中数据达到一定的阈值(128M|1h)后, 就会
执行flush刷新机制, 将内存中数据刷新到HDFS中, 形成一个小的Hfile文件第六步: 随着第五步不断的刷新, 在HDFS上形成多个小Hfile文件, 到小的Hfile文件达到一定的阈值(默认3个)后,
此时就会执行compact的合并机制, 将多个小Hfile合并为一个大的HFile文件第七步:随着第六步不断的合并, 大的Hfile也会变的越来越大, 当大Hfile达到一定的阈值后, 就会执行split分裂
机制, 将对应region进行一分二,形成两个新的region, 此时对应大Hfile也会也进行一分二的操作, 然后让每
一个region管理一个Hfile文件, 原有就得region和旧的Hfile就会被下线和删除操作
注意: 读写操作 与master无关, 所以master短暂宕机, 并不会影响hbase的数据读写
master宕机会影响关于元数据的修改操作, 以及region的分配操作
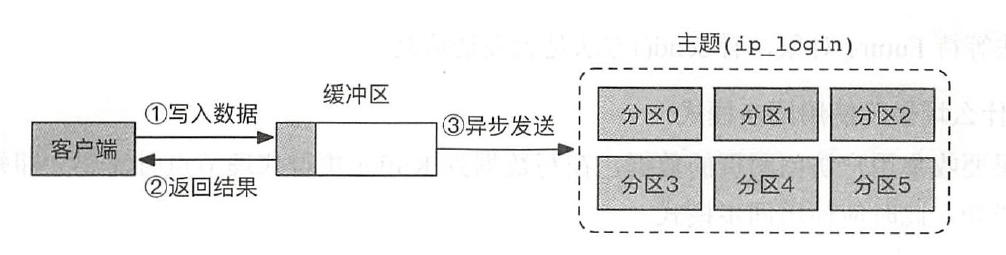
1.8 Kafka
点击前往详细文档。1.8.1 消费者和消费者组
1.8.1.1 为什么需要消费者组
当生产者向Kafka 系统主题写消息数据的速度比消费者读取的速度要快时,随着时间的增长,主题中的消息数据将出现越来越严重的堆积现象。面对这类情况,通常可以增加多个消费者程序来水平扩展,从而解决这种堆积现象。
消费者组是Kafka 系统提供的一种可扩展、高容错的消费者机制。
1.8.1.2 消费者和消费者组关系
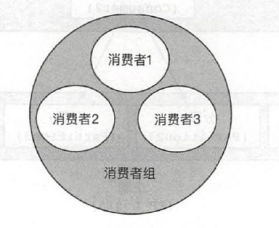
1.8.1.3 消费者和分区的对应关系

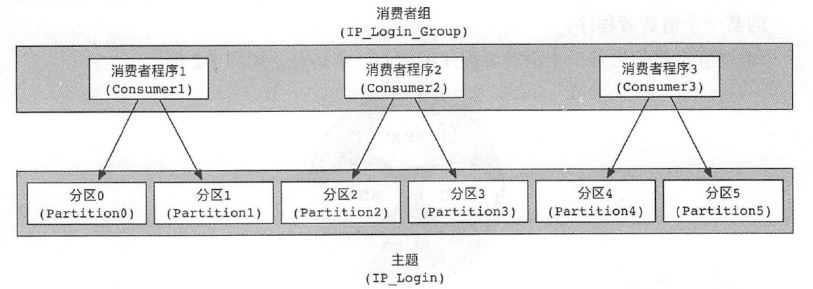
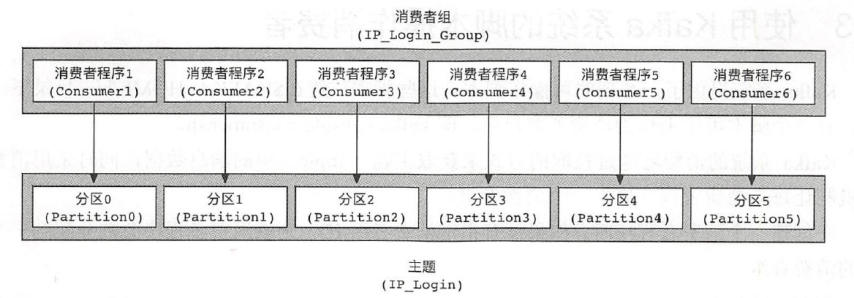

总之,消费者客户端可以通过增加消费者组中消费者程序的个数来进行水平扩展,提升读取主题消息数据的能力。
因此, 在Kafka 系统生产环境中, 建议在创建主题时给主题分配多个分区,这样可以提高读取的性能。
消费者程序的数量尽量不要超过主题的最大分区数,即需要消费者程序的数量 = 最大分区数
小于的话,个别消费者压力较大,
大的话,多出来的消费者程序是空闲的,浪费系统资源。
1.8.2 同步模式和异步模式
1.8.2.1 同步模式
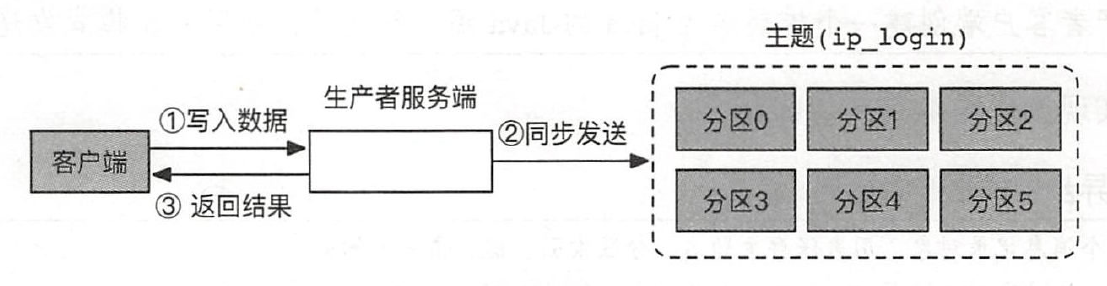
1 | |
1.8.2.2 异步模式
1 | |
1.8.3 分区策略
第1种:如果指定了分区号,那么数据就会全部进入到指定的分区里面去
第2种:如果没有给定分区号,但是给了数据的key,那么通过key的hash取值来决定数据到哪一个分区里面去
第3种:没有给定分区号,也没有给定key值,通过轮询的方式来决定数据去哪一个分区
自定义分区策略
1 | |
1.8.4 ISR(n-Sync Replicas 副本同步队列)
每个分区的 leader 会维护一个 ISR 列表,ISR 列表里面就是 follower 副本的 Borker 编号。每个Partition都有它自己独立的ISR。
每个Replication集合中的Partition都会选出一个唯一的Leader,所有的读写请求都由Leader处理。
每个Cluster中会选举出一个Broker来担任Controller,负责处理Partition的Leader选举,协调Partition迁移等工作。
partition的leader和follower之间的监控通过ZK完成。
写是都往leader上写,读也只在leader上读,flower只是数据的一个备份,保证leader被挂掉后顶上来,并不往外提供服务。
AR(Assigned Replicas):分区中的所有副本统称为 AR
OSR(Out-of-Sync Replied):于leader副本同步滞后过多的副本(不包括leader副本)
ISR(In Sync Replicas):所有与leader副本保持一定程度同步的副本(包括leader副本在内)
AR = ISR + OSR。正常情况下,所有的follower副本都应该与leader 副本保持 一定程度的同步,即AR=ISR,OSR集合为空。
1.8.5 ACK(消息高可靠性,不丢失)
1 | |
1 | |
1.8.6 Kafka选举
1.8.6.1 Controller选举
在Kafka集群中会有一个或多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态等工作。比如当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。再比如当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
Kafka Controller的选举是依赖Zookeeper来实现的,在Kafka集群中哪个broker能够成功创建/controller这个临时(EPHEMERAL)节点他就可以成为Kafka Controller。
一般就是先启动的就是了
1.8.6.2 分区Leader选举
分区leader副本的选举由Kafka Controller 负责具体实施。当创建分区(创建主题或增加分区都有创建分区的动作)或分区上线(比如分区中原先的leader副本下线,此时分区需要选举一个新的leader上线来对外提供服务)的时候都需要执行leader的选举动作。基本思路是按照AR集合中副本的顺序查找第一个存活的副本,并且这个副本在ISR集合中。一个分区的AR集合在分配的时候就被指定,并且只要不发生重分配的情况,集合内部副本的顺序是保持不变的,而分区的ISR集合中副本的顺序可能会改变。注意这里是根据AR的顺序而不是ISR的顺序进行选举的。这个说起来比较抽象,有兴趣的读者可以手动关闭/开启某个集群中的broker来观察一下具体的变化。
还有一些情况也会发生分区leader的选举,比如当分区进行重分配(reassign)的时候也需要执行leader的选举动作。这个思路比较简单:从重分配的AR列表中找到第一个存活的副本,且这个副本在目前的ISR列表中。
再比如当发生优先副本(preferred replica partition leader election)的选举时,直接将优先副本设置为leader即可,AR集合中的第一个副本即为优先副本。
1.8.6.3 消费者组Leader选举
如果消费组内还没有leader,那么第一个加入消费组的消费者即为消费组的leader。如果某一时刻leader消费者由于某些原因退出了消费组,那么会重新选举一个新的leader,这个重新选举leader的过程又更“随意”了,相关代码如下:
1 | |
解释一下这2行代码:在GroupCoordinator中消费者的信息是以HashMap的形式存储的,其中key为消费者的member_id,而value是消费者相关的元数据信息。leaderId表示leader消费者的member_id,它的取值为HashMap中的第一个键值对的key,这种选举的方式基本上和随机无异。总体上来说,消费组的leader选举过程是很随意的。
1.8.7 Zookeeper在Kafka中的作用
1.8.7.1 Broker注册
Broker是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了Zookeeper。在Zookeeper上会有一个专门用来进行Broker服务器列表记录的节点:
1.8.7.2 Topic注册
在Kafka中,同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些
分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点来记录
1.8.8 kafka扩容
下面的例子将主题foo1,foo2的所有分区移动到新的broker 5,6。移动结束后,主题foo1和foo2所有的分区都会只会在broker 5,6。
1.8.9.1 迁移所有分区到新机器
分区分配工具的3种模式 -
1 | |
1.执行迁移工具需要接收一个json文件,首先需要你确认topic的迁移计划并创建json文件,如下所示
1 | |
2.一旦json准备好,使用分区重新分配工具生成一个“候选人”分配规则 -
1 | |
3.生成从主题foo1,foo2迁移所有的分区到broker 5,6的候选人分配规则。注意,这个时候,迁移还没有开始,它只是告诉你当前分配和新的分配规则,当前分配规则用来回滚,新的分配规则保存在json文件(例如,我保存在 expand-cluster-reassignment.json这个文件下)然后,用--execute选项来执行它。
1 | |
4.最后,--verify 选项用来检查parition重新分配的状态,注意, expand-cluster-reassignment.json(与--execute选项使用的相同)和--verify选项一起使用。
1 | |
1.8.9.2 自定义分区分配和迁移
分区重新分配工具也可以有选择性将分区副本移动到指定的broker。当用这种方式,假定你已经知道了分区规则,不需要通过工具生成规则,可以跳过--generate,直接使用—execute
下面的例子是移动主题foo1的分区0到brokers 5,6 和主题foo2的分区1到broker 2,3。
1.手工写一个自定义的分配计划到json文件中 -
1 | |
2.--execute 选项执行分配处理
1 | |
3.最后使用--verify 验证。
1 | |
1.8.9 如何保证kafka消费的顺序性
一个Topic里的数据放在各个partition里,
单个partition里的数据是有序的,因为写的时候是顺序写入的,消费的时候也是按照记录的offset去消费的。但是多个partition里的数据是无序的。
如果要保证消费的有序性,那么可以
将需要顺序消费的数据通过自定义分区写到一个分区里,这样消费者消费的时候也就顺序的去消费,就有序了。
或者
将这个主题设置成一个partition,就不存在多分区无序的情况了,但是效率就降低了。
1.8.10 如何保证不重复消费
重复消费产生的原因
1.生产者重复生产生产者生产数据的时候,数据已经写入了kafka中,但是当ack的时候,发生了集群挂了、网络不好什么的故障,没有收到ack信息。
针对这种情况,kafka0.9开始提供了
幂等性特性。幂等性是指
接口的多次调用所产生的结果和只调用一次是一致的。Kafka内部会自动为每个Producer分配一个producer id(PID),broker端会为每个Topic的partition生产一个SequenceNumber。下次消息来了就知道kafka有没有写过了。
但是如果是在ack的时候生产者直接挂了,那么幂等性就不行了。因为重新启动生产者的时候,会为生产者生产一个新的PID。这种情况就要借助kafka的
事务性来解决了。
2.消费者重复消费消费者消费了数据,还没有提交offset,此时程序出问题挂了或者什么的,下次启动后就会重复消费刚刚这些数据。(自动提交一般是设置多长时间提交一次(100ms之类的),手动提交的话就是处理完业务数据后再提交)
这种情况的话,因为我们消费的数据一般是下沉到数据库,在那边重判重处理就好了,如果已经存了,那就丢弃不要存了。
1.8.11 如何保证不丢失数据
丢失数据的原因1.
生产者丢失数据这种情况就是ack配置了0,刚一send就返回发成功了,结果种种原因数据没有发成功。
可以把ack设置成1或者-1,1的话就是至少发到了一个分区上,-1的话是所有的副本都同步成功了。
2.
消费者丢失数据这种情况就是自动提交offset的问题了。数据只是从kafka里拿出来,但是还没有落到数据库里,那这时候提交了offset。
当数据真正处理完成后,再提交offset。
手动提交的时候,我们可以处理一条就提交一个offset+1。但是这样太影响性能。我们可以一次性处理30条,如果处理失败,就把处理之前的offset提交,如果处理成功,就把offset+30(
注意offset提交的是已消费数据的下一个offset位置)
1.8.12 如何保证消息的一致性
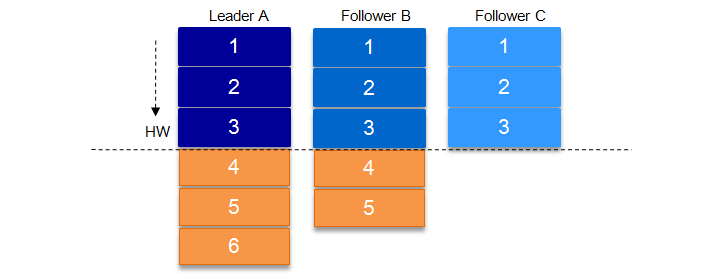
一个partition中的ISR列表中,leader的
HW是所有 ISR 列表里副本中最小的那个的 LEO。类似于木桶原理,水位取决于最低那块短板。
LEO,LogEndOffset 的缩写,表示每个 partition 的 log 最后一条 Message 的位置
HW俗称高水位,HighWatermark 的缩写,取一个 partition 对应的 ISR 中最小的 LEO 作为 HW,consumer 最多只能消费到 HW 所在的位置。
就是说,如果消费者消费到了5,这时候leader挂了,follower B成为leader,这时候去消费的时候,没有offset5,直接就报错了。所以HW就是保证不论消费那个副本的数据,都消费到的是一样的。
1.9 Spark
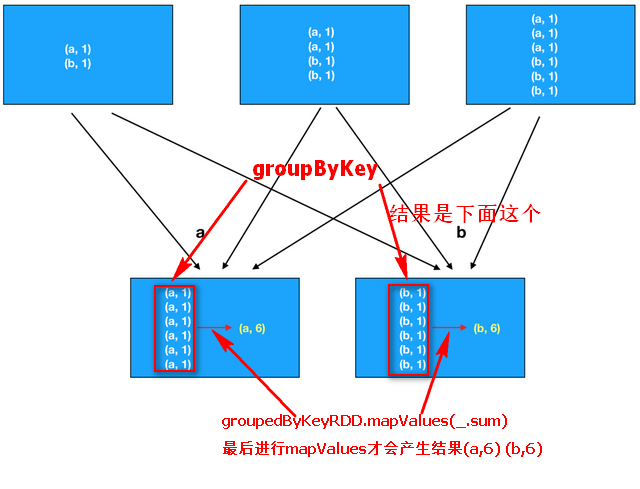
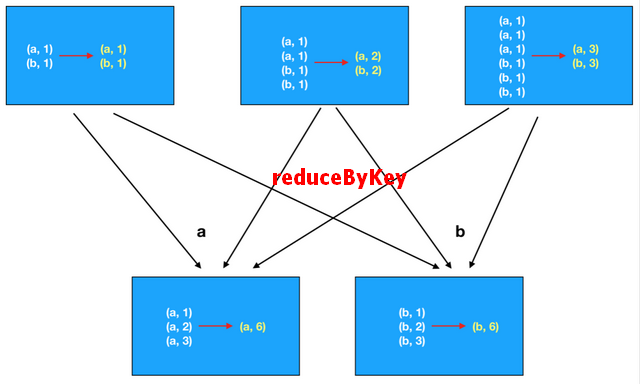
点击前往详细文档。1.9.1 ReduceByKey和GroupByKey
区别1:
reduceByKey代码简单一步搞定
区别2:
reduceByKey比groupByKey性能要好,因为ReduceByKey在map有预聚合操作
1.9.2 RDD中的算子分为哪几类
RDD中操作(函数、算子)分为两类:
1):
Transformation转换操作:返回一个新的RDD
所有Transformation函数都是Lazy,不会立即执行,需要Action函数触发2):
Action动作操作:返回值不是RDD(无返回值或返回其他的)
所有Action函数立即执行(Eager),比如count、first、collect、take等
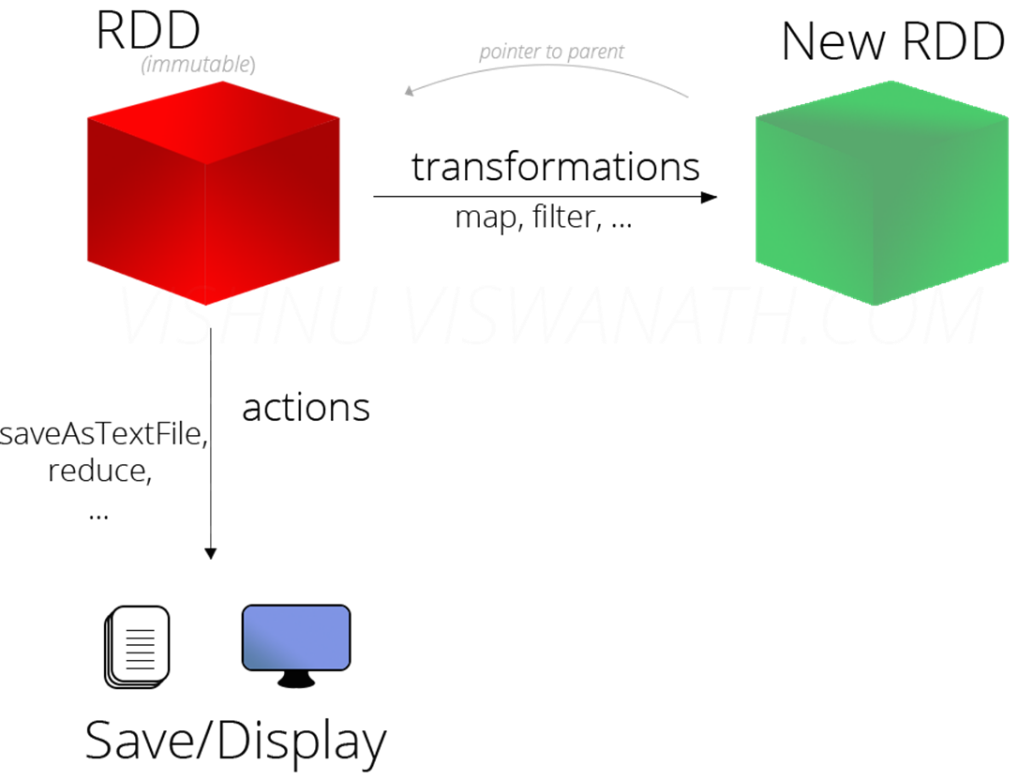
Spark中的RDD操作API/算子为什么要区分Transformation和Action?
1 | |
为什么要有懒执行/延迟执行和触发执行?
1 | |
1.9.3 map和mapPartitions,foreach和foreachPartition
map是对每个分区的每个数据操作
mapPartitions是对每个分区操作
1 | |
1 | |
1.9.4 Cache和RDD持久化和CheckPoint
在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
1.9.4.1 Cache
1 | |
1.9.4.2 RDD持久化
1 | |
1.9.4.3 持久化级别
| 持久化级别 | 说明 |
|---|---|
MEMORY_ONLY(默认) |
将RDD以非序列化的Java对象存储在JVM中。 如果没有足够的内存存储RDD,则某些分区将不会被缓存,每次需要时都会重新计算。 这是默认级别。 |
MEMORY_AND_DISK(开发中可以使用这个) |
将RDD以非序列化的Java对象存储在JVM中。如果数据在内存中放不下,则溢写到磁盘上.需要时则会从磁盘上读取 |
| MEMORY_ONLY_SER | |
| (Java and Scala) | 将RDD以序列化的Java对象(每个分区一个字节数组)的方式存储.这通常比非序列化对象(deserialized objects)更具空间效率,特别是在使用快速序列化的情况下,但是这种方式读取数据会消耗更多的CPU。 |
| MEMORY_AND_DISK_SER (Java and Scala) | 与MEMORY_ONLY_SER类似,但如果数据在内存中放不下,则溢写到磁盘上,而不是每次需要重新计算它们。 |
| DISK_ONLY | 将RDD分区存储在磁盘上。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2等 | 与上面的储存级别相同,只不过将持久化数据存为两份,备份每个分区存储在两个集群节点上。 |
| OFF_HEAP(实验中) | 与MEMORY_ONLY_SER类似,但将数据存储在堆外内存中。 (即不是直接存储在JVM内存中) 如:Tachyon-分布式内存存储系统、Alluxio - Open Source Memory Speed Virtual Distributed Storage |
如果MEMORY_ONLY策略无法存储所有的数据的化,使用MEMORY_ONLY_SER,将数据进行序列化存储,节约空间,纯内存操作速度块,只是需要消耗cpu进行反序列化
1.9.4.4 RDD CheckPoint
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
在Spark Core中对RDD做checkpoint,可以切断做checkpoint RDD的依赖关系,将RDD数据保存到可靠存储(如HDFS)以便数据恢复;
1 | |
1.9.4.5 持久化和CheckPoint的区别
1):存储位置Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存);
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上;
2):生命周期Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法;
Checkpoint的RDD在程序结束后依然存在,不会被删除;
3):Lineage(血统、依赖链、依赖关系)Persist和Cache,
不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来;
Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链;
结论:怎么用!实际开发对于计算复杂且后续会被频繁使用的RDD先进行缓存/持久化提高效率, 再使用Checkpoint保证数据觉得安全
1 | |
1.9.5 共享变量
1.9.5.1 广播变量 Broadcast Variables
就是说,不广播就是ApplicationMaster把数据发给各个Task,广播了就是发给子服务器,Task从服务器拿。
Spark中的广播变量也是将变量发送到各个Worker,然后各个Worker上的各个分区任务去各自的Worker上读取, 避免发给各个分区
广播变量是不可变的, 如果数据有变化需要重新广播,
广播变量的数据不能太大

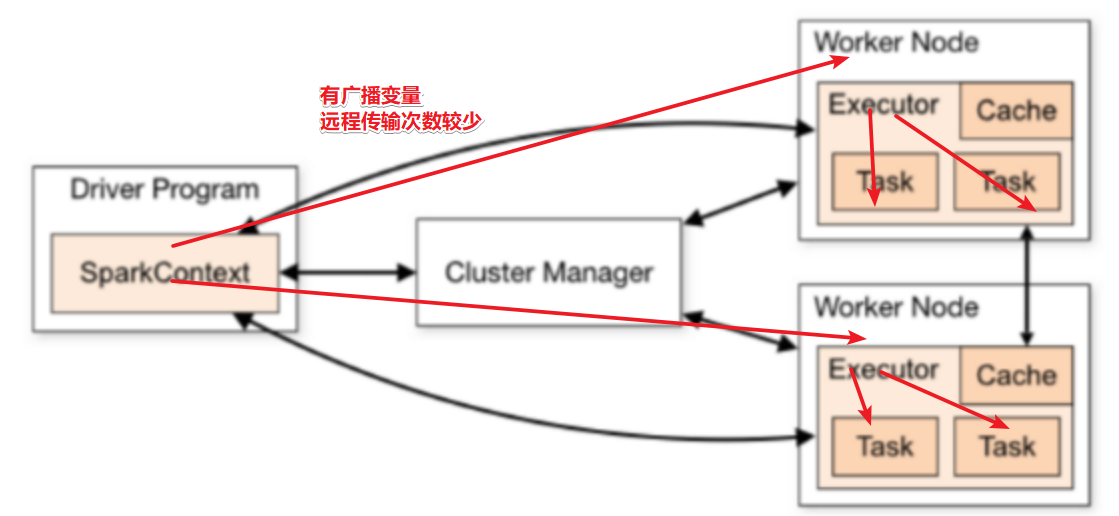
1.9.5.2 累加器
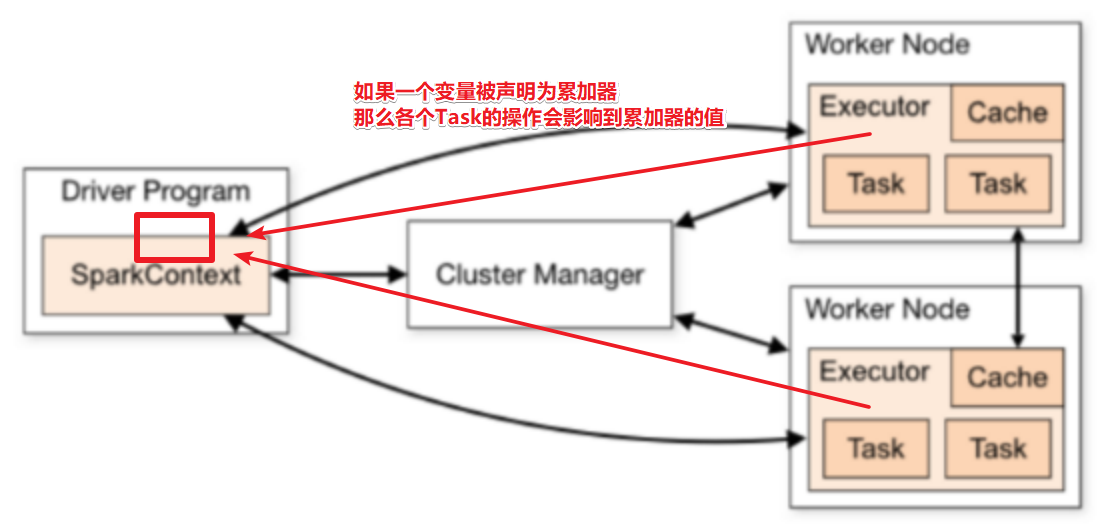
1.9.5.3 演示
1 | |
1.9.6 窄依赖和宽依赖
1.9.6.1 窄依赖
窄依赖中:即父 RDD 与子 RDD 间的分区是一对一的。换句话说父RDD中,一个分区内的数据是不能被分割的,只能由子RDD中的一个分区整个利用。
1.9.6.2 宽依赖
也叫Shuffle依赖。Shuffle 有“洗牌、搅乱”的意思,这里所谓的 Shuffle 依赖也会打乱原 RDD 结构的操作。具体来说,父 RDD 中的分区可能会被多个子 RDD 分区使用。因为父 RDD 中一个分区内的数据会被分割并发送给子 RDD 的所有分区,因此 Shuffle 依赖也意味着父 RDD与子 RDD 之间存在着 Shuffle 过程。
1.9.6.3 如何区分宽窄依赖
区分RDD之间的依赖为宽依赖还是窄依赖,主要在于父RDD分区数据与子RDD分区数据关系:
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖;
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖,涉及Shuffle;
1.9.7 Job、DAG、Stage、Task
一个Spark Application中,包含多个Job,每个Job执行按照DAG图进行的,每个Job有多个Stage组成,每个Stage由很多Task组成。
Job:由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect,后面进一步说明),会生成一个 Job。
DAG:一个Job会形成一个DAG图,DAG中包含一个或者多个Stage,根据是否shuffle划分的Stage。
Stage:Job 的组成单位,一个 Job 会切分成多个 Stage,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多个 Task 的集合,类似 map 和 reduce stage。
Task:被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一般来说有多少个 Paritition(物理层面的概念,即分支可以理解为将数据划分成不同部分并行处理),就会有多少个 Task,每个 Task 只会处理单一分支上的数据。
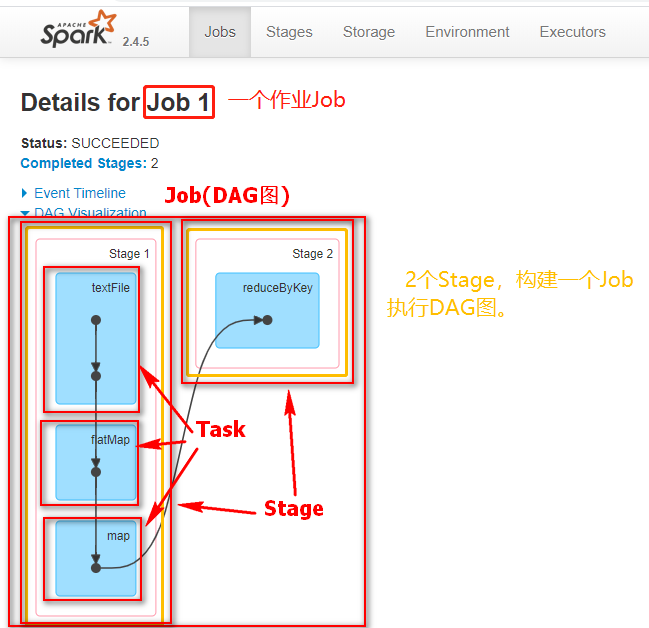
Spark中DAG生成过程的重点是对Stage的划分,其划分的依据是RDD的依赖关系,对于不同的依赖关系,高层调度器会进行不同的处理。对于窄依赖,RDD之间的数据不需要进行Shuffle,多个数据处理可以在同一台机器的内存中完成,所以窄依赖在Spark中被划分为同一个Stage;
对于宽依赖,由于Shuffle的存在,必须等到父RDD的Shuffle处理完成后,才能开始接下来的计算,所以会在此处进行Stage的切分。
1.9.8 基本概念
1 | |
1.9.9 Job调度流程
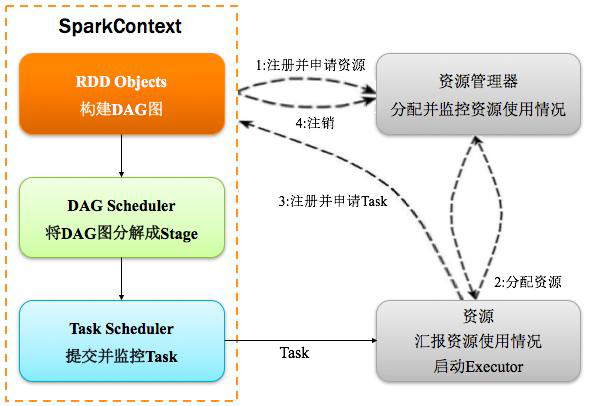
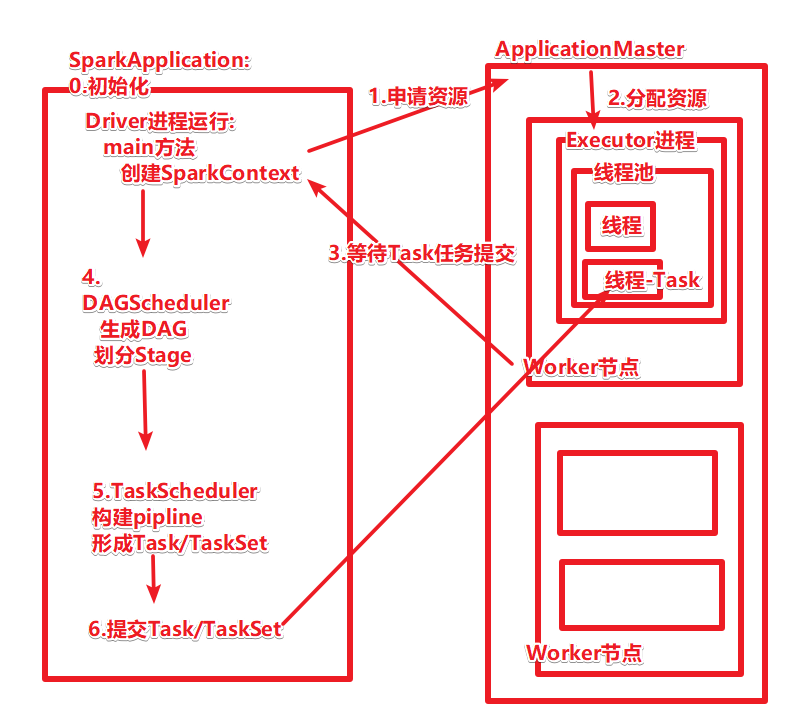
Spark运行基本流程1.当一个Spark应用被提交时,首先需要为这个Spark Application构建基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext(还会构建DAGScheduler和TaskScheduler)
2.SparkContext向资源管理器注册并申请运行Executor资源;
3.资源管理器为Executor分配资源并启动Executor进程,Executor运行情况将随着心跳发送到资源管理器上;
4.SparkContext根据RDD的依赖关系构建成DAG图,并提交给DAGScheduler进行解析划分成Stage,并把该Stage中的Task组成的Taskset发送给TaskScheduler。
5.TaskScheduler将Task发放给Executor运行,同时SparkContext将应用程序代码发放给Executor。
6.Executor将Task丢入到线程池中执行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
1.9.10 数据倾斜
我碰到的一个就是在map端的时候,由于同一个键被分到了不同分区,导致在reduce端的时候,同一个分区里有很多相同键需要计算。
我的解决方法是:
在map端,先对
数量很多但是分配到不同分区的键加随机前缀,然后进行reduce,这时候这些键就会分配到不同的分区里。
这样其实就是做了一次预聚合。然后我对他再取消掉前缀,再进行一次Reduce,这样基本就解决了这个问题。
1.9.11 水位线机制
在12:20触发执行窗口(12:10-12:20)数据中,
(12:08, dog)数据是延迟数据,阈值Threshold设定为10分钟,此时水位线【Watermark = 12:14 - 10m = 12:04】,因为12:14是上个窗口(12:05-12:15)中接收到的最大的事件时间,代表目标系统最后时刻的状态,由于12:08在12:04之后,因此被视为“虽然迟到但尚且可以接收”的数据而被更新到了结果表中
在12:25触发执行窗口(12:15-12:25)数据中,
(12:04, donkey)数据是延迟数据,上个窗口中接收到最大的事件时间为12:21,此时水位线【Watermark = 12:21 - 10m = 12:11】,而(12:04, donkey)比这个值还要早,说明它”太旧了”,所以不会被更新到结果表中了。
1.9.12 如何理解Spark中三种数据结构RDD、DataFrame和Dataset关系
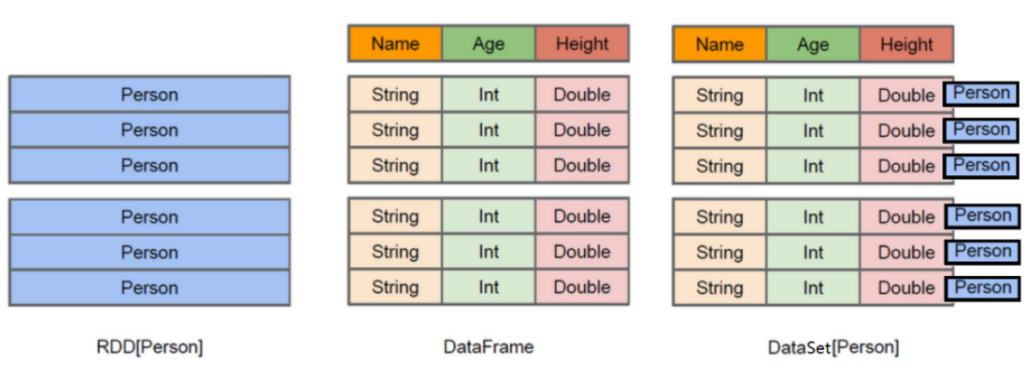
RDD(Resilient Distributed Datasets)叫做弹性分布式数据集,是Spark中最基本的数据抽象,源码中是一个抽象类,代表一个不可变、可分区、里面的元素可并行计算的集合。
与RDD类似,
DataFrame是一个分布式数据容器,不过它更像数据库中的二维表格,除了数据之外,还记录这数据的结构信息(即schema)。
Dataset是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。DataFrame=Dataset[Row](Row表示表结构信息的类型),DataFrame只知道字段,但是不知道字段类型,
而Dataset是强类型的,不仅仅知道字段,而且知道字段类型
1.10 Kudu
点击前往详细文档。1.10.1 Kudu的读写原理
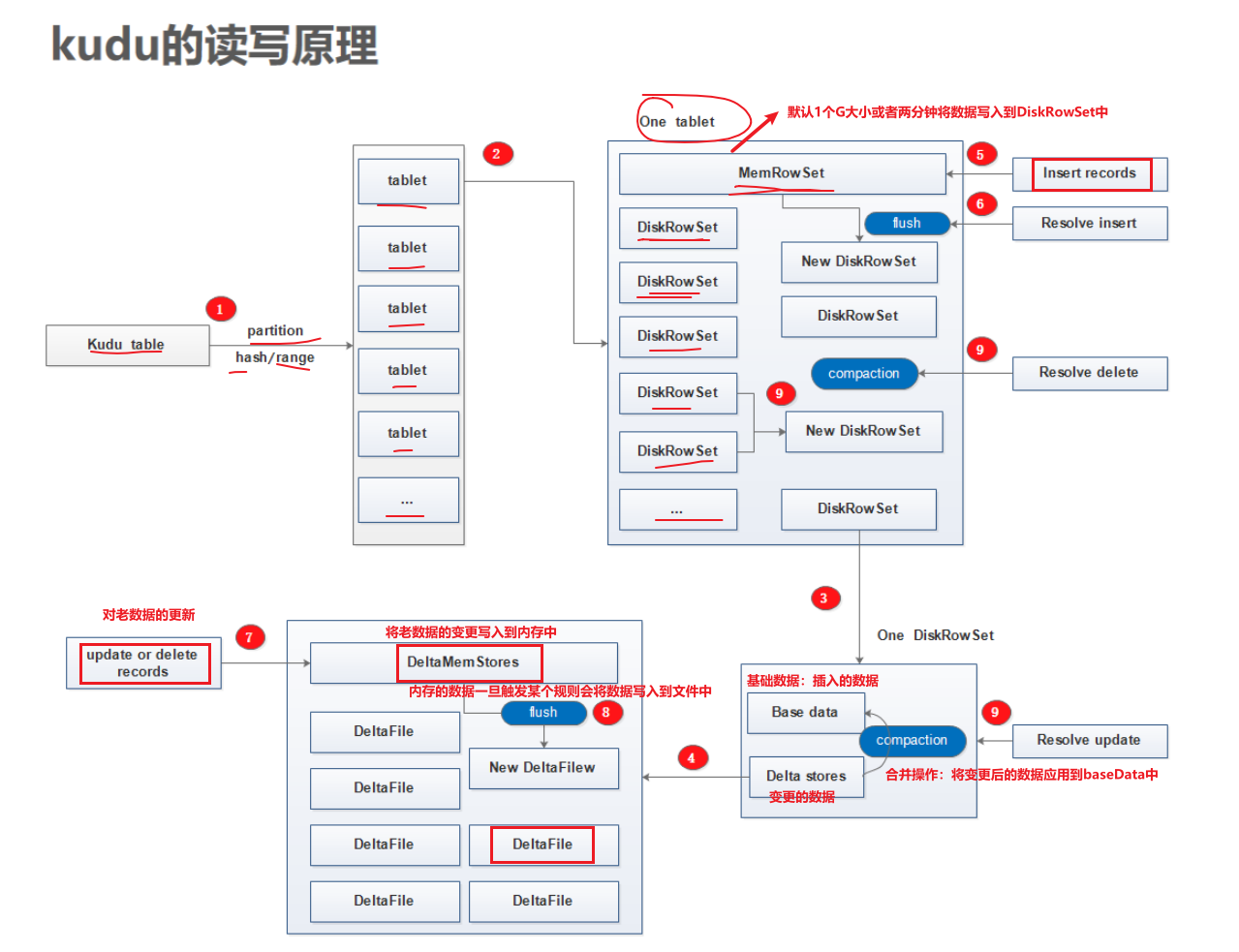
每个
kudu table按照hash或range分区为多个tablet;
每个
tablet中包含一个MemRowSet以及多个DiskRowSet;
每个
DiskRowSet包含BaseData以及DeltaStores;
DeltaStores由多个DeltaFile和一个DeltaMemStore组成;
1.10.2 插入数据
插入数据的时候,将数据放到
MemRowSet,然后默认1个G或者两分钟刷新到DiskRowSet
1.10.3 更新删除数据
更新删除的时候,找到对应的
tablet下的DiskRowSet,将变更的数据放到DiskRowSet里的DeltaStores中
将DiskRowSet下的BaseData和DeltaStores合并。如果删除数据,这个DiskRowSet不是就变小了嘛,可以进行DiskRowSet的合并操作
1.10.3 读取数据
Kudu Master根据主键过滤Tablet位置,请求Tablet Follower,根据主键定位DiskRowSet。
先找MemRowSet,没有的话找DiskRowSet
加载BaseData,并与DeltaStores合并,得到老数据的最新结果。
去上面刚刚合并的DiskRowSet找,没有就没有了
1.11 ClickHouse
点击前往详细文档。1.11.1 引擎
1.11.1.1 日志引擎
TinyLog引擎
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。
该引擎没有并发控制如果同时从表中读取和写入数据,则读取操作将抛出异常;
如果同时写入多个查询中的表,则数据将被破坏。
当拥有大量小表时,可能会导致性能低下。
不支持索引。
1.11.1.2 数据库引擎
MySQL引擎用于将远程的MySQL服务器中的表映射到ClickHouse中
但您无法对其执行以下操作:RENAME
CREATE TABLE
ALTER
1.11.1.3 MergeTree引擎(引擎)
1.11.1.3.1 MergeTree
MergeTree引擎的表的允许插入主键重复的数据,
主键主要作用是生成主键索引来提升查询效率,而不是用来保持记录主键唯一
1 | |
1.11.1.3.2 ReplacingMergeTree
为了解决MergeTree相同主键无法去重的问题,ClickHouse提供了ReplacingMergeTree引擎,用来对主键重复的数据进行去重。
1 | |
1.11.1.3.3 SummingMergeTree
ClickHouse通过SummingMergeTree来支持对主键列进行预聚合。在后台合并时,会将主键相同的多行进行sum求和,然后使用一行数据取而代之,从而大幅度降低存储空间占用,提升聚合计算性能。
1 | |
1.11.1.3.4 AggregatingMergeTree
AggregatingMergeTree也是预聚合引擎的一种,是在MergeTree的基础上针对聚合函数计算结果进行增量计算用于提升聚合计算的性能。
与SummingMergeTree的区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。
1 | |
1.11.1.3.5 CollapsingMergeTree
在ClickHouse中不支持对数据update和delete操作(不能使用标准的更新和删除语法操作CK),但在增量计算场景下,状态更新是一个常见的现象,此时update操作似乎更符合这种需求。
ClickHouse提供了一个
CollapsingMergeTree表引擎,它继承于MergeTree引擎,是通过一种变通的方式来实现状态的更新。
CollapsingMergeTree表引擎需要的建表语句与MergeTree引擎基本一致,惟一的区别是需要指定Sign列(必须是Int8类型)。这个Sign列有1和-1两个值,1表示为状态行,当需要新增一个状态时,需要将insert语句中的Sign列值设为1;-1表示为取消行,当需要删除一个状态时,需要将insert语句中的Sign列值设为-1。
这其实是插入了两行除Sign列值不同,但其他列值均相同的数据。因为有了Sign列的存在,当触发后台合并时,会找到存在状态行与取消行对应的数据,然后进行折叠操作,
也就是同时删除了这两行数据。
就是更新数据的时候是插入两行数据,一行和原数据一样,状态行标记-1。一行是新数据。这样一折叠,就把两条旧数据删了。删除的话就是只插入一条与原数据相同但状态行不一样的数据,一折叠,两条就都消失了
1 | |
1.11.1.3.6 VersionedCollapsingMergeTree
VersionedCollapsingMergeTree 用于相同的目的 折叠树,但使用不同的折叠算法,允许以多个线程的任何顺序插入数据。 特别是, Version 列有助于正确折叠行,即使它们以错误的顺序插入。
相比之下, CollapsingMergeTree 只允许严格连续插入。
1 | |
1.12 Flink
1.12.1 window
Watermark经常和Window一起被用来处理乱序事件。
1.12.2 watermark
1.12.3 checkpoint
1.12.4 state
1.12.5 exactly-once
1.12.6 CEP
1.12.7 分布式快照
1.12.8 重启策略
1.12.9 广播变量
1.12.10 Flink中的Window出现了数据倾斜,你有什么解决办法?
1.12.11 三种时间语义
2 Java
2.1 JVM
点击前往详细文档2.2 HashMap
点击前往详细文档2.3 多线程
点击前往详细文档2.4 分布式锁
2.5 分布式事务
3 MySQL
点击前往详细文档4 Scala
4.1 隐式转换是什么?怎么自己写一个隐式转换给别人用?
4.2 class和case class的区别
关注博主不迷路
本博客所有文章除特别声明外,均为原创。版权归博主小马所有。任何团体、机构、媒体、网站、公众号及个人不得转载。如需转载,请联系博主(关于页面)。如其他团体、机构、媒体、网站、博客或个人未经博主允许擅自转载使用,请自负版权等法律责任!